前言
在深度学习中,如果没有数据集,就无法训练模型,所以数据是根本,下面列出几个常用数据集。
想要更多数据集,可以去这个地址:https://www.cvmart.net/dataSets或https://gas.graviti.cn/open-datasets
自动驾驶数据集
1. BDD100K数据集
2018年5月伯克利大学AI实验室(BAIR)发布了公开驾驶数据集BDD100K,同时设计了一个图片标注系统。BDD100K 数据集包含10万段高清视频,每个视频约40秒\720p\30 fps 。每个视频的第10秒对关键帧进行采样,得到10万张图片(图片尺寸:1280*720 ),并进行标注。10万张图片中,包含了不同天气、场景、时间的图片,而且高清、模糊的图片都有,具有规模大,多样化的特点。
数据集大小:6.42GB
地址:https://gas.graviti.cn/dataset/data-decorators/BDD100K

2. CityScapes数据集
CityScapes是由奔驰自动驾驶实验室、马克思·普朗克研究所、达姆施塔特工业大学联合发布的公开数据集,专注于对城市街景的语义理解。该数据集包含50个不同的城市,在不同的季节和天气条件下的街景中记录的各种立体视频序列,Cityscapes数据集共有fine和coarse两套评测标准,前者提供5000张精细标注的图像,后者提供5000张精细标注外加20000张粗糙标注的图像。
数据集大小:74.15GB
地址:https://gas.graviti.cn/dataset/graviti-open-dataset/CityScapes

目标检测数据集
1. COCO数据集
COCO的全称是Common Objects in Context,是微软团队提供的用来进行目标识别、图像分割等任务的数据集。COCO数据集有如下几个特点:目标分割、上下文识别、超像素分割、330K图像(已标记> 200K)、150万个对象实例、80个对象类别、91个物品类别、每个图像5个字幕、250,000包含关键点的人。
COCO数据集支持目标检测、实例分割、全景分割、Stuff Segmentation、关键点检测、看图说话等任务类型。图片格式均为JPG格式,其中目标检测,实例分割任务对应的图像类别为80类;Stuff Segmentation,全景分割任务新增图像类别53类。
数据集大小:83.39GB
地址:https://gas.graviti.cn/dataset/shannont/COCO

2. PASCAL VOC2012数据集
PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛, 很多优秀的计算机视觉模型比如分类,定位,检测,分割,动作识别等模型都是基于PASCAL VOC挑战赛及其数据集上推出的,尤其是一些目标检测模型(比如大名鼎鼎的R CNN系列,以及后面的YOLO,SSD等)。
PASCAL VOC 2012数据集是在2007年的基础上增加而来的,包含4个大类和20个小类。
数据集大小:1.86GB
地址:https://gas.graviti.cn/dataset/data-decorators/VOC2012Detection

人脸识别数据集
1. LFW数据集
LFW (Labeled Faces in the Wild) 人脸数据库是由美国马萨诸塞州立大学阿默斯特分校计算机视觉实验室整理完成的数据库,主要用来研究非受限情况下的人脸识别问题。是目前人脸识别的常用测试集,其中提供的人脸图片均来源于生活中的自然场景,因此识别难度会增大,尤其由于多姿态、光照、表情、年龄、遮挡等因素影响导致即使同一人的照片差别也很大。并且有些照片中可能不止一个人脸出现,对这些多人脸图像仅选择中心的人脸作为目标,其他区域的视为背景干扰。
LFW数据集主要是从互联网上搜集图像,共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片,其中有1680 人包含两个以上的人脸图像。每张图片的尺寸为250X250,绝大部分为彩色图像,也存在少许黑白人脸图片。
数据集大小:1.29GB
地址:https://gas.graviti.cn/dataset/graviti-open-dataset/LFW

文本检测数据集
1. SVHN数据集
SVHN是从Google街景图像中的门牌号获得的一个来自现实世界的图像数据集,用于开发机器学习和对象识别算法,同时对数据预处理和格式化的要求最低。它的风格与MNIST相似,但有更多数量级的标记数据(超过600,000位数字图像),并且希望解决一个更加困难,难以解决的现实问题(识别自然场景图像中的数字)。
数据集中包含10个类别,数字1~9对应标签1~9,而“0”的标签则为10。训练集中共有73257张图像,测试集中有26032张图像。
数据集格式:带有字符级边界框的原始图像。
数据集大小:3.92GB
地址:https://gas.graviti.cn/dataset/data-decorators/SVHN
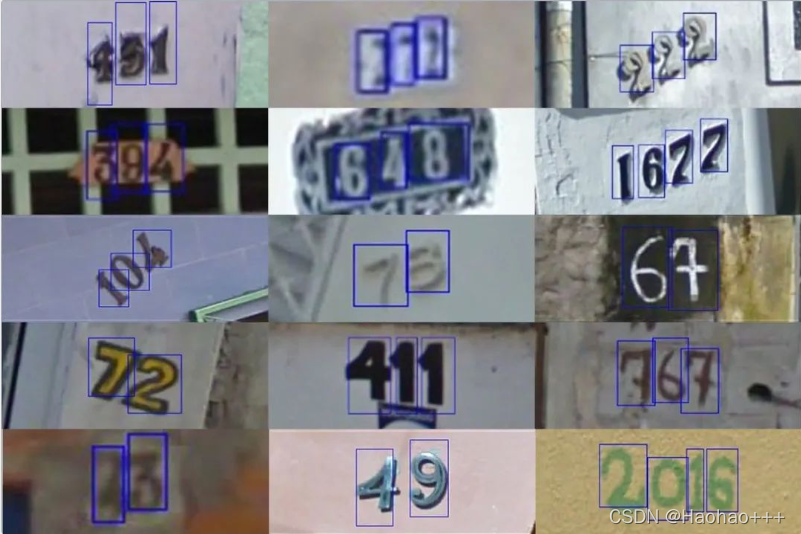
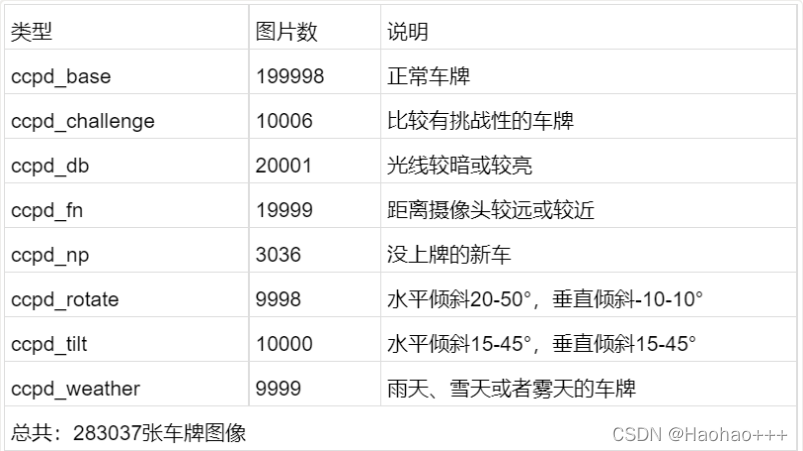
2. CCPD数据集
CCPD(Chinese City Parking Dataset)数据集是一个用于车牌识别的大型国内停车场车牌数据集,是由中科大团队建立的。该数据集在合肥市的停车场采集得来,采集时间早上7:30到晚上10:00。停车场采集人员手持Android POS机对停车场的车辆拍照并手工标注车牌位置。拍摄的车牌照片涉及多种复杂环境,包括模糊、倾斜、阴雨天、雪天等等。CCPD数据集一共包含将近30万张图片,每种图片大小720x1160x3。一共包含8项,具体如下:
数据集大小:23.48GB
地址:https://gas.graviti.cn/dataset/data-decorators/CCPD
图像分类
1. NICO
NICO数据集是专门为非i.i.d。或OOD (out - distribution)图像分类。它模拟了一个真实世界的设置,即测试分布可能导致训练分布的任意偏移,这违反了大多数ML方法传统的识别假设。数据集可以很好地支持的典型研究方向包括但不限于迁移学习或领域适应(当测试分布已知时)和稳定学习或领域泛化(当测试分布未知时)。
构建数据集的基本思想是用主要概念(如狗)和视觉概念出现的上下文(如草地)来标记图像。通过调整训练和测试数据中不同上下文的比例,可以灵活控制分布偏移的程度,对不同类型的Non-I.I.D进行研究。设置。
到目前为止,有两个超类:动物和交通工具,有10类动物和9类交通工具。每个类有9或10个上下文。每个上下文的平均图像数量从83到215,每个类的平均图像数量大约是1300张(类似于ImageNet)。NICO共包含19个分类、188个上下文和近25000张图像。当前版本已经能够从头开始支持深度卷积网络(如ResNet-18)的训练。规模仍在增加,由于其分层结构,易于扩展。
数据集大小:4.1GB
地址:https://gas.graviti.cn/dataset/hello-dataset/NICO
