本章的内容包括delete
- 创建和使用数组;
- 创建和使用c风格字符串;
- 创建和使用string类字符串;
- 使用方法getline()和get()读取字符串;
- 混合输入字符串和数字;
- 创建和使用结构;
- 创建和使用公用体;
- 创建和使用枚举;
- 使用new和delete管理动态内存。
- 创建动态数组;
- 创建动态结构;
- 自动储存、静态储存,和动态储存。
- vector 和 array简介;
数组:
要创建数组,一般应该指出如下三点:
1.数组类型
2.数组名
3.数组的
例如:

数组下标的重要性:因为编译器不会检查下标是否有效,所以将一个值赋给不存在的元素编译器不会指出错误;
sizeof运算符:返回数据类型或对象长度;如果将sizeof用于数组名,得到的是整个数组中的字节数,如果用于数组元素得到将是元素的长度;
下面是数组初始化的一些过程:
1.只有定义数组时才能将其初始化,过后就不行了,也不能将一个数组赋值给另一个数组;然而可以使用下标分别给数组元素赋值;
2.如果只对数组初始化一部分,则编译器将把其他元素设置为0;
如果我们要将所有元素初始化为0;我们只需要将第一个元素设置为0即可;
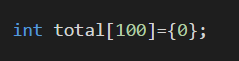
3.如果,我们像下面这样,编译器将自动计算元素个数;
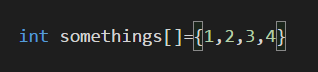
如果我们有很多元素,我们又具体想知道,具体有多少元素,显然我们不会一个个数,我们可以使用sizeof运算符;

C++11中数组初始化:
1.初始化数组是可以省略 = 这个符号;

2.可以在大括号中不包含任何东西,编译器将所有的元素都设置为0;
字符串:
字符串是存储在内存中连续的一系列字符。
c++处理字符串的方式有两种:1.C-风格字符串 2.string类;
下面先来介绍C-风格字符串:
C风格字符串是以空字符(null character)结尾的,空字符被写作 \0,其ASCII码为0;
下面我们看两个声明:
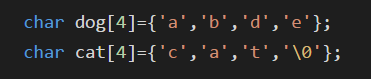
其中 cat数组为字符串。下面我们用cout来输出这两个数组看下效果如何:

我们发现dog数组出现乱码:出现乱码的原因是因为系统没有找到结束符,
因为C和C++不进行数组的边界检查,数组在内存中存放的只是所有数组元素的值,而不存在一个地方可以表示数组的大小.所以cout函数没法知道该输出多少个元素。如果我们将数组dog数目4改成5的话,输出效果如下:

因为编译器把第五个元素默认为\0,所以此时dog数组表示的也是字符串;
像上述的将数组初始化为字符串显得十分麻烦,下面更好的方法。
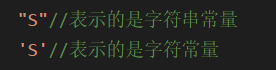
只需要使用一个引号将字符串括起即可,这样的字符串称为字符串常量(string constant)或者字符串字面值(string literal)
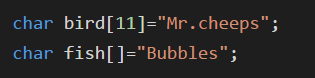
用括号括起的字符串隐式的包括结尾的空字符;
我们我们尽量的保证数组足够大,有时候我们自己输入数组元素是,可能会造成空间浪费,所以尽量使用第二种方式;
下面我们区分:字符串常量于字符常量
字符串拼接:
两个引号括起来的字符串将拼接成一个,事实上有任何两个空白(空格、制表符、换行符)分隔的字符串常量将自动拼接成一个,拼接是不会添加空格;
在数组中使用字符串:
主要有两种方法:1.将数组初始化为字符串常量,将键盘输入到数组中;
下面以一个程序:
#include "iostream"
using namespace std;
int main()
{
const int Size=15;
char name1[Size];
char name2[Size]="C++owboy";
cout<<"Howdy! i'm "<<name2;
cout<<"! What's your name?\n";
cin>>name1;
cout<<"Well, "<<name1<<" ,your name has ";
cout<<strlen(name1)<<" of letters and is stored\n";
cout<<" in an array of "<<sizeof(name1)<<" bytes.\n";
cout<<"Your initial is "<<name1[0]<<endl;
name2[3]='\0';
cout<<"Here are the first 3 characters of my name: ";
cout<<name2<<endl;
return 0;
}
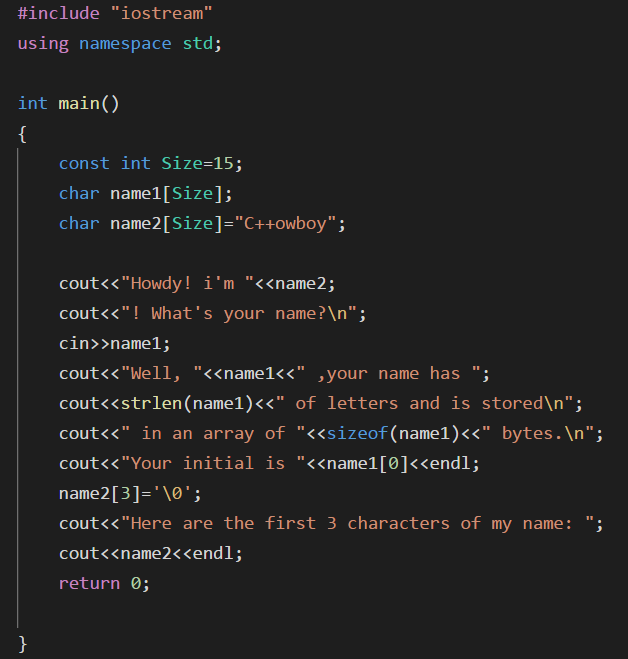
该程序使用了上述两种方法,其中strlen()不计算空字符,他返回的是字符串长度而不是数组本身长度。如果我们将一个字符串的前面某位用空字符将其替换,那么输出只能是第一个空字符前的字符。这很好的解释了cout在输出字符串是遇到空字符时,停止输出;
上一个程序中,是有缺陷的,我们通过一个例子来观察一下:
#include "iostream"
using namespace std;
int main()
{
const int ArSize=20;
char Name[ArSize];
char Dessert[ArSize];
cout<<"Enter your name: "<<endl;
cin>>Name;
cout<<"Enter your fevorite dessert: "<<endl;
cin>>Dessert;
cout<<"I have some delicious "<<Dessert;
cout<<" for you,"<<Name<<endl;
return 0;
}
下面是运行结果:
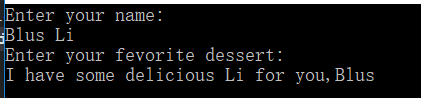
还没来得及输入第二个数组内容程序已经完了;
原因如下:cin使用空白来确定字符串的结束位置,这意味着前一个数组只读取了一个单词,后面的保留在输入队列中,然后cin在输入队列中搜索第二个数组内容时发现了第二个单词;
解决办法:每次读取一行字符串输入,使用面向行的输入方法;
get()函数,getline()函数;这两个函数读取一行,直达到达换行符,然而getline()将丢弃换行符,而get()将保留换行符在输入丢列中。
getline()函数的使用:它通过使用换行符来确定输入结尾,cin.getline(A,20)该函数带两个参数,第一个是数组名称,第二个是要读取的字符数(包括空字符);相反在存储字符串时它他用空字符来替换换行符;
get()函数:get()函数保留空行符,所以在连续输入时,它不能跨越空行符,但get()函数有一种变体就是,不带任何参数的get()可读取下一个字符,即使是空字符;cin.get(A,20)用法同上;
get()于getline()的分别的优点:getline()函数相对较简单方便,而get()函数,我们知道读取的原因,如果读取到下一个字符不是换行符,那说明是数组被填满,而不是输入了完整的一行;
当读取到空行时,get()函数将设置失效位(failbit),这将意味着接下来得输入将被阻断,但可以使用下面的命令来恢复输入;
另一个问题,如果输入的过长,get(),和getline()会将剩下的保留到出入队列中,而getline()还会设置失效位,并关闭后面的输入;
修改程序后:
#include "iostream"
using namespace std;
int main()
{
const int ArSize=20;
char Name[ArSize];
char Dessert[ArSize];
cout<<"Enter your name: "<<endl;
cin.getline(Name,21)//or cin.get(Name,21).get()
cout<<"Enter your fevorite dessert: "<<endl;
cin.getline(Name,21);//or cin.get(Dessert,21)
cout<<"I have some delicious "<<Dessert;
cout<<" for you,"<<Name<<endl;
return 0;
}
string类简介:
要使用string类,必须包括相应的头文件,string类位于名称空间std中;
使用string跟使用字符数组类似:
- k可以使用C-风格字符串来初始化string
- 可以使用cin来从键盘上获得输入
- 可以使用cout来显示string对象
- 可以使用数组表示法来访问储存在string对象中的内容;
主要区别:
- 可以将string对象声明为简单的变量;
- 程序能自动处理string类的大小;
- 可以将一个string对象赋值给另一个string对象;
- 可以使用=号赋值,+号进行拼接;
在c语言中,可以使用strcpy()函数将字符串复制到字符数组中,使用strcat()将字符串附加到字符数组中;
但是不能避免,赋值的时候超出字符数组的大小,.......c进而又提供了这两个函数的变体 strncpy(),strcncat(),它们接受指出目标数组最大允许长度的第三个参数;
下面看一个例子:
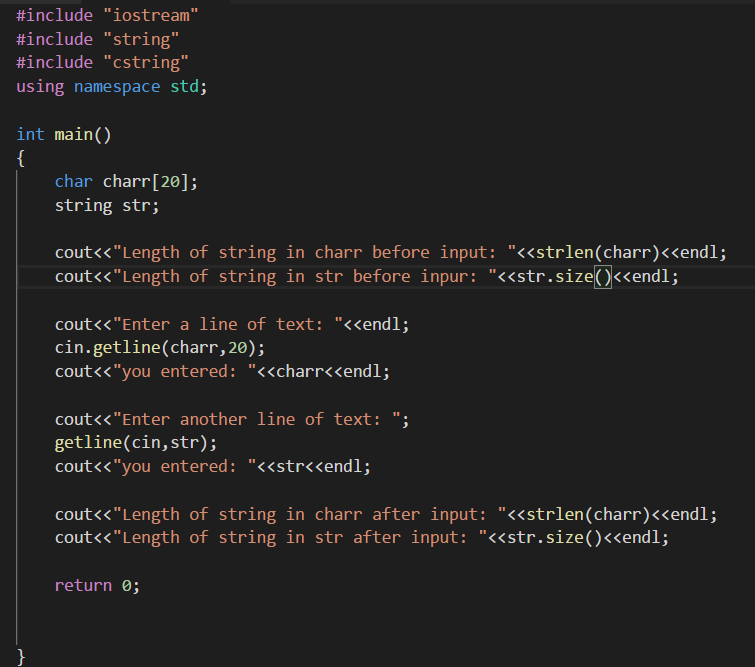
下面是该程序的运行情况:

未初始化的数组内容是未定义的,函数strlen()从一个元素开始计算,直到遇到空字符。所以在没有初始化使用strlen()来确定字符串数组的大小,返回值时不确定的,而 string未被初始化之前是为0的;
在输入一行文字它们使用的getline函数时不一样的;
其他形式的字符串字面值:
c++分别使用前缀L、u、U来表示 wchat_t,char16_t,char32_t;
例如:
wchat_t title[]=L"egjffe";
原始字符串:
在原始字符串中,字符表示的是自己;原始字符串将用"( )"作为界定符,并使用前缀R来标志原始字符串;
如果我们需要直接输入 "( ,但是他会作为界定符,此时我们可以采取一种填充的方法
我们可以在 " (之间假如其他字符,相应的 " )之间也要对应的添加;
结构体:
结构是用户定义的类型,而结构声明定义了这种类型的数据属性。
struct inflatable
{
char name[20];
float volume;
double price;
}
关键字struct表明,这些代码定义的是一个结构的布局,而标志符inflatable是这种数据格式的名称,因此新类型的名称为inflatable;
创建结构体变量:
struct inflatable A; 在c语言中 struct 是不能省略的,
inflatable B; 而在c++中是可以省略的;
可以使用成员云算法来访问个个成员:A.volume;
结构体的初始化:
inflatable c=
{
"keugf",
1.45,
254.3,
};
每个成员用逗号隔开,也可以把他们放在同一行;
其中=也是可选的;可以将一个结构赋值给另一个同类型的结构;
也可以同时完成定义结构和创建结构变量;
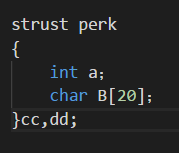
还可以同时完成初始化:
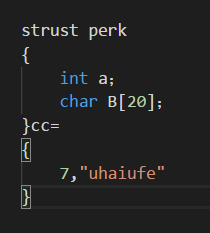
还可以创建没有名称的结构体,但是之后便不可以创建这种结构体;
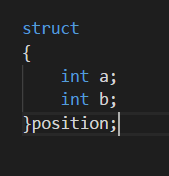
还可以创建结构体数组:
inflatable alife[20];
共用体:
共用体(union)是一种数据格式,它能够储存不同的数据类型,但同时只能储存一种数据类型;
由于共用体每次只能储存一个值,因此他必须要有足够大的空间来储存最大成员,因此共用体的长度为其最大成员的长度;
共用体的类型之一就是,当数据项使用两种或更多种格式(但不会同时使用时),可节省空间;
下面是一个例子:管理一个小商品目录,其中有一些商品的ID为数字,一些商品的ID为字符串;
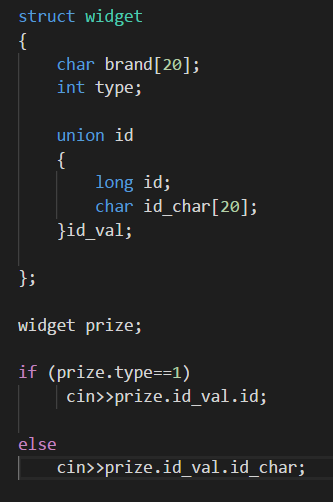
下面介绍一下匿名(anonymous union)共用体:
匿名共用体没有名称,其成员将位于但同地址处的变量,显然每一次只有一个成员是当前的成员;
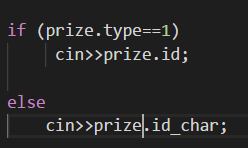
枚举:
c++的enum工具提供了另一种创建符号常量的方式,这种方式可以代替const。还允许定义新类型;
来看下面这条语句:

这条语句完成两项工作;
1.让alph称为新类型的名称;
2.将A,B,C..等作为符号常量,他们对应的数值为0~5;第一个枚举量为0,以此类推;
我们可以显示的指定整数值来覆盖默认值;
在不进行强制类型转换时,只能将定义枚举时使用的枚举量赋值给这种枚举量;
对于枚举只定义了赋值运算符,没有定义算术运算;
枚举量整型,可被提升为Int类型,但int类型不能被提升为整型;
设置枚举的值:
1.可以使用赋值运算符显示的来设置枚举的值

2.也可以显示的定义一些值;

其中first默认值为0,没有被初始化的值默认地比前面大1;
3.最后可以创建多个值相同的枚举量;

其中前面两个为0;后面两个为一;
枚举的取值范围:
每个枚举都有取值范围,通过强制类型转换,可以将取值范围中的任何整数赋给枚举变量,即使这个值不是枚举值;
取值范围的定义如下:
首先需要找出上限,要知道枚举量的最大值,找到这个最大值的、最小2的幂在减去1,得到的便是取值范围的上限;
要计算下限,要知道枚举量的最小值,如果这个值不小于0,则取值范围的下限为0;否则采取于上限相同的方式,但不是减一而是加一;
指针和自由储存空间:
指针是一个变量,储存的是值的地址,而不是值本身;
变量运用地址运算符(&)可以获得它的位置;
*运算符被称为间接值(indirect velue)或解除引用(dereferencing)运算符,将其应用于指针,可得到改地址处的值;
计算机需要指向指针指向值类型,所以指针声明必须指定指针指向的数据类型
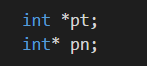
这两种声明所强调是不一样的;
第一个强调 *p是一个Int类型的值;
第二个强调的是 pn是一个Int类型的指针;
要注意的一点是:
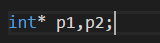
这并不是声明了两个Int类型的指针,而是声明了:p1是int类型的指针,而p2是一个int类型的变量;
对于声明为指针的每一个变量都需要使用*;
使用指针的危险:
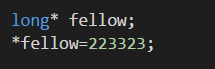
像上面这两个语句,由于fellow没有被初始化,所以它的值我们是不知道的;所以我们一定要在对指针应用解除引用运算符之前,讲指针初始化为一个确定的适当的地址;
指针和数字:
不能将整数赋给指针,应通过强制类型转换;
使用new来分配内存:
在运行阶段分配未命名的内存以存储值,这种情况下,只能通过指针来访问内存;
在c语言中可以通过库函数malloc()来分配内存;在c++中仍然可以这样做,但是c++有更好的办法,使用new运算符;
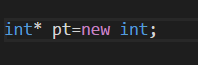
程序员要告诉new,需要为那种数据类型分配内存,new将找到一个长度正确的内存块,并返回该内存块的地址;
new int告诉程序,需要适合存储int 的内存,new根据类型来确定需要多少字节的内存,它找到这样的内存并返回其地址;
new分配的内存块通常与常规变量声明的内存块不同,常规变量的的值都储存在称为栈(stack)的内存区域中,而new从被称为堆(heap)或者自由储存区(free-store)的内存区域分配内存;
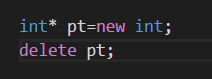
使用delete来释放内存:
使用完内存后,使用delete能将内存归还给内存池,使用delete时,后面要加上指向内存块的指针;
释放指向的内存,并不会删除指针本身。例如可以将指针重新指向一个新分配的内存;
一定要配对的使用 new和delete;否则将发生内存泄漏(memory leak);
不要尝试释放已经释放的内存块;
使用new来创建动态数组:
在编译时给数组分配内存称为静态联编(static binding)意味着数组是在编译时加入到程序的;但是使用new时,如果在运行阶段需要数组,则创建它,如果不需要则不创建,可以在程序运行时选择数组长度;这称为动态联编(dynamic binding)

元素返回第一个元素的地址,该地址被赋值给psome指针;
若用完是,使用delete释放内存:
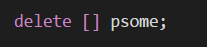
其中方括号告诉程序,释放的是整个数组而不是仅仅指针指向的元素;
在上面中我们指出元素个数为10的意义:因为我们psome指向的是第一个元素,而我们需要跟踪的是整个数组;
使用动态数组:
只要把指针当成数组名使用即可;(因为c,c++内部是使用指针来处理数组的)
另外数组名是不能修改的,而指针是变量,所以可以修改指针的值;
下面是一个例子:
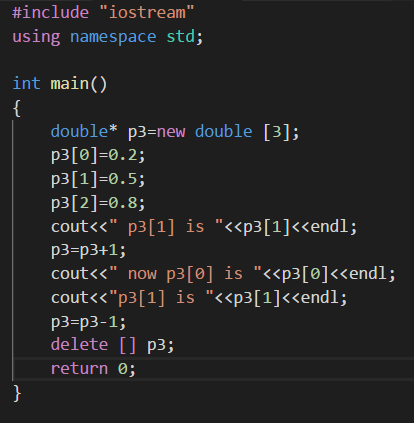
程序将指针的值加1,是指针指向数组的第二个元素;
下面是输出结果:
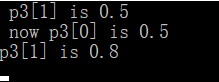
使用New来创建动态结构:
要使用new用于结构一般包括两步:创建结构和访问其成员;
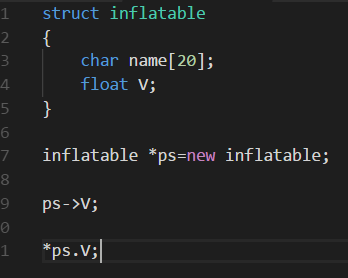
第一种访问方式:由于ps为结构的地址,c++专门为这种情况提供了一个运算符,叫箭头成员运算符;
第二种访问方式:由于*ps就是被指向的值,也就是结构本身,所以可以直接用成员运算符;
自动储存,静态储存,动态储存:
自动储存:函数内部定义的常规变量使用自动储存空间,被称为自动变量(automatic variable),这意味着他们在函数被调用时产生,在函数消亡是结束,其作用域一般在一个代码块中;通常储存在栈中,这意味着执行代码块是依次将其中的变量加入到栈中,离开代码块时,按相反顺序释放这些变量;
静态储存:整个程序执行中都存在的储存方式,使变量称为静态的方式一般有两种;
1.在函数体外面定义它;
2.使用static关键字;
动态储存:new delete他们管理一个内存池,该内存池中的静态变量和自动变量的内存是分开的;
数组的替代品:vector array
vector:类似于string也是一种动态数组
声明方式如下:
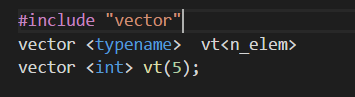
array:array对象的长度也是固定的,也是使用栈来管理;
声明方式如下:
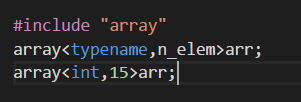
但是数组不能赋值给另一个数组,但是array可以;