自监督学习论文集装箱:awesome-self-supervised-learning
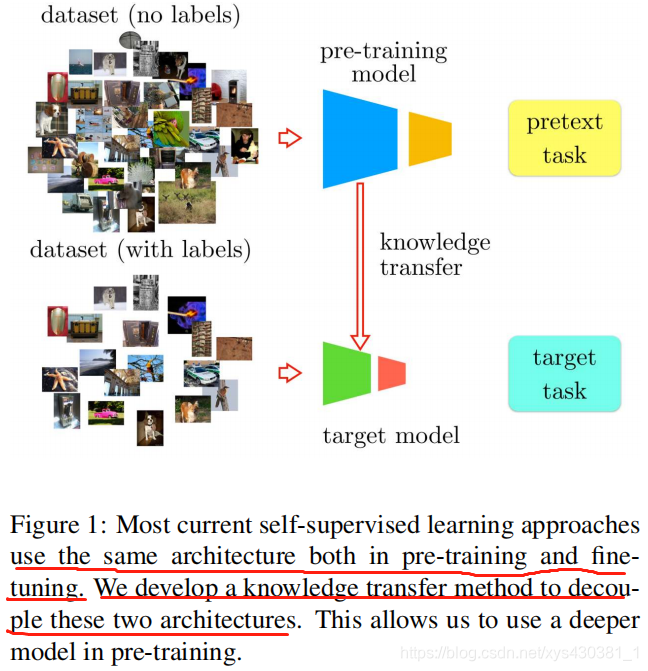
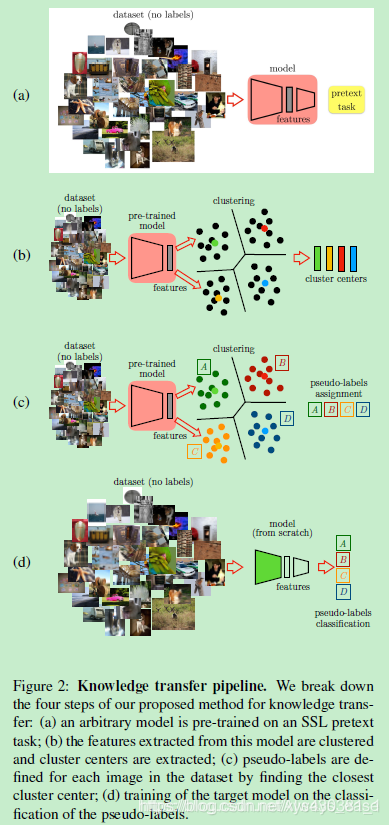
Boosting Self-Supervised Learning via Knowledge Transfer
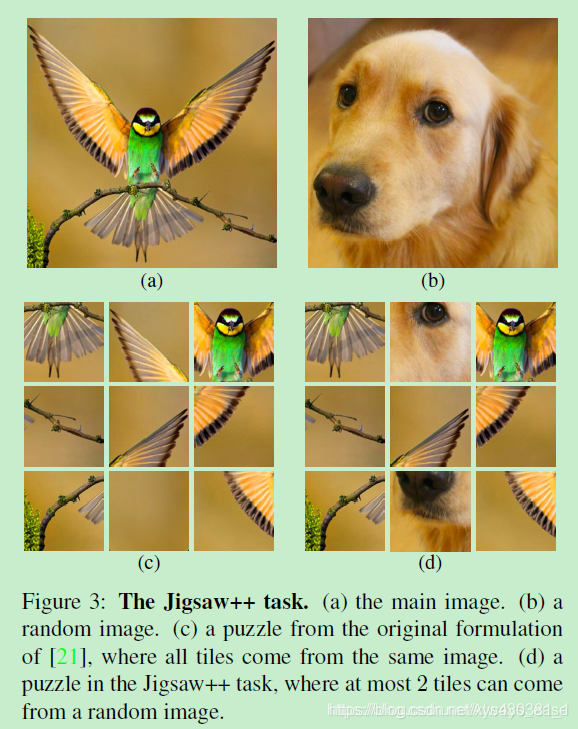
(a)中的pretext task是Jigsaw++ task
解读自监督学习几篇相关paper
自监督学习的思想非常简单,就是输入的是一堆无监督的数据,但是通过数据本身的结构或者特性,人为构造标签(pretext)出来。有了标签之后,就可以类似监督学习一样进行训练。
比较知名的工作有两个,一个是:Unsupervised Visual Representation Learning by Context Prediction(ICCV15),如图一,人为构造图片Patch相对位置预测任务,这篇论文可以看作是self-supervised这一系列方法的最早期paper之一;另一个是:Unsupervised Representation Learning by Predicting Image Rotations (ICLR18),如图二,人为构造图片旋转角度预测任务,这篇论文因为想法极其简单在投稿到ICLR之后受到了极大关注,最终因为实验结果非常全面有效最终被录用。
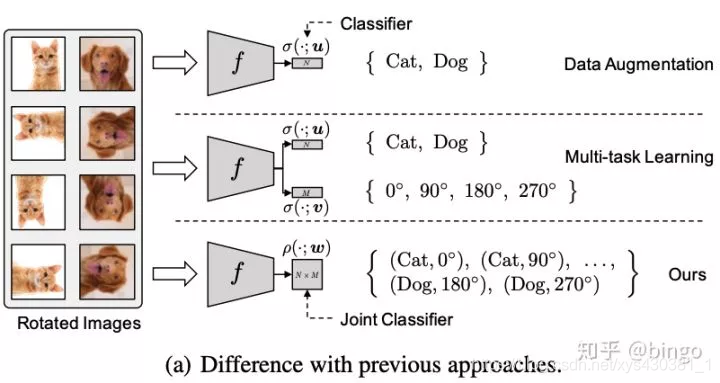
RETHINKING DATA AUGMENTATION: SELF- SUPERVISION AND SELF-DISTILLATION。
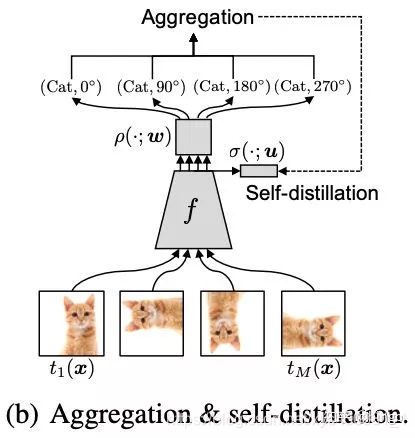
这篇论文的思想非常直观,如图三。首先,Data Augmentation相关的方法会对通过对原始图片进行一些变换(颜色、旋转、裁切等)来扩充原始训练集合,提高模型泛化能力;Multi-task learning将正常分类任务和self-supervised learning的任务(比如旋转预测)放到一起进行学习。作者指出通过data augmentation或者multi-task learning等方法的学习强制特征具有一定的不变性,会使得学习更加困难,有可能带来性能降低。因此,作者提出将分类任务的类别和self-supervised learning的类别组合成更多类别(例如 (Cat, 0),(Cat,90)等),用一个损失函数进行学习。

Revisiting Self-Supervised Visual Representation Learning (CVPR19)
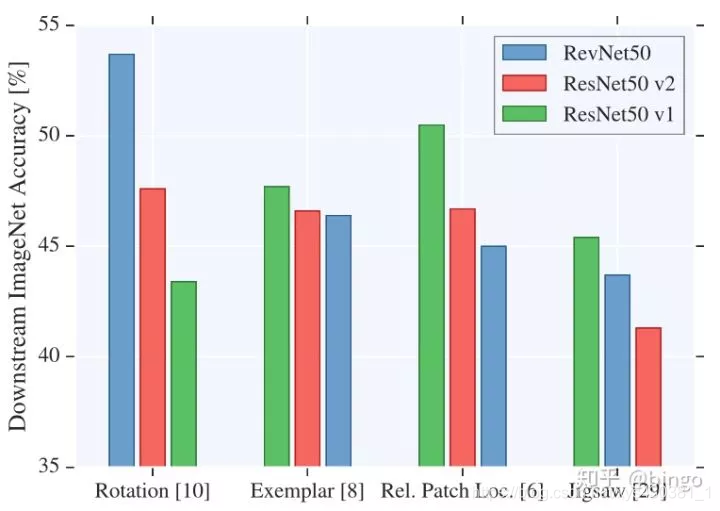
Revisiting这篇paper研究了多种网络结构以及多种self-supervised的任务的组合,得到了一些启发性的经验结论:
与supervised learning不同的是,self-supervised learning在不同task上的结果依赖于网络结构的选择,比如对于rotation预测,RevNet50性能最好,但是对于Patch预测,ResNet50v1性能最好。
以前的self-supervised方法通常表明,alexnet的最后几层特征性能会下降。但是这篇paper结论是对于skip-connection(resnet)结构的网络,高层的特征性能并不会下降。
增加filter数目和特征大小,对于性能提升帮助很大。
衡量无监督性能最后训练的线性分类器非常依赖学习率的调整策略。
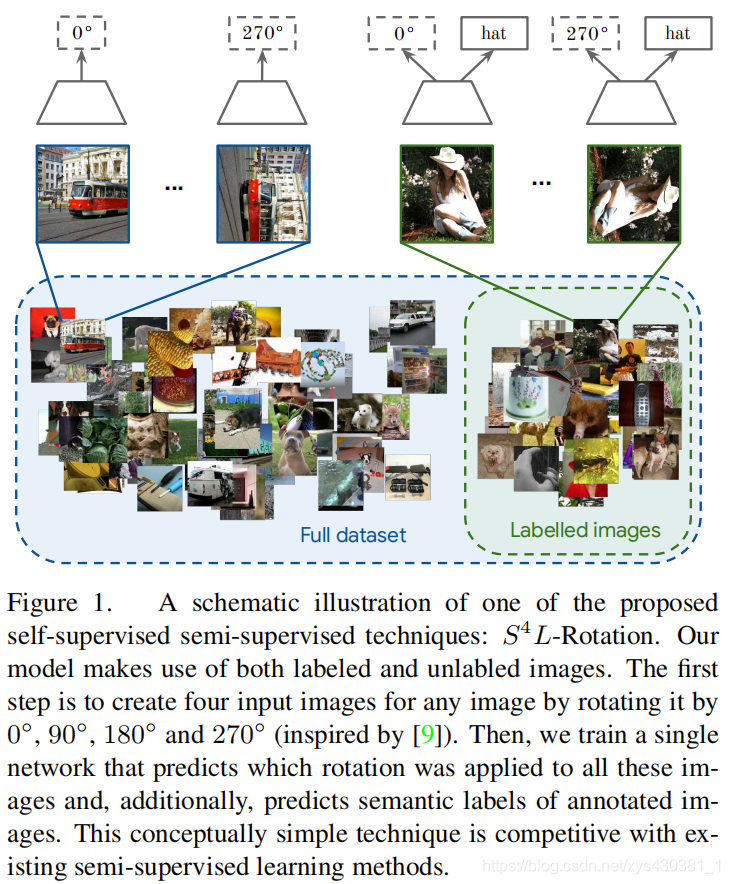
S^4L: Self-Supervised Semi-Supervised Learning(ICCV19) 。
S^4L这一篇paper,非常像上面图(a)中multitask learning的策略,即有标签数据上面加一个正常的分类损失,无标签数据上加一个self-supervised的损失,具体公式如下: