一、启动thrift服务
启动thriftServer,默认端口为10000,。
--jars 添加worker类库
--driver-class-path 驱动类库
--master spark集群地址
--hiveconf hive.server2.thrift.port 启动端口
spark-2.4.4/sbin/start-thriftserver.sh --master spark://hadoop01:7077,hadoop02:7077,hadoop03:7077 --driver-class-path /home/mk/mysql-connector-java-5.1.26-bin.jar --jars /home/mk/mysql-connector-java-5.1.26-bin.jar
netstat -nap | grep 10000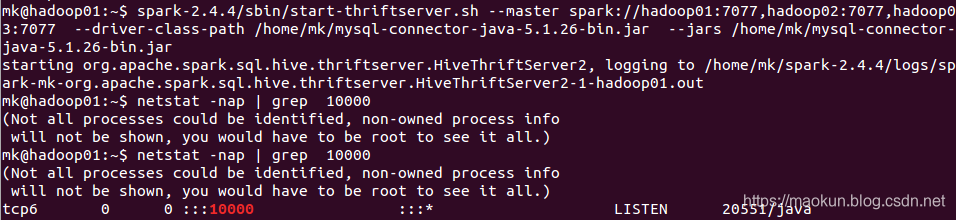
二、启动beeline
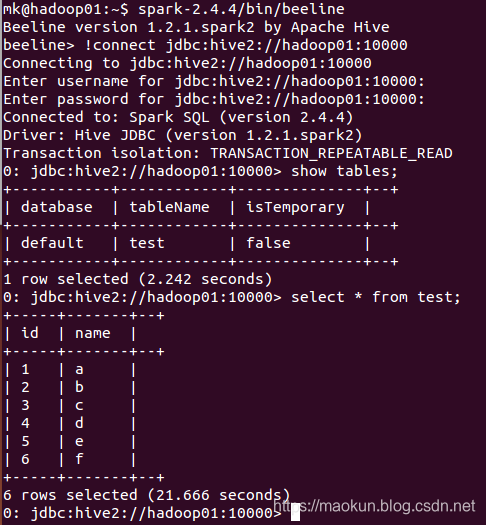
spark-2.4.4/bin/beeline
#连接
!connect jdbc:hive2://hadoop01:10000
show tables;
select * from test;
#退出
!quit

三、总结
thriftserver/beeline和普通的spark-shell/spark-sql区别
(1)对于derby存储元数据
1、spark-shell、spark-sql是启动一个spark application,只能服务于唯一的客户端,同一路径启动多客户端会报错;
2、thriftservers是启动一个spark application提供接口服务,为多客户端进行服务。解决了数据共享的问题,多个客户端可以共享数据问题;
(2)对于其他非本地的数据库存储元数据
1、spark-shell、spark-sql是启动一个spark application,服务于一个的客户端。可以启动多个spark-shell、spark-sql,客户端之间的操作互相不干扰。
2、thriftservers是启动一个spark application提供接口服务,为多客户端进行服务。如有客户端的操作过多,会干扰到其他客户端的进一步操作。
