本文出自论文:AMC: AutoML for Model Compression and Acceleration on Mobile Devices,提出了针对模型压缩的AutoML,利用强化学习方法来采样设计空间,极大地提高了模型压缩质量。
模型压缩是一种有效的技术,可以在计算资源受限和能耗预算紧张的移动设备上有效部署神经网络模型。传统的模型压缩技术依赖于手动选择特征和要求领域专家探索大的设计空间,保证模型大小、速度和精度之间的权衡,这种方法通常是次优的和消耗时间的。本文,我们提出了针对模型压缩的AutoML,称为AMC,它利用强化学习方法来有效地采样设计空间,能够提高模型压缩质量。我们在没有人力作用的情况下,以一种完全自动化的方式获得了先进的模型压缩效果。在4倍浮点数计算量减少的情况下,在ImageNet上的VGG-16模型下,我们获得了比手动调整模型压缩方法更好的2.7%精度提升。我们应用这个自动化方法到MobileNet-V1下,然后获得了GPU下1.53倍的加速,和Android手机下1.95倍的加速,并且几乎无精度损失。
一、简介
- 模型压缩技术的核心是当每一层有不同的冗余时来决定它们的压缩策略,传统方法是手动探索大的设计空间来保证模型大小、加速和精度之间的权衡。这个设计空间如此大以致于人工启发式通常是次优的和耗时的,为此我们旨在为一个随机网络自动化地找到压缩策略,从而获得比人工策略更好的性能。
- 我们发现压缩模型的精度对于每一层的稀疏度非常敏感,要求一个细粒度的动作空间。因此,我们提出来一个连续的压缩比控制策略,使用一个DDPG代理通过尝试和误差去学习(惩罚精度损失,同时鼓励模型收缩和加速),而不是在离散空间中搜索。这个actor-critic结构也有助于减少差异,有利于稳定的训练。特别地,DDPG代理使用一种layer-wise的方式来处理网络,对于每一层
,代理接收到一个层嵌入
来对层的有用特征进行编码,然后它输出一个明确的压缩比
。在层
使用
被压缩后,代理移动到下一层
。所有压缩层的剪枝模型的验证精度在没有微调的情况下进行评估,这是微调精度的一个有效代表。这个简单的近似方式可以提高搜索时间,而不必要对模型进行再训练,并提供高质量搜索结果。在策略搜索过程结束后,最好的探索模型被进行微调来获得最好的性能。
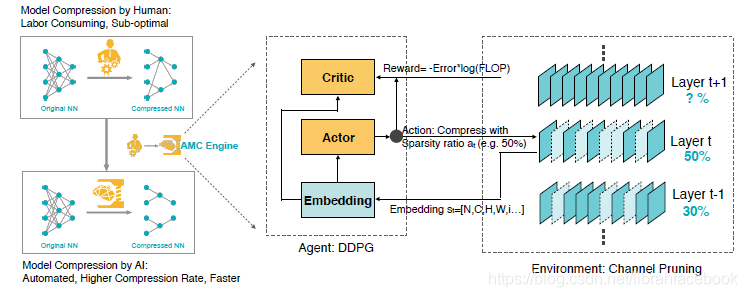
- 我们针对不同的情形提出了两种压缩策略搜索协议。对于延迟关键型AI应用程序(手机APP、自动驾驶汽车和广告排名),我们提出了资源受限压缩方式,在给定最大数量的硬件资源(浮点数、延迟和模型大小)下来获得最好的精度。对于质量关键型AI应用程序(Google Photos),该类程序的延迟并不是一个硬性约束,我们提出来一个精度保证压缩方式,在无精度损失情况下获得最小的模型。对于前一种方式,我们限制了搜索空间,其动作空间(修剪比例)被限制,从而使代理下的压缩模型总是在资源预算下。对于后一种方式,我们定义了一个关于精度和硬件资源的奖励函数,在不伤害模型精度的情况下能够探索压缩限制。
二、相关工作
- CNN压缩和加速:压缩、量化和特殊的卷积实现可以加速神经网络。张量分解将权重分解成权重较轻的部分,例如使用缩短的SVD方法来加速全连接层。通道剪枝从特征映射中移除冗余的通道。这些方法的常见问题是如何决定每一层的稀疏比例。
- 神经架构搜索和AutoML:NAS旨在搜索可迁移网络块,并且它的性能胜过许多人工设计的结构,N2N将强化学习方法融合到通道选择中。与先前的工作比较,AMC方法优化了延迟和精度,要求一个简单的非RNN控制器,可以使用较少的GPU时间来做快速探索,同时也支持连续的动作空间。
三、方法
-
我们训练了一个强化学习代理来预测动作并给出稀疏性,然后执行剪枝过程。我们在剪枝后和微调前来对其精度进行评估,从而作为一个最终精度的有效表示。最后我们通过鼓励更小的、更快的和更精确的模型来更新代理。
-
问题定义:模型压缩通过减少深度神经网络每一层的参数和计算量来实现。这里有两种修剪策略:细粒度修剪和结构化修剪。细粒度修剪旨在剪去权重张量中的不重要的单个元素,但会导致不规则的稀疏样式。粗粒度结构化修剪旨在剪去权重张量中的整个规则区域。这里我们研究结构化修剪方法,收缩每个卷积层和全连接层的输入通道。对于一个权重张量( ),n,c是输出和输入通道数,k是核大小。对于细粒度修剪,稀疏度定义为0元素数量与所有元素数量的比,表示为 ,对于通道修剪,我们收缩其权重张量为 ,其稀疏度表示为 。
-
使用强化学习方法的自动压缩:
(1)状态空间:对于每层 ,我们有着11个特征来表示状态 ,其中Reduced是先前层减少的浮点数的总数量,Rest是下一层的剩余浮点数的总数量。
(2)动作空间:我们提出使用连续的动作空间 ,支持更细粒度的和更精确的压缩。
(3)DDPG代理:对于连续控制压缩比例,我们使用深度决策策略梯度(DDPG),它是一个离线策略的actor-critic算法。对于探索的噪声处理,我们使用缩短的正态分布: 。在探索过程中,噪声 被初始化为0.5,并且在每次过程后呈指数式衰减。在一个过程的每个转换公式为 ,其中R是网络被压缩后的奖励。在更新期间,基础奖励b被减去来减少梯度估计的方差,这是先前奖励的一个指数式移动平均。损失函数被定义为:
折扣因子 被设置为1,从而避免过度优先短期奖励。 -
搜索协议:
扫描二维码关注公众号,回复: 10543463 查看本文章
(1)资源受限型压缩:通过限制动作空间(每层的稀疏比),我们可以精确地到达目标压缩比。我们使用以下的奖励: ,这个奖励并没有提供模型大小减少的激励,因此我们可以通过限制动作空间来达到目标压缩比。算法1描述了该过程:在最开始几层我们允许任意的动作a,然后当我们发现预算不满足时即使使用最激进的策略压缩完接下来所有的层后,我们开始限制动作a。我们的算法并没有限制于约束模型大小,并且它可以被其他资源所替代,比如浮点数或者在移动设备上的实际推理时间。由于代理没有接收到预算下的激励,它可以精确地达到目标的压缩比。
(2)精度保证型压缩:通过调整奖励函数,我们可以精确地发现压缩的极限而无精度损失。由于误差与log(浮点数)或者log(参数)成反比例关系,我们设计出下面的奖励函数:
这个奖励函数对误差更敏感,与此同时,它提供了一个对于减少浮点数或模型大小的小的激励。我们的代理可以自动化地找到压缩的极限。

四、实验结果
-
对于细粒度剪枝,我们使用最小的量级来修剪权重。卷积层最大的稀疏比 被设置为0.8,全连接层的 被设置为0.98。对于通道剪枝,我们使用最大响应选择(根据量级修剪权重),然后在修剪过程中保持批正则化层,而不是将它们融合到卷积层中。所有层的最大稀疏比 被设置为0.8。actor网络 有两个隐藏层,每个有300个单元,最终的输出层是一个sigmoid层来将动作空间归一化。critic网络 也有两个隐藏层,各有300个单元,其动作包含在第二个隐藏层中。我们使用 来作为软目标更新,使用64作为批大小来训练网络,2000作为replay缓冲区大小。我们的代理首先使用一个固定的噪声 来探索100个过程,然后使用指数式衰减噪声 接着探索300个过程。
-
CIFAR-10和分析:
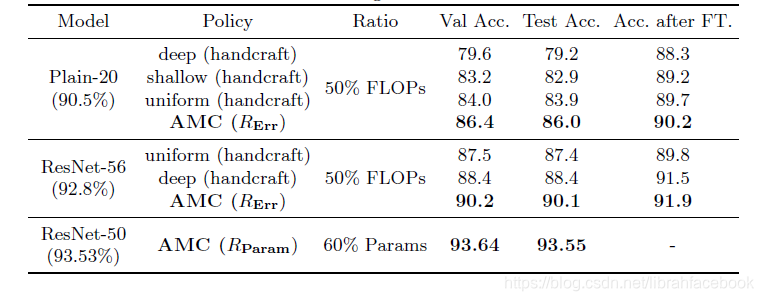
(1)浮点数受限型压缩:我们使用通道剪枝方法在CIFAR-10上进行处理,基于不同网络的稀疏度分布,一个不同的策略可能被选择好。AMC方法发现的最佳剪枝设置与手动启发式方法有所不同,它学习到一个瓶颈架构。
(2)精度保证型压缩:通过使用 奖励,我们的代理可以使用最小的模型大小和略微的性能损失,来自动化找到压缩极限。我们在CIFAR-10上使用细粒度剪枝来压缩ResNet-50,在验证集和测试集上的结果为60%的压缩比,甚至有一点精度提升,这可能与剪枝的正则化效果有关。由于我们的奖励 集中于Error,并提供了对压缩非常少的激励,它更偏重于无害压缩的高质量模型。同时为了缩短搜索时间,我们使用了无微调的验证精度来获得奖励。
(3)加速策略探索:获得较高验证精度的策略相应的也有较高的微调精度,这支持我们去预测没有微调的最终模型精度,导致一个有效的和更快的策略探索。我们仅使用验证集在强化学习过程中去生成奖励。另外,压缩过的模型有着较少的参数,测试精度和验证精度非常接近,意味着没有过拟合现象。
-
ImageNet:
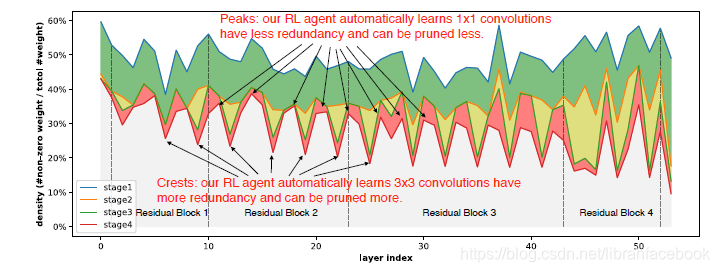
(1)推动细粒度剪枝的极限:它要求迭代式剪枝和微调过程来获得很好的性能,并且无重训练的single-shot剪枝将会伤害有着大的压缩比的预测精度,这导致难以提供对强化学习代理有用的监督。使用AMC框架,我们可以在ImageNet数据集上推出专业调整的ResNet-50压缩比,它从3.4倍到5倍,并且没有性能上的损失。从实验结果图上可以发现,RL代理可以自动地学习去修剪有着较大稀疏比的3*3卷积层,因为它们通常有着较大的冗余;同时修剪更多有着较少稀疏比的紧缩1*1卷积层。我们也可以发现AMC的密度分布非常不同于人类专家的结果,显示着AMC可以完全探索设计空间,并以一种更好的方式来分配稀疏度。
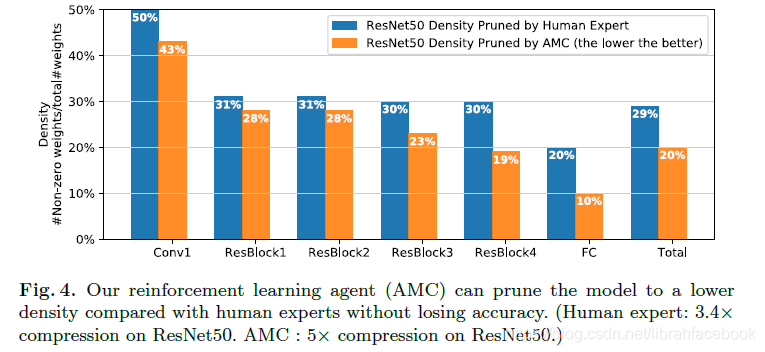
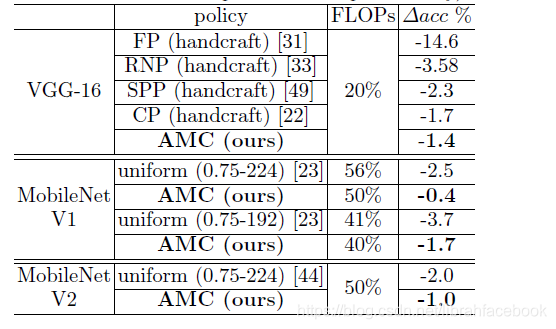
(2)与启发式通道减少的比较:我们将AMC方法与现有的最先进的通道减少方法(FP,RNP和SPP)进行比较,所有的方法都提出了一个启发式策略来设计每层的剪枝比例。与CIFAR-10实验结果一致,AMC方法胜过所有的启发式方法超过0.9%,并且在无人力的情况下优于人类专家0.3%。对于MobileNet-V1和MobileNet-V2模型,由于它们已经非常紧缩导致很难再去压缩,我们使用统一的通道紧缩方案来减少模型的通道数,例如使用一个宽度乘法器以固定比例均匀地减少每一层的通道数。即使对于目前最先进的有效模型设计MobileNet-V2,AMC仍然可以在相同计算量的前提下提高其精度为1.0%。
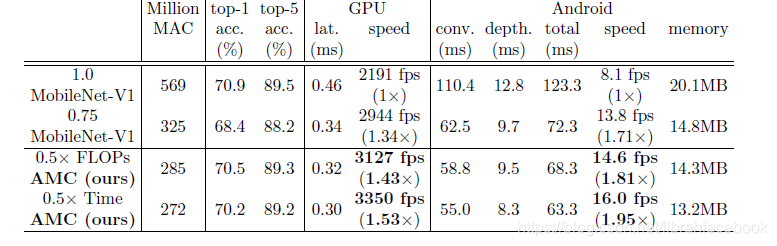
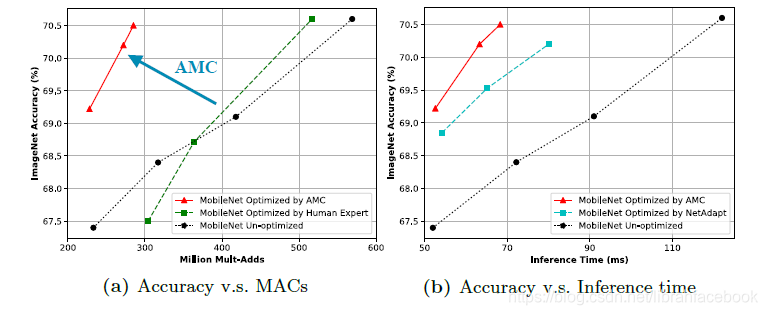
(3)移动推理加速:AMC不仅可以优化浮点数和模型大小,它也可以优化推理延迟,直接有利于移动开发者。对于所有移动推理实验,我们使用TensorFLow Lite框架来进行时间评估。我们修剪MobileNet-V1,一个由深度卷积和点卷积层组成的高度紧缩网络,然后衡量我们可以提高其推理速度有多少。使用AMC方法,我们显著地提高了pareto曲线,提高了原始MobileNet-V1的accuracy-MACs权衡。通过用延迟来代替浮点数,我们可以将浮点数受限型策略改变为延迟受限型策略,并且可以直接优化推理时间。进一步来说,由于AMC使用微调前的验证精度作为奖励信号,所以它的采样效率更高,要求较少的GPU时间来做策略搜索。
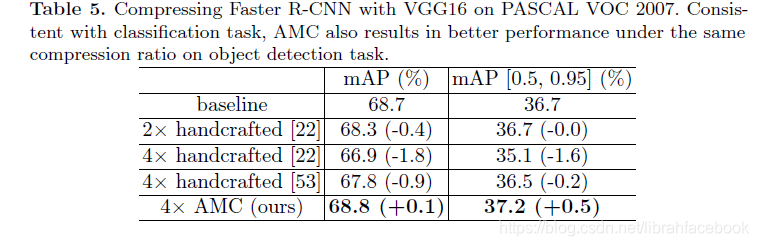
(4)普遍性:我们在PASCAL VOC目标检测任务上评估了AMC的普遍能力,使用压缩的VGG-16来作为Faster R-CNN的骨干。与分类任务一致,AMC也在目标检测任务上产生了相同压缩比下的更好性能。
五、结论
在本文中,我们提出了针对模型压缩的AutoML(AMC),利用强化学习方法来自动搜索设计空间,极大地提高了模型压缩质量。我们也设计出了两种最新的奖励方法来执行资源受限型压缩和精度保证型压缩。我们在CIFAR-10和ImageNet上针对ResNet、VGGNet、MobileNet-V1和MobileNet-V2上证实出AMC的良好性能,压缩模型从分类到检测任务上都很好地适用。总而言之,AMC为移动设备上的深度神经网络设计提供了很好的便利。
