我们使用windows 本地myeclipse测试程序,具体搭建教程请看
https://blog.csdn.net/weixin_41407399/article/details/79763235
首先创建maven 项目,并修改pom.xml,导入hbase 第三方jar包,首次会自动下载
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>0.98.6-hadoop2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>0.98.6-hadoop2</version>
</dependency>
建一个resource folder ,将hive-site.xml 和log4j放入该文件夹
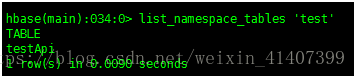
在hbase创建一个测试用的namespace

一下是java 代码
封装工具类
package com.hadoop.hbaseTest.util;
/**
* 封装工具类
*/
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
public class HbaseUtil {
// 获取HTable
public static HTable getConf(String tableName) {
// 创建俺新conf
Configuration conf = HBaseConfiguration.create();
HTable htbl = null;
try {
htbl = new HTable(conf, tableName);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return htbl;
}
// 关闭资源
public static void closeHtable(HTable htbl) {
try {
htbl.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
dao层的接口
package com.hadoop.hbaseTest.dao;
/**
* dao层借口
* @author Administrator
*
*/
public interface OperationDao {
// 增加数据接口
public void putData(String rowKey);
// 删除数据接口
public void deleteData(String rowKey);
// 修改数据解耦
public void updateData(String rowKey);
// 查看数据接口
public void getData(String rowKey);
// 批量导入数据
public void putAllData(String rowKey);
// 扫描表接口
public void scanData(String startRow, String stopRow);
// 创建表
public void createTable(String tableName);
// 删除表
public void deleteTable(String tableName);
}
dao层接口实现类
package com.hadoop.hbaseTest.dao.daoImpl;
/**
* dao层接口实现类
*/
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.zookeeper.common.IOUtils;
import com.hadoop.hbaseTest.dao.OperationDao;
import com.hadoop.hbaseTest.util.HbaseUtil;
public class OperationDaoImpl implements OperationDao {
@Override
public void putData(String rowKey) {
// TODO Auto-generated method stub
try {
HTable htbl = HbaseUtil.getConf("test:testApi");
// 将行键传入put
Put put = new Put(Bytes.toBytes(rowKey));
// 增加数据
put.add(Bytes.toBytes("info"), Bytes.toBytes("num"), Bytes.toBytes("hadoop"+1));
htbl.put(put);
HbaseUtil.closeHtable(htbl);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void deleteData(String rowKey) {
// TODO Auto-generated method stub
// 创建新的Conf
try {
HTable htbl = HbaseUtil.getConf("test:testApi");
// 将行键传入delete
Delete del = new Delete(Bytes.toBytes(rowKey));
// 删除行
del.deleteColumn(Bytes.toBytes("info"), Bytes.toBytes("num"));
htbl.delete(del);
HbaseUtil.closeHtable(htbl);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@Override
public void updateData(String rowKey) {
// TODO Auto-generated method stub
try {
HTable htbl = HbaseUtil.getConf("test:testApi");
// 将行键传入put
Put put = new Put(Bytes.toBytes(rowKey));
// 增加数据
put.add(Bytes.toBytes("info"), Bytes.toBytes("num"), Bytes.toBytes("hadoop"+3));
htbl.put(put);
HbaseUtil.closeHtable(htbl);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void getData(String rowKey) {
// TODO Auto-generated method stub
try {
HTable htbl = HbaseUtil.getConf("test:testApi");
// 将行键传入get
Get get = new Get(Bytes.toBytes(rowKey));
// 添加查询条件
get.addColumn(Bytes.toBytes("info"), Bytes.toBytes("num"));
// 获取结果集合
Result rs = htbl.get(get);
Cell[] cells = rs.rawCells();
// 循环遍历结果
for (Cell cell : cells) {
// 打印结果
System.out.print(Bytes.toString(CellUtil.cloneFamily(cell)) + ":");
System.out.print(Bytes.toString(CellUtil.cloneQualifier(cell)) + "->");
System.out.print(Bytes.toString(CellUtil.cloneValue(cell)));
}
System.out.println();
HbaseUtil.closeHtable(htbl);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void putAllData(String rowKey) {
// TODO Auto-generated method stub
try {
HTable htbl = HbaseUtil.getConf("test:testApi");
List<Put> list = new ArrayList<Put>(10000);
// 增加数据
for (long i = 1; i <= 1000000; i++) {
Put put = new Put(Bytes.toBytes(rowKey + i));
put.add(Bytes.toBytes("info"), Bytes.toBytes("num"), Bytes.toBytes("hadoop" + i));
list.add(put);
//每到10万次导入一次数据
if (i % 100000 == 0) {
htbl.put(list);
list = new ArrayList<Put>(10000);
}
}
//数据如果不是10万整数倍,剩余数据循环结束一次导入
htbl.put(list);
HbaseUtil.closeHtable(htbl);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void scanData(String startRow, String stopRow) {
// TODO Auto-generated method stub
HTable htbl = null;
ResultScanner rss = null;
try {
htbl = HbaseUtil.getConf("test:testApi");
// 将行键传入scan
Scan scan = new Scan(Bytes.toBytes(startRow), Bytes.toBytes(stopRow));
// 添加查询条件
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("num"));
// 获取结果集集合
rss = htbl.getScanner(scan);
// 遍历结果集集合
for (Result rs : rss) {
System.out.print(Bytes.toString(rs.getRow())+"\t");
// 遍历结果集合
Cell[] cells = rs.rawCells();
for (Cell cell : cells) {
System.out.print(Bytes.toString(CellUtil.cloneFamily(cell)) + ":");
System.out.print(Bytes.toString(CellUtil.cloneQualifier(cell)) + "->");
System.out.print(Bytes.toString(CellUtil.cloneValue(cell)));
}
System.out.println();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭资源
IOUtils.closeStream(rss);
IOUtils.closeStream(htbl);
}
}
@Override
public void createTable(String tableName) {
// TODO Auto-generated method stub
Configuration conf = HBaseConfiguration.create();
//conf.set("hbase.zookeeper.quorum", "master");
try {
HBaseAdmin hba = new HBaseAdmin(conf);
HTableDescriptor htd = new HTableDescriptor(TableName.valueOf(tableName));
HColumnDescriptor info = new HColumnDescriptor("info");
info.setValue("num", "003");
htd.addFamily(info);
hba.createTable(htd);
hba.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@Override
public void deleteTable(String tableName) {
// TODO Auto-generated method stub
Configuration conf = HBaseConfiguration.create();
try {
HBaseAdmin hba = new HBaseAdmin(conf);
hba.disableTable(tableName);
hba.deleteTable(tableName);
hba.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
测试类
package com.hadoop.hbaseTest.service;
/**
* 测试类
*/
import com.hadoop.hbaseTest.dao.daoImpl.OperationDaoImpl;
public class Test {
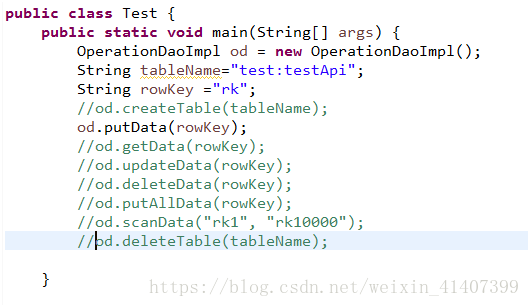
public static void main(String[] args) {
OperationDaoImpl od = new OperationDaoImpl();
String tableName = "test:testApi";
String rowKey = "rk";
od.createTable(tableName);
od.putData(rowKey);
od.getData(rowKey);
od.updateData(rowKey);
od.deleteData(rowKey);
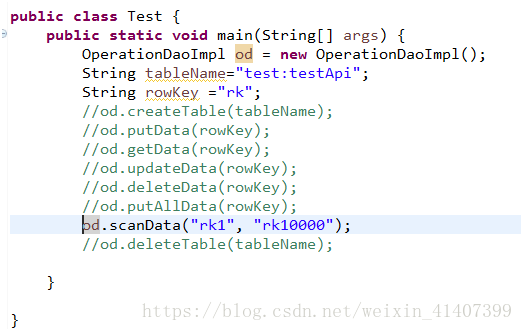
od.putAllData(rowKey);
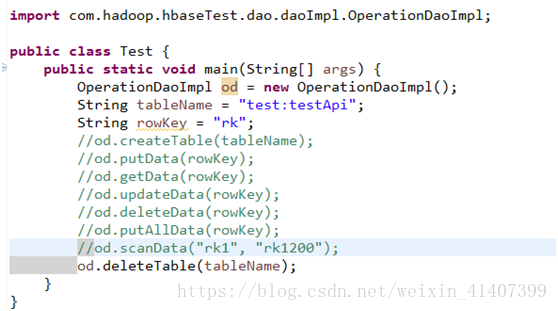
od.scanData("rk1", "rk1200");
od.deleteTable(tableName);
}
}
下面是测试结果
创建表
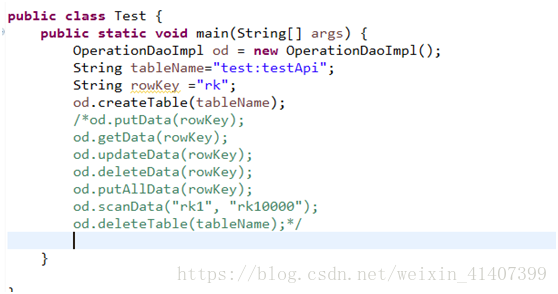
运行后,创建表成功
插入数据
运行插入成功

查询数据
运行查询成功

修改数据
运行修改成功,hadoop1 变成hadoop2

删除数据
运行一次,删除最近时间戳版本,回到hadoop1

再次运行,删除前一时间戳版本,删除成功,数据清空

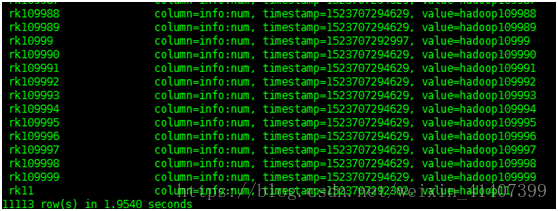
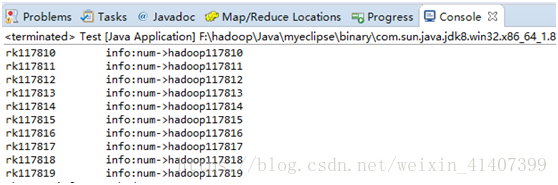
批量导入数据
运行,去habse 查询数据,插入成功
扫描笔
运行插入成功
删除表
运行删除成功
