逻辑回归实现鸢尾花分类
小白的第一篇文章,希望是一个好的开始
1.逻辑回归
数学形式如下:
从分类的角度来看,逻辑函数最重要的特点之一是不论参数z的值为多少,其输出值总是介于0到1之间。因此,该函数将整个实轴压缩到了区间[0,1]内。逻辑函数也称作S型函数(sigmoid function),可以运行以下几行代码来看一下。
画个图看一看
%matplotlib inline # 在jupyter notebook中要添加
import matplotlib.pyplot as plt
import numpy as np
z = np.linspace(-10,10,100) # 构造序列
logistic = 1 /(1+np.exp(-z))
plt.plot(z,logistic)
plt.xlabel('$z$',fontsize = 18) # fontsize确定标签的大小
plt.ylabel('$logistic(z)$',fontsize = 18)
plt.show()

2.逻辑回归进行花的分类
(1)数据探索与预处理
import seaborn as sns
iris = sns.load_dataset('iris') #直接导入iris数据集
print(iris.head(5))

import seaborn as sns
sns.pairplot(iris,hue = 'species') # hue 参数表示使用指定变量为分类变量,进行画

直观上可以看出,蓝色点代表的鸢尾花可以很好地被区分,绿色和橙色的点所代表的花很难被区分
表示类别的标签‘species’为字符串格式,在数据处理时需要进行整数编码,这样计算机才能很好地识别把。将蓝色编为0,绿色编为1,橙色编为2,代码如下:
class_dict = {"setosa":0, "versicolor":1, "virginica":2}
iris["Class"] = iris["species"].map(class_dict)
print(iris.head(5))
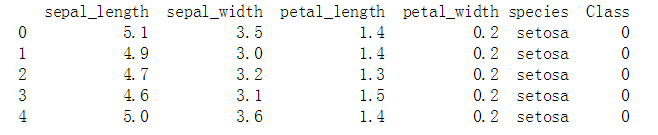
通过增加Class这一列,将其作为我们最后的label就是很完美的了。
iris['Class'].value_counts()

150个样本中,三个种类的鸢尾花各占1/3,均为50个样本。 下面我们需要将数据分为训练集和测试集,训练集用于训练分类器,测试集用于评估分类器性能。 假设我们将数据分成两部分:70%的训练集和30%的测试集。 在原始数据集中三种花的比例为1:1:1,我们应该尽量使得训练集和测试集中三种花的比例也满足1:1:1。 在解决类别分布不均衡的问题时,需要格外注意这一点。 在Sklearn的model_selection模块实现了一个train_test_split函数,能够方便地让我们实现上述划分。
(2)模型训练
从Sklearn的model_selection模块调用train_test_split函数
from sklearn.model_selection import train_test_split
X = iris[["sepal_length","sepal_width","petal_length","petal_width"]]
Y = iris["Class"] # 作为样本的label
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=42,stratify=Y)
# stratify参数设置成预测变量,则表示按照Class的取值比例来进行数据划分。
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(C = 1e3 , solver = 'lbfgs')
classifier.fit(X_train,Y_train)
- 调用sklearn.linear_model包中的相关类来构建基于逻辑回归的鸢尾属花亚种分类模型,在sklearn.linear_model包中,主要用到类sklearn.linear_model.LogisticRegression
- C: 默认值为1,数据类型为float,C值越大,正则化程度越弱
- penalty: 默认值为’l2’,取值范围为{‘l1’,‘l2’},newton-cg 和 lbfgs 算法只支持 l2 正则化
- solver: 默认值为’liblinear’,取值范围为{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’},该参数表示选择的优化算法名称。对于小数据集,'liblinear’效果较’sag’好
- multi_class: 默认值为’ovr’,表示将一个类的样例作为正例,其它类的样例作为反例,来训练多个分类器;‘multinomial’表示最小化多项式损失满足整个概率分布,只适用于’lbfgs’
- 通过Sklearn的LogisticRegression类创建分类器,其中C取1e3,solver=‘lbfgs’。
(3)性能评估
思路:使用predict()函数得到上一节训练的鸢尾属花亚种分类模型在测试集合上的预测结果,然后使用 sklearn.metrics中的相关函数对模型的性能进行评估。
from sklearn import metrics
predict_y = classifier.predict(X_test)
print(metrics.classification_report(Y_test,predict_y))
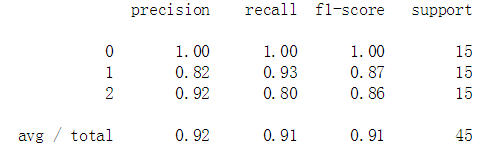
上面的矩阵反映了在测试集中对不同类别的花分类的精度、召回率、F1值
- 混淆矩阵
通过混淆矩阵来观察预测分类和实际分类情况。一般来说好的模型的混淆矩阵对角线元素值明显大于非对角线元素值。我们用调用seaborn画出此混淆矩阵的热点图。
import seaborn as sns
colormetrics = metrics.confusion_matrix(Y_test,predict_y)
sns.heatmap(colormetrics,annot = True,fmt = 'd')
# annot 为True时,将数据值写入每个单元格中
#fmt 规定表格中呈现数据值的类型

通过混淆矩阵发现,在四个样本上分类错误。其中三个样本真实类别是2(Iris-virginica,维吉尼亚鸢尾),而我们的分类器将其分类成1(Iris-versicolor,变色鸢尾)。一个样本真实类别是1,分类器将其分类成2。
(4)模型系数
import pandas as pd
coef_df = pd.DataFrame(classifier.coef_, columns=iris.columns[0:4])
coef_df["intercept"] = classifier.intercept_
coef_df.round(2)
# 通过coef 获取系数
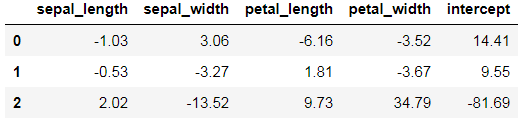
最终获得截距以及各项的系数。