其中的数据结构都是数组加链表组成,key为数组,value为链表
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。上面我们提到过,常用的哈希函数的冲突解决办法中有一种方法叫做链地址法,其实就是将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组。
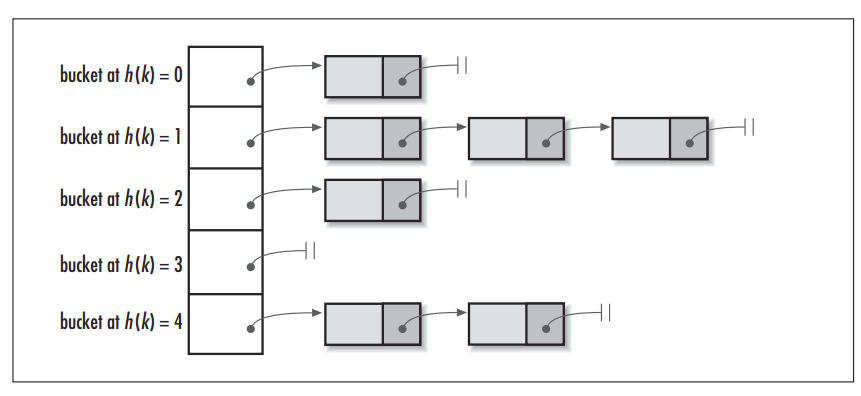
我们可以从上图看到,左边很明显是个数组,数组的每个成员是一个链表。该数据结构所容纳的所有元素均包含一个指针,用于元素间的链接。我们根据元素的自身特征把元素分配到不同的链表中去,反过来我们也正是通过这些特征找到正确的链表,再从链表中找出正确的元素。其中,根据元素特征计算元素数组下标的方法就是哈希算法,即本文的主角hash()函数(当然,还包括indexOf()函数)。
通过元素特征计算数组下标:hash()
HashMap的数组是有长度的,Java中规定这个长度只能是2的倍数,初始值为16。
求哈希简单的做法是先求取出键值的hashcode,通过调用object的hashCode(),然后在将hashcode得到的int值对数组长度进行取模。为了考虑性能,Java总采用按位与操作实现取模操作。
ConcurrentHashMap则是继承自HashMap的,常用于线程安全,性能强于HashMap
总结
-
HashMap默认的初始化大小为16,之后每次扩充为原来的2倍。
-
HashTable默认的初始大小为11,之后每次扩充为原来的2n+1。
-
当哈希表的大小为素数时,简单的取模哈希的结果会更加均匀,所以单从这一点上看,HashTable的哈希表大小选择,似乎更高明些。因为hash结果越分散效果越好。
-
在取模计算时,如果模数是2的幂,那么我们可以直接使用位运算来得到结果,效率要大大高于做除法。所以从hash计算的效率上,又是HashMap更胜一筹。
-
但是,HashMap为了提高效率使用位运算代替哈希,这又引入了哈希分布不均匀的问题,所以HashMap为解决这问题,又对hash算法做了一些改进,进行了扰动计算(将高位和地低位进行组合,确保数值中的每一位都参与了运算,不会出现高位不同,低位不同然后位运算出现哈希碰撞的现象)。
- Hashmap是允许key和value为null值的,用containsValue和containsKey方法判断是否包含对应键值对;HashTable键值对都不能为空,否则包空指针异常。
- HashMap继承自AbstractMap类。但二者都实现了Map接口。
Hashtable继承自Dictionary类,Dictionary类是一个已经被废弃的类(见其源码中的注释)。父类都被废弃,自然而然也没人用它的子类Hashtable了。 - Hashtable线程安全的,HashMap线程不安全的
- 解决冲突方式在jdk1.8不一样了
-
1.如果冲突数量小于8,则是以链表方式解决冲突。
2.而当冲突大于等于8时,就会将冲突的Entry转换为**红黑树进行存储。**
3.而又当数量小于6时,则又转化为链表存储。 - 而在HashTable中, 都是以链表方式存储。
-