深度学习中常用数据集的制作与转换
一. 数据集的制作。以常用的LabelImg和Labelme为例。
1. PASCAL VOC格式数据集(常用于目标检测)。
a. 安装LabelImg。LabelImg是一款开源的图像标注工具,标签可用于分类和目标检测,它是用 Python 编写的,并使用Qt作为其图形界面,简单好用。注释以 PASCAL VOC 格式保存为 XML 文件。
# Python 3 + Qt5 (Recommended)
pip install labelImg
labelImg
本文LabelImg版本:1.8.3
b. 操作界面。详细教程
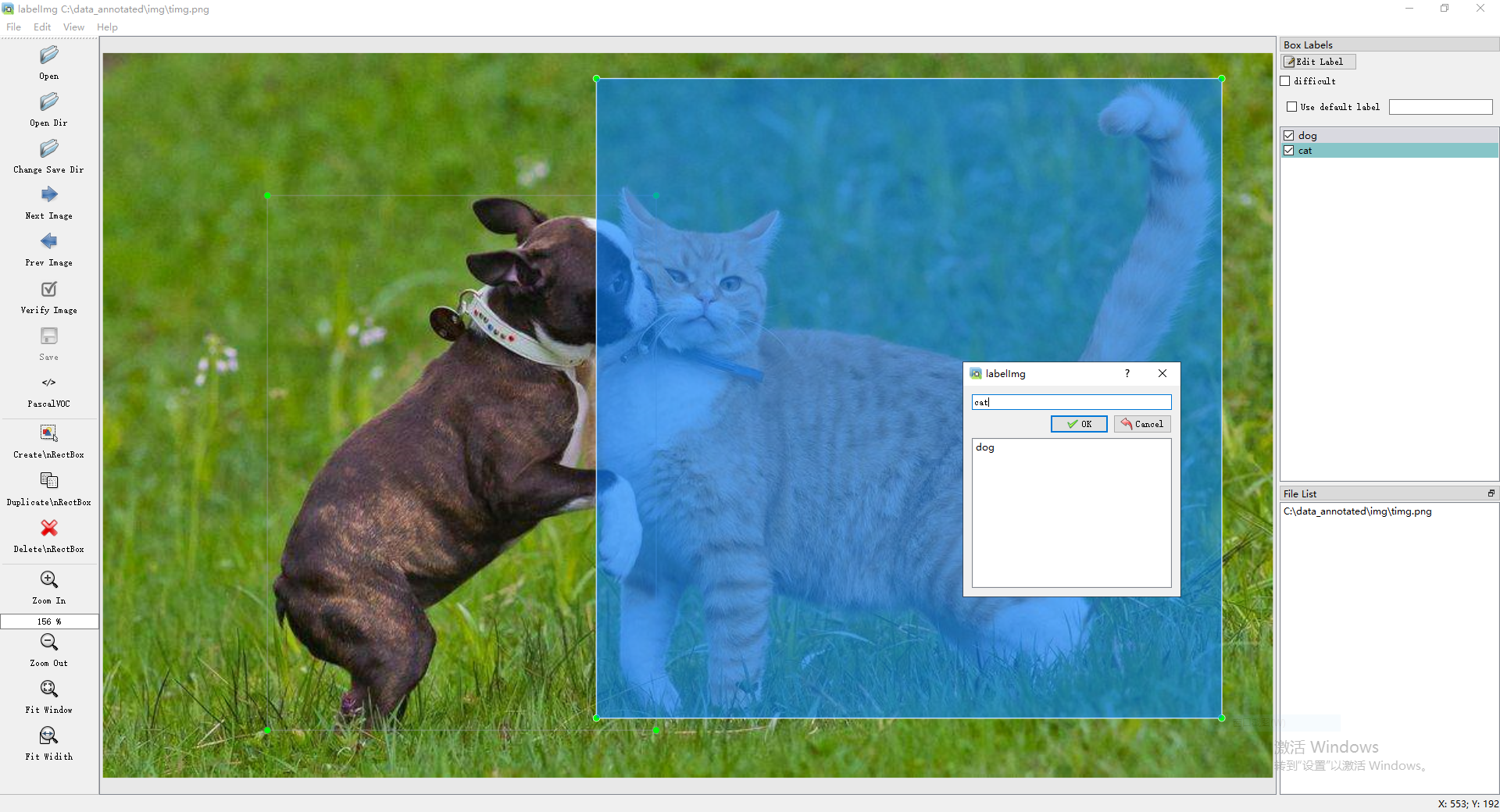
c. PASCAL VOC数据操作
import sys
import os
from xml.etree import ElementTree
from xml.etree.ElementTree import Element, SubElement
from lxml import etree
import codecs
import cv2
img_path = 'img/timg.png'
xml_path = 'img/timg.xml'
01. 数据读取
class PascalVocReader: def __init__(self, filepath): # shapes type: # [labbel, [Xmin, Xmax, Ymin, Ymax], color, color, difficult] self.shapes = [] self.filepath = filepath self.verified = False self.XML_EXT = '.xml' self.ENCODE_METHOD = 'utf-8' try: self.parseXML() except: pass def getShapes(self): return self.shapes def addShape(self, label, bndbox, difficult): xmin = int(float(bndbox.find('xmin').text)) ymin = int(float(bndbox.find('ymin').text)) xmax = int(float(bndbox.find('xmax').text)) ymax = int(float(bndbox.find('ymax').text)) points = [xmin, xmax, ymin, ymax] self.shapes.append((label, points, None, None, difficult)) def parseXML(self): assert self.filepath.endswith(self.XML_EXT), "Unsupport file format" parser = etree.XMLParser(encoding=self.ENCODE_METHOD) xmltree = ElementTree.parse(self.filepath, parser=parser).getroot() filename = xmltree.find('filename').text try: verified = xmltree.attrib['verified'] if verified == 'yes': self.verified = True except KeyError: self.verified = False for object_iter in xmltree.findall('object'): bndbox = object_iter.find("bndbox") label = object_iter.find('name').text # Add chris difficult = False if object_iter.find('difficult') is not None: difficult = bool(int(object_iter.find('difficult').text)) self.addShape(label, bndbox, difficult) return True
reader = PascalVocReader(xml_path)
shapes = reader.getShapes()
print(shapes)
'''
# [labbel, [Xmin, Xmax, Ymin, Ymax], color, color, difficult]
[('dog', [135, 454, 117, 556], None, None, False), ('cat', [405, 918, 21, 546], None, None, False)]
'''
02. 数据可视化
class PascalVocVisualizer: def __init__(self, imgpath, shapes): self.BOX_COLOR = (0, 0, 255) self.TEXT_COLOR = (255, 255, 255) self.shapes = shapes self.imgpath = imgpath def visualize_bbox(self, img, bbox, class_name, thickness=2): x_min, x_max, y_min, y_max = bbox cv2.rectangle(img, (x_min, y_min), (x_max, y_max), color=self.BOX_COLOR, thickness=thickness) ((text_width, text_height), _) = cv2.getTextSize(class_name, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2) if y_min < int(1.4 * text_height): y_min += int(1.4 * text_height) cv2.rectangle(img, (x_min, y_min - int(1.3 * text_height)), (x_min + text_width, y_min), self.BOX_COLOR, -1) cv2.putText(img, class_name, (x_min, y_min - int(0.3 * text_height)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, self.TEXT_COLOR, lineType=cv2.LINE_AA) return img def visualize(self): img = cv2.imread(self.imgpath) for idx, shape in enumerate(self.shapes): img = self.visualize_bbox(img, shape[1], shape[0]) cv2.imshow('vis', img) cv2.waitKey(0)
visualizer = PascalVocVisualizer(img_path, shapes)
vis = visualizer.visualize()
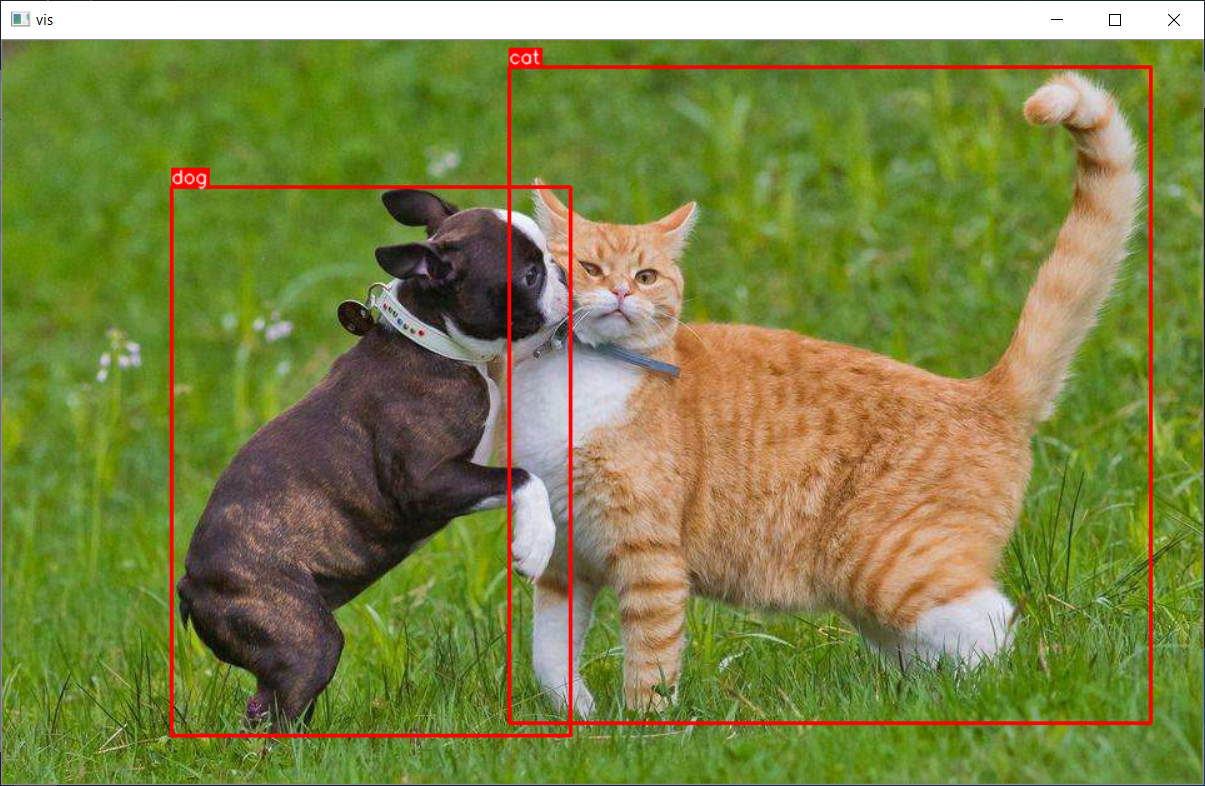
03. 数据写入
class PascalVocWriter: def __init__(self, foldername, filename, imgSize, databaseSrc='Unknown', localImgPath=None): self.foldername = foldername self.filename = filename self.databaseSrc = databaseSrc self.imgSize = imgSize self.boxlist = [] self.localImgPath = localImgPath self.verified = False self.XML_EXT = '.xml' self.ENCODE_METHOD = 'utf-8' def prettify(self, elem): """ Return a pretty-printed XML string for the Element. """ rough_string = ElementTree.tostring(elem, 'utf8') root = etree.fromstring(rough_string) return etree.tostring(root, pretty_print=True, encoding=self.ENCODE_METHOD).replace(" ".encode(), "\t".encode()) def ustr(self, x): if sys.version_info < (3, 0, 0): from PyQt4.QtCore import QString if type(x) == str: return x.decode(self.DEFAULT_ENCODING) if type(x) == QString: return unicode(x.toUtf8(), self.DEFAULT_ENCODING, 'ignore') return x else: return x def genXML(self): """ Return XML root """ # Check conditions if self.filename is None or \ self.foldername is None or \ self.imgSize is None: return None top = Element('annotation') if self.verified: top.set('verified', 'yes') folder = SubElement(top, 'folder') folder.text = self.foldername filename = SubElement(top, 'filename') filename.text = self.filename if self.localImgPath is not None: localImgPath = SubElement(top, 'path') localImgPath.text = self.localImgPath source = SubElement(top, 'source') database = SubElement(source, 'database') database.text = self.databaseSrc size_part = SubElement(top, 'size') width = SubElement(size_part, 'width') height = SubElement(size_part, 'height') depth = SubElement(size_part, 'depth') width.text = str(self.imgSize[1]) height.text = str(self.imgSize[0]) if len(self.imgSize) == 3: depth.text = str(self.imgSize[2]) else: depth.text = '1' segmented = SubElement(top, 'segmented') segmented.text = '0' return top def addBndBox(self, shape): name = shape[0] xmin, ymin, xmax, ymax = shape[1] difficult = shape[4] bndbox = {'xmin': xmin, 'ymin': ymin, 'xmax': xmax, 'ymax': ymax} bndbox['name'] = name bndbox['difficult'] = difficult self.boxlist.append(bndbox) def appendObjects(self, top): for each_object in self.boxlist: object_item = SubElement(top, 'object') name = SubElement(object_item, 'name') name.text = self.ustr(each_object['name']) pose = SubElement(object_item, 'pose') pose.text = "Unspecified" truncated = SubElement(object_item, 'truncated') if int(float(each_object['ymax'])) == int(float(self.imgSize[0])) or (int(float(each_object['ymin']))== 1): truncated.text = "1" # max == height or min elif (int(float(each_object['xmax']))==int(float(self.imgSize[1]))) or (int(float(each_object['xmin']))== 1): truncated.text = "1" # max == width or min else: truncated.text = "0" difficult = SubElement(object_item, 'difficult') difficult.text = str( bool(each_object['difficult']) & 1 ) bndbox = SubElement(object_item, 'bndbox') xmin = SubElement(bndbox, 'xmin') xmin.text = str(each_object['xmin']) ymin = SubElement(bndbox, 'ymin') ymin.text = str(each_object['ymin']) xmax = SubElement(bndbox, 'xmax') xmax.text = str(each_object['xmax']) ymax = SubElement(bndbox, 'ymax') ymax.text = str(each_object['ymax']) def save(self, targetFile=None): root = self.genXML() self.appendObjects(root) out_file = None if targetFile is None: out_file = codecs.open( self.filename.split('.')[0] + self.XML_EXT, 'w', encoding=self.ENCODE_METHOD) else: out_file = codecs.open(os.path.join(self.foldername, targetFile), 'w', encoding=self.ENCODE_METHOD) prettifyResult = self.prettify(root) out_file.write(prettifyResult.decode('utf8')) out_file.close()
img = cv2.imread(img_path)
writer = PascalVocWriter(os.path.dirname(img_path), os.path.basename(img_path), img.shape, localImgPath=os.path.abspath(img_path))
for shape in shapes:
writer.addBndBox(shape)
writer.save('new.xml')
2. 分割数据集。
a. 安装labelme。 labelme是一款开源的图像/视频标注工具,标签可用于目标检测、分割和分类,支持图像的标注的组件有:矩形框,多边形,圆,线,点等,保存为labelme json文件。
# Python 3 + Qt5 (Recommended)
pip install labelme
labelme
本文Labelme版本:4.2.9
b. 操作界面。详细教程
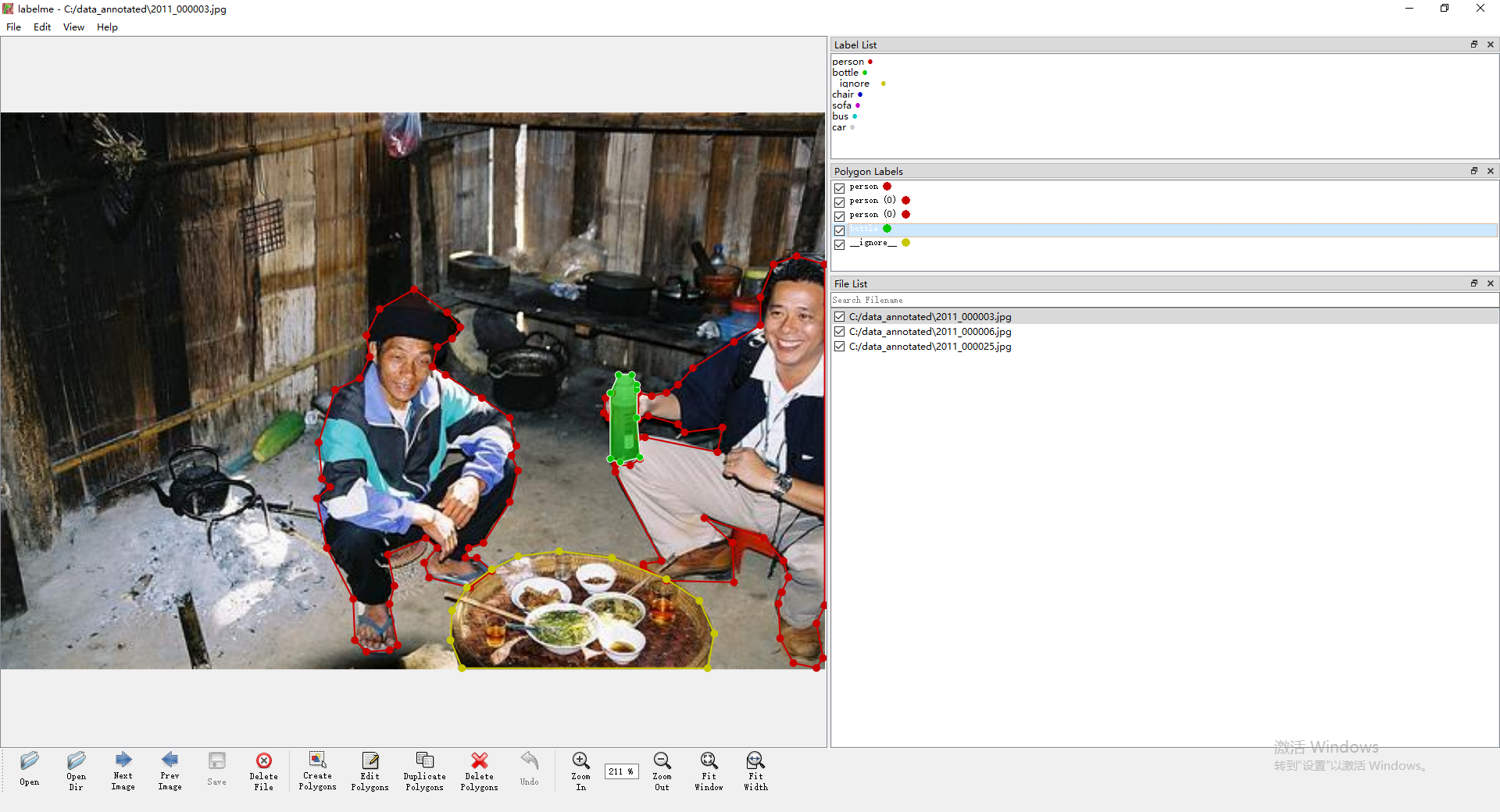
c. labelme json数据操作
可使用labelme工具转换json文件为数据集
labelme_json_to_dataset *.json
二. 数据集的转换。
1. Labelme json 转 COCO json
Labelme json文件一般只存储单个图片的标记信息,不同于COCO json.
import os
import json
import glob
import base64
import io
import cv2
import time
import sys
import numpy as np
import PIL.Image
labelme to coco
class Lableme2CoCo: def __init__(self, img_format): self.images = [] self.annotations = [] self.categories = [] self.category_id = 0 self.img_id = 0 self.ann_id = 0 self.ann_num = 0 self.img_format = img_format def save_coco_json(self, instance, save_path): json.dump(instance, open(save_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=4) print("\nsave instance json file to {}".format(save_path)) def to_coco(self, json_path_list): for json_path in json_path_list: obj = self.read_jsonfile(json_path) self.images.append(self._image(obj, json_path)) shapes = obj['shapes'] for shape in shapes: annotation = self._annotation(shape) self.annotations.append(annotation) self.ann_id += 1 self.img_id += 1 instance = dict() instance['info'] = 'instance segmentation' instance['license'] = ['license'] instance['images'] = self.images instance['annotations'] = self.annotations instance['categories'] = self.categories return instance def _init_categories(self, label): category = dict() if len(self.categories) == 0: category['id'] = self.category_id category['name'] = label self.categories.append(category) self.category_id += 1 else: category_list = [] for c in self.categories: category_list.append(c['name']) if label not in category_list: category['id'] = self.category_id category['name'] = label self.categories.append(category) self.category_id += 1 def _image(self, obj, path): image = dict() from labelme import utils img_x = utils.img_b64_to_arr(obj['imageData']) if len(img_x.shape[:]) == 3: h, w = img_x.shape[:-1] else: h, w = img_x.shape[:] image['height'] = h image['width'] = w image['id'] = self.img_id image['file_name'] = os.path.basename(path).replace(".json", self.img_format) return image def _annotation(self, shape): label = shape['label'] self._init_categories(label) points = shape['points'] category = list(filter(lambda c: c['name'] == label, self.categories))[0] annotation = dict() annotation['id'] = self.ann_id annotation['image_id'] = self.img_id annotation['category_id'] = category['id'] annotation['segmentation'] = [np.asarray(points).flatten().tolist()] annotation['bbox'] = self._get_box(points) annotation['iscrowd'] = 0 annotation['area'] = 1.0 return annotation def read_jsonfile(self, path): self.ann_num += 1 sys.stdout.write("\rload json file: {}, number: {}".format(path, self.ann_num)) sys.stdout.flush() try: with open(path, "r", encoding='utf-8') as f: return json.load(f) except: with open(path, "r", encoding='gbk') as f: return json.load(f) def _get_box(self, points): min_x = min_y = np.inf max_x = max_y = 0 for x, y in points: min_x = min(min_x, x) min_y = min(min_y, y) max_x = max(max_x, x) max_y = max(max_y, y) return [min_x, min_y, max_x - min_x, max_y - min_y]
a. 数据集转换
labelme_json_path = "./labelme_json" # 输入的labelme json文件夹(需要包含imageData字段的内容)
save_coco_path = "./coco_dataset" # 输出文件夹
annotations_path = os.path.join(save_coco_path, 'annotations')
image_path = os.path.join(save_coco_path, 'images')
if not os.path.exists(annotations_path):
os.makedirs(annotations_path)
if not os.path.exists(image_path):
os.makedirs(image_path)
json_list_path = glob.glob(os.path.join(input_path, '*.json'))
l2c_train = Lableme2CoCo(img_format='.png')
train_instance = l2c_train.to_coco(json_list_path)
l2c_train.save_coco_json(train_instance, os.path.join(annotations_path, 'trainval.json'))
print("Start creating images..")
for json_path in json_list_path:
data_dict = json.load(open(json_path))
imageData = data_dict['imageData']
img = img_b64_to_arr(imageData)
img_save_path = os.path.join(image_path, os.path.basepath(json_path).split('.')[0] + img_format)
img.save(img_save_path)
print('\nSave dataset to {}. end!'.format(save_coco_path))
b. 数据集测试
from pycocotools.coco import COCO
ann_file = "./coco_dataset/annotations/trainval.json" # 转换后的COCO json文件
coco = COCO(annotation_file=ann_file)
print("coco\nimages.size [%05d]\t annotations.size [%05d]\t category.size [%05d]"
% (len(coco.imgs), len(coco.anns), len(coco.cats)))
if len(coco.imgs) < 1:
print('error!')
else:
print('success!')
'''
loading annotations into memory...
Done (t=0.00s)
creating index...
index created!
coco
images.size [00002] annotations.size [00002] category.size [00001]
success!
'''