针对于LR,NN模型的数据处理
针对生成树的数据处理链接https://editor.csdn.net/md?articleId=105156784
文章目录
导入数据
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from operator import itemgetter
%matplotlib inline
Train_data= pd.read_csv(r'D:\ershouche\used_car_train_20200313.csv', sep=' ')
Test_data = pd.read_csv(r'D:\ershouche\used_car_testA_20200313.csv', sep=' ')
Train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
Train_data['notRepairedDamage'].value_counts()
0.0 111361
1.0 14315
Name: notRepairedDamage, dtype: int64
#对偏斜类做删除处理
del Train_data["seller"]
del Train_data["offerType"]
del Test_data["seller"]
del Test_data["offerType"]
Train_data.isnull().sum()
SaleID 0
name 0
regDate 0
model 1
brand 0
bodyType 4506
fuelType 8680
gearbox 5981
power 0
kilometer 0
notRepairedDamage 24324
regionCode 0
creatDate 0
price 0
v_0 0
v_1 0
v_2 0
v_3 0
v_4 0
v_5 0
v_6 0
v_7 0
v_8 0
v_9 0
v_10 0
v_11 0
v_12 0
v_13 0
v_14 0
dtype: int64
1.缺失值的处理
由EDA数据分析,我们可以清楚的知道在我们的缺失数据的变量为bodyType 缺失数为4506 ,fuelType 缺失数为8680;gearbox 缺失数为5981,notRepairedDamage 有24324 种,且其均为分类变量,而gearbox,notRepairedDamage 变量为0,1分类,所以我们可以采取虚拟变量法填补缺失值,同时,在bodytype 和fuelType 变量,其虽为分类变量,但其类别较多,不太适合虚拟变量法,又其含有缺失值的个数分别占全部全部训练集的3.00%,5.787%,所以对于这两个变量我们可以直接采取删除缺失值的方法。
1.1虚拟变量法处理缺失值
虚拟变量
又称哑变量,通常取值为0或1。引入哑变量可以使问题描述更加简明。
pd.get_dummies( )
参数column:欲转换为虚拟变量的指标。
参数prefix:定义列名称bb
#添加虚拟变量
# 将gearbox转化为虚拟变量,添加在Train_data的最后一列
train = pd.get_dummies(Train_data,columns=['gearbox'],
prefix=['gearbox1'],prefix_sep='_')
train['gearbox1'] = Train_data['gearbox']
print(train.isnull().sum())
SaleID 0
name 0
regDate 0
model 1
brand 0
bodyType 4506
fuelType 8680
power 0
kilometer 0
notRepairedDamage 24324
regionCode 0
creatDate 0
price 0
v_0 0
v_1 0
v_2 0
v_3 0
v_4 0
v_5 0
v_6 0
v_7 0
v_8 0
v_9 0
v_10 0
v_11 0
v_12 0
v_13 0
v_14 0
gearbox1_0.0 0
gearbox1_1.0 0
gearbox1 5981
dtype: int64
train1 = pd.get_dummies(train,columns=['notRepairedDamage'],
prefix=['notRepairedDamage'],prefix_sep='_')
train1['notRepairedDamage'] = train['notRepairedDamage']
print(train1.isnull().sum())
SaleID 0
name 0
regDate 0
model 1
brand 0
bodyType 4506
fuelType 8680
power 0
kilometer 0
regionCode 0
creatDate 0
price 0
v_0 0
v_1 0
v_2 0
v_3 0
v_4 0
v_5 0
v_6 0
v_7 0
v_8 0
v_9 0
v_10 0
v_11 0
v_12 0
v_13 0
v_14 0
gearbox1_0.0 0
gearbox1_1.0 0
gearbox1 5981
notRepairedDamage_0.0 0
notRepairedDamage_1.0 0
notRepairedDamage 24324
dtype: int64
del train1['gearbox1']
del train1['notRepairedDamage']
1.2删除缺失值
train2=train1.dropna()
train2.isnull().sum()
SaleID 0
name 0
regDate 0
model 0
brand 0
bodyType 0
fuelType 0
power 0
kilometer 0
regionCode 0
creatDate 0
price 0
v_0 0
v_1 0
v_2 0
v_3 0
v_4 0
v_5 0
v_6 0
v_7 0
v_8 0
v_9 0
v_10 0
v_11 0
v_12 0
v_13 0
v_14 0
gearbox1_0.0 0
gearbox1_1.0 0
notRepairedDamage_0.0 0
notRepairedDamage_1.0 0
dtype: int64
由此,我们可以看到我们已经解决了缺失值的问题。
2.异常值处理
对于上述的,tree数据的生成,我们对power变量做了箱线图异常值处理,但对于箱线图处理,但对于数据不符合正态分布的情况下,箱线图处理,并不完美,而多选择box_cox将非正态分布数据转换为正态分布,或者选择长尾截断的方法。
1.3δ原则,箱线图参考https://blog.csdn.net/xzfreewind/article/details/77014587?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
2. box—cox 变换参考: https://blog.csdn.net/u012735708/article/details/84755595
3.
train2['power'].plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x1099c2c8>

2.1 box_cos 变换
如果数据不满足正态时该怎么办,答案就是将非正态数据通过Box-Cox变换进一步转换成符合正态分布的数据。
Box-Cox变换是多种变换的总称,具体的公式如下:

上面公式中y(λ)表示变换后的值,根据λ的值不同,属于不同的变换,当λ值取以下特定的几个值时就变成了特殊的数据变换:
当λ=0时,Box-Cox变换就变成了对数变换,y(λ) = ln(y);
当λ=0.5时,Box-Cox变换就变成了平方根变换,y(λ) = y^1/2
当λ=1时,Box-Cox变换变换就是它本身,y(λ) = y
当λ=2时,Box-Cox变换就变成了平方变化,y(λ) = y^2
当λ=-1时,Box-Cox变换就变成了倒数变化,y(λ) = 1/y。
λ值取多少,我们可以利用Python中现成的函数,让函数自动去探索,然后返回给我们最优的值是多少就可以。
我们以price为例进行分析,并不是所有的数据都适合做boxcox分析,我有提前用power进行分析,因为power中的数据不全为正数,所以,其会报错: ValueError: Data must be positive. 所以这里我们以之前在数据分析中显示成右偏分布的price为例。当然也可以用for循环对多个变量进行变换。
1.我们先看一下数据的概率密度图
sns.distplot(Train_data["price"],color = "#D86457")

通过上面的概率密度图,我们可以看出这是一份偏态数据,也就是非正态。接下来我们先利用boxcox_normmax函数来寻找最优λ值,代码如下:
from scipy import stats
stats.boxcox_normmax(Train_data["price"])
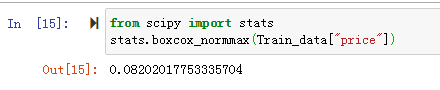
在获得最优λ值以后,我们再利用boxcox函数来进行数据转换,具体代码如下:
x = stats.boxcox(Train_data["price"],stats.boxcox_normmax(Train_data["price"]))
sns.distplot(x,color = "#D86457")

对转换后的数据再次进行概率密度图的绘制,我们可以看到,数据就很正态了。
接下来再来我们再看一下我们计算出来的λ值是不是最优的,具体代码如下:
fig = plt.figure()
ax = fig.add_subplot(111)
stats.boxcox_normplot(Train_data["kilometer"], -20, 20,plot = ax)
plt.axvline(x = stats.boxcox_normmax(Train_data["kilometer"]),color = "#D86457")
plt.show()

中间红色那条线的位置就是我们求出来最优的λ值,结果很吻合。
# box_cos 变换
"""from scipy import stats,special
y = train2['power']
print(y.shape)
lam_range = np.linspace(0,310,100) # default nums=50
llf = np.zeros(lam_range.shape, dtype=float)
# lambda estimate:
for i,lam in enumerate(lam_range):
llf[i] = stats.boxcox_llf(lam, y) # y 必须>0
# find the max lgo-likelihood(llf) index and decide the lambda
lam_best = lam_range[llf.argmax()]
print('Suitable lam is: ',round(lam_best,2))
print('Max llf is: ', round(llf.max(),2))
plt.figure()
plt.axvline(round(lam_best,2),ls="--",color="r")
plt.plot(lam_range,llf)
plt.show()
plt.savefig('boxcox.jpg')
# boxcox convert:
print('before convert: ','\n', y.head())
#y_boxcox = stats.boxcox(y, lam_best)
y_boxcox = special.boxcox1p(y, lam_best)
print('after convert: ','\n', pd.DataFrame(y_boxcox).head())
# inverse boxcox convert:
y_invboxcox = special.inv_boxcox1p(y_boxcox, lam_best)
print('after inverse: ', '\n', pd.DataFrame(y_invboxcox).head())"""
2.2 长尾截断
#power分桶处理
bin = [i*10 for i in range(31)]
train2['power_bin'] = pd.cut(train2['power'], bin, labels=False)
train2[['power_bin', 'power']].head()
print('power变量中31个桶中的个数:')
pd.value_counts(train2['power_bin'])
power变量中31个桶中的个数:
c:\users\administrator\appdata\local\programs\python\python37\lib\site-packages\ipykernel_launcher.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
This is separate from the ipykernel package so we can avoid doing imports until
10.0 17222
7.0 12373
13.0 11572
5.0 10565
14.0 10121
11.0 9251
8.0 8416
16.0 7851
12.0 6516
6.0 5264
17.0 3897
19.0 3323
4.0 3067
9.0 2975
23.0 2331
18.0 2296
15.0 2073
21.0 1945
20.0 1436
22.0 1327
24.0 1010
27.0 759
25.0 424
28.0 409
26.0 384
29.0 363
3.0 207
0.0 72
1.0 31
2.0 14
Name: power_bin, dtype: int64
train2['power_bin'].plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x122dbfc8>

#对分桶之后的power进行长尾截断
train2.ix[train2['power_bin']>25,'power_bin'] = 25
c:\users\administrator\appdata\local\programs\python\python37\lib\site-packages\ipykernel_launcher.py:1: FutureWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
See the documentation here:
http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#ix-indexer-is-deprecated
"""Entry point for launching an IPython kernel.
train2['power_bin'].plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x10c36588>

3.特征构造
#训练集和测试集放在一起,方便构造 _——
train2['train']=1
Test_data['train']=0
data = pd.concat([train2,Test_data],ignore_index=True)
3.1时间特征构造
#找使用时间=creatDate-regDate,数据中出错歌神,用error ='coerce'
data['used_time']=(pd.to_datetime(data['creatDate'],format='%Y%m%d',errors='coerce')-
pd.to_datetime(data['regDate'],format='%Y%m%d',errors='coerce')).dt.days
# 看一下空数据,有 15k 个样本的时间是有问题的,我们可以选择删除,也可以选择放着。
# 但是这里不建议删除,因为删除缺失数据占总样本量过大,7.5%
# 我们可以先放着,因为如果我们 XGBoost 之类的决策树,其本身就能处理缺失值,所以可以不用管;
data['used_time'].isnull().sum()
10500
3.2地理信息特征构造
# 从邮编中提取城市信息,相当于加入了先验知识
data['city']=data['regionCode'].apply(lambda x : str(x)[:-3]) #lambda函数也叫匿名函数,即没有具体名称的函数,它允许快速定义单行函数,可以用在任何需要函数的地方
data=data
3.3 统计量特征构造
## 计算某品牌的销售统计量,同学们还可以计算其他特征的统计量
# 这里要以 train 的数据计算统计量
Train_gb=train2.groupby('brand')
all_info={}
for kind,kind_data in Train_gb:
info={}
kind_data=kind_data[kind_data['price']>0]
info['brand_amount']=len(kind_data)
info['brand_prince_max']=kind_data.price.max()
info['brand_prince_min']=kind_data.price.min()
info['brand_prince_median']=kind_data.price.median()
info['brand_prince_sum']=kind_data.price.sum()
info['brand_prince_std']=kind_data.price.std()
info['brand_prince_averge']=round(kind_data.price.sum()/(len(kind_data)+1),2) #这个地方为什么要加1呢
all_info[kind] =info
brand_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={'index': 'brand'})
train2= data.merge(brand_fe,how = 'left',on='brand')
data.columns
Index(['SaleID', 'bodyType', 'brand', 'fuelType', 'gearbox', 'gearbox1_0.0',
'gearbox1_1.0', 'kilometer', 'model', 'name', 'notRepairedDamage',
'notRepairedDamage_0.0', 'notRepairedDamage_1.0', 'power', 'power_bin',
'price', 'train', 'v_0', 'v_1', 'v_10', 'v_11', 'v_12', 'v_13', 'v_14',
'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'used_time',
'city', 'brand_amount_x', 'brand_prince_max_x', 'brand_prince_min_x',
'brand_prince_median_x', 'brand_prince_sum_x', 'brand_prince_std_x',
'brand_prince_averge_x', 'brand_amount_y', 'brand_prince_max_y',
'brand_prince_min_y', 'brand_prince_median_y', 'brand_prince_sum_y',
'brand_prince_std_y', 'brand_prince_averge_y'],
dtype='object')
# 删除不需要的数据
data = data.drop(['creatDate', 'regDate', 'regionCode'], axis=1)
4.特征归一化
4.1.Rescaling(最小最大归一化,不免疫outlier)
(1)将训练集中某一列数值特征(假设是第i列)的值缩放到0和1之间
x'= x - np.min(x)) / (np.max(x) - np.min(x))
适用场景:
如果对输出结果范围有要求,用归一化
如果数据较为稳定,不存在极端的最大最小值,用归一化
我们对数值型数据(除去匿名特征),以及构造的brand的统计量特征做归一化处理。
train2['kilometer'].plot.hist()
<matplotlib.axes._subplots.AxesSubplot at 0x22f42108>

train2['kilometer']=((train2['kilometer']-np.min(train2['kilometer']))/(np.max(train2['kilometer'])-np.min(train2['kilometer'])))
train2['kilometer'].plot.hist()

dt=['power_bin', 'brand_prince_max', 'brand_prince_min', 'brand_prince_median',
'brand_prince_sum', 'brand_prince_std', 'brand_prince_averge','brand_amount']
print('联合归一化直方图')
for ct in dt:
train2[ct]=((train2[ct]-np.min(train2[ct]))/(np.max(train2[ct])-np.min(train2[ct])))
train2[ct].plot.hist()
联合归一化直方图

4.2Standardization(标准化/z-score标准化,不免疫outlier)
将训练集中某一列数值特征(假设是第i列)的值缩放成均值为0,方差为1的状态。
x'=(x-x均值)/ 标准差
适用场景:
SVM、LR、神经网络
如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响
中的来讲3.2的方法更为优秀。
# 方法1
from sklearn.proprocessing import scale
df_train['feature'] = scale(df_train['feature'])
# 方法2
# 一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化器去标准化test集,此时可以用scaler
from sklearn.proprocessing import StandardScaler
scaler = StandardScaler().fit(df_train)
scaler.transform(df_train)
scaler.transform(df_test)
% 如果对输出结果范围有要求,用归一化
%如果数据较为稳定,不存在极端的最大最小值,用归一化
%如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响
我比较建议先使用标准化。
5. one hot 独热编码
1.one-hot
如果类别特征本身有顺序(例:优秀、良好、合格、不合格),那么可以保留单列自然数编码。如果类别特征没有明显的顺序(例:红、黄、蓝),则可以使用one-hot编码:
作用:将类别变量转换为机器学习算法容易处理的形式
为什么one-hot编码可以用来处理非连续(离散)特征?
在使用one-hot编码中,我们可以将离散特征的取值扩展到欧式空间,在机器学习中,我们的研究范围就是在欧式空间中,首先这一步,保证了能够适用于机器学习中;另外对于one-hot处理的离散的特征的某个取值也就对应了欧式空间的某个点.
# 对类别特征进行 OneEncoder
data = pd.get_dummies(data, columns=['model', 'brand', 'bodyType', 'fuelType',
'gearbox', 'notRepairedDamage'])
data
| SaleID | gearbox1_0.0 | gearbox1_1.0 | kilometer | name | notRepairedDamage_0.0 | notRepairedDamage_1.0 | power | power_bin | price | ... | fuelType_2.0 | fuelType_3.0 | fuelType_4.0 | fuelType_5.0 | fuelType_6.0 | gearbox_0.0 | gearbox_1.0 | notRepairedDamage_- | notRepairedDamage_0.0 | notRepairedDamage_1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1.0 | 0.0 | 0.827586 | 736 | 1.0 | 0.0 | 60 | 5.0 | 1850.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1.0 | 0.0 | 1.000000 | 2262 | 0.0 | 0.0 | 0 | NaN | 3600.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | 1.0 | 0.0 | 0.827586 | 14874 | 1.0 | 0.0 | 163 | 16.0 | 6222.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 3 | 0.0 | 1.0 | 1.000000 | 71865 | 1.0 | 0.0 | 193 | 19.0 | 2400.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | 1.0 | 0.0 | 0.310345 | 111080 | 1.0 | 0.0 | 68 | 6.0 | 5200.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 189232 | 199995 | NaN | NaN | 15.000000 | 20903 | NaN | NaN | 116 | NaN | NaN | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 189233 | 199996 | NaN | NaN | 15.000000 | 708 | NaN | NaN | 75 | NaN | NaN | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 189234 | 199997 | NaN | NaN | 15.000000 | 6693 | NaN | NaN | 224 | NaN | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 189235 | 199998 | NaN | NaN | 15.000000 | 96900 | NaN | NaN | 334 | NaN | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| 189236 | 199999 | NaN | NaN | 9.000000 | 193384 | NaN | NaN | 68 | NaN | NaN | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
189237 rows × 349 columns
我们可以看到所有的分类数剧进行了自编码
data.isnull().sum()
SaleID 0
gearbox1_0.0 50000
gearbox1_1.0 50000
kilometer 0
name 0
...
gearbox_0.0 0
gearbox_1.0 0
notRepairedDamage_- 0
notRepairedDamage_0.0 0
notRepairedDamage_1.0 0
Length: 349, dtype: int64
# 这份数据可以给 LR 用
data.to_csv('D:/ershouche/data_for_lr.csv', index=0)
总结
对于线性模型的构造,我们是在除去其缺失值的基础上,进行了,忽略对匿名特征的的处理。
首先,我们针对非正态分布数值型数据,进行异常值删除的过程,选择了长尾截断,当然box-cox转换也是很好的处理方法,本文已经给到了相应的代码与原理。
其次,我们对于数据中含有的数值型数据做了归一化处理,在线性问题处理过程中归一化后加快了梯度下降求最优解的速度且归一化有可能提高精度。本文给到了归一化处理,标准化的方法,当然最推荐的还是3.2里面的z-score标准化,其不用考虑极大值极小值的影响,适用范围广,性能更好一些。
https://www.zhihu.com/question/20455227/answer/370658612
最后我们选择对分类型数据进行独热编码处理其将多类别数据二值化,更有利于对之后模型的建立。下面是关于自编码的相关内容,可借以参考。
