TensorFlow线性回归案例
通过一个案例来讲述如何使用tensorflow来做线性回归
什么是线性回归
线性回归的公式:
1个特征:y=w*x+b,x是输入,y是输出,w是权重,b是偏置
n个特征:y=w1*x1+w2*x2......+wn*xn+b,有n个权重,1个偏置
线性回归的核心:
- 算法:线性回归
- 策略:均方误差
- 优化:梯度下降,需要置学习率
线性回归的使用步骤
1. 准备好特征值和目标值,也就是数据,特征值是输入,目标值是输出,以预测房价为例,
位置,面积,朝向等都是特征值,房总价是目标值。
2.建立模型,需要一个权重,一个偏置,然后在随机初始化,得到一个预测函数y_predict.
3.求损失函数,也就是误差,这里用的是均方误差。
4.优化损失,在线性回归中,我们通过梯度下降的方式来优化损失,求损失函数最小值,
形象化得说法就是,给定一个随机点,从山上找到山底的一个过程,如下图所示。
说明:什么是均方误差?
就是对预测值和目标值求差并开根号,然后求平均值,公式如下:
[(y1-y1')^2+....+(yn-yn')^2]/n
核心api
梯度下降优化api:tf.train.GradientDescentOptimizer(learning_rate)
参数说明:
learning_rate:学习率,一般为0.1、0.01、0.001等量级的,当然也可以是1,10,100,但是基本不会这么写。
函数返回的是一个梯度下降op,我们可以在会话中进行。
核心代码
1 import tensorflow as tf
2 import os
3
4
5 def mymigration():
6 """
7 自实现一个线性回归预测
8 :return:
9 """
10 #1. 准备数据,这里我们通过一个公式来模拟数据,如果是真是数据,我们可以读取外部数据
11 x = tf.random_normal([100,1],mean=0.0,stddev=1.0)
12 #矩阵相乘必须是二维的
13 y_true = tf.matmul(x,[[0.7]]) + 0.8
14
15
16 #2.建立一个线性回归模型,1个权重,1个偏置,y=w*x+b
17 #随机给一个权重和偏置,让他去计算损失,也就是相当于梯度下降的起点
18 #在这里,我们的weight和bias是需要去优化的,他是变化的,必须使用tf.Variable去定义
19 #在定义的过程中,我们可以通过设置台trainable=False来限制某个变量不随梯度下降进行进行优化,默认是True
20 weight = tf.Variable(tf.random_normal([1,1], mean=0.0,stddev=1.0 , name='w'))
21 bias = tf.Variable(0.0,name='b')
22 y_prerdict = tf.matmul(x,weight)+bias
23
24
25 #建立损失函数,均方误差,tf.square求误差,reduce_mean求平均值
26 loss = tf.reduce_mean(tf.square(y_true-y_prerdict))
27
28
29 #梯度下降优化损失,学习率是0.1。
30 train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
31
32
33 #定义一个初始化变量的op
34 init_op = tf.global_variables_initializer()
35 #通过会话来运行程序
36 with tf.Session() as sess:
37 #初始化变量
38 sess.run(init_op)
39 #运行优化200次,也就是run op 200次
40 for i in range(200):
41 sess.run(train_op)
42 print('第%d次优化的权重和偏置:权重为:%f,偏置为:%f'%(i,weight.eval(),bias.eval()))
43 return None
44 if __name__ == "__main__":
45 mymigration( )
运行结果如下所示:
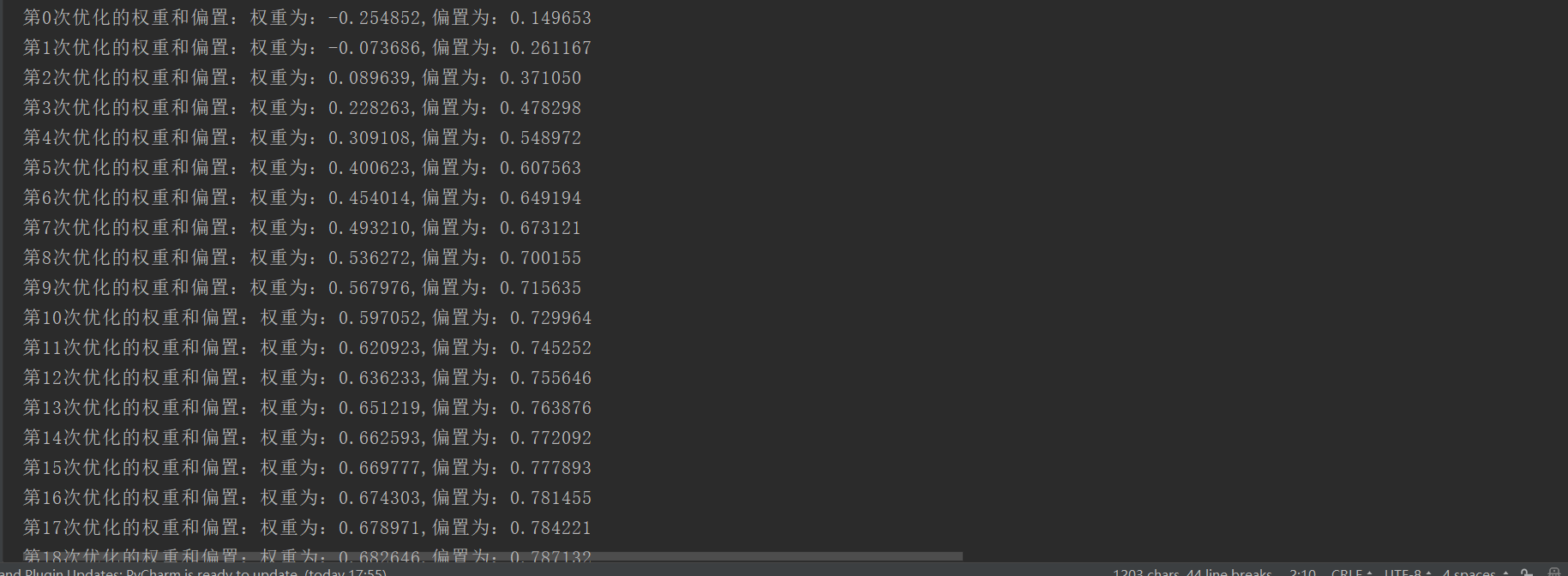
因为没有数据,我通过公式y_true = tf.matmul ( x, [ [ 0.7 ] ] ) + 0.8 来随机样本数据
实际中,我们可以通过读取外部是数据,训练并构建模型
通过200词次的训练,我们最后打得到的权重为0.7,0.8,训练的模型比较贴合数据,可以直接和模拟数据的
公式比较,如果我们是导入外部数据的话,是不知道训练的模型好坏的,我们需要不断的优化提高模型的准
确率。
学习率
learn__rate在梯度下降中是一个十分重要的参数,他决定从山顶到达山底的step和速度,一般都很小,0.1,
0.01,0.001等等都有。
learn_rate过大过小都不好,过大的话可能会导致梯度爆炸,过小会达不到想要的训练效果,需要增加训练次数
补充说明:
梯度爆炸:在极端的情况下,权重的值变得非常大,以至于溢出,导致NAN值但就是梯度爆炸,梯度爆炸的问题在学习
深度神经网络RNN中更容易出现。
如何解决梯度爆炸:(1):重新设计网络,(2)调整学习率, (3)使用梯度截断,在训练的过程中检查和限制梯度的
大小;(4)使用激活函数