认识
pandas是python第三方库,提供高性能易用数据类型和分析工具。
它引入了series和DataFrame两个数据类型。
series 索引+ 一维数据
DataFrmae 索引+ 二维数据
pandas的设计初衷,在于希望建立起数据与索引的对应关系,通过操作索引就能变相操纵数据,而不用关心数据的纬度,减轻思考负担。
pandas希望用户能像对待单一数据一样对待series和DataFrame对象。
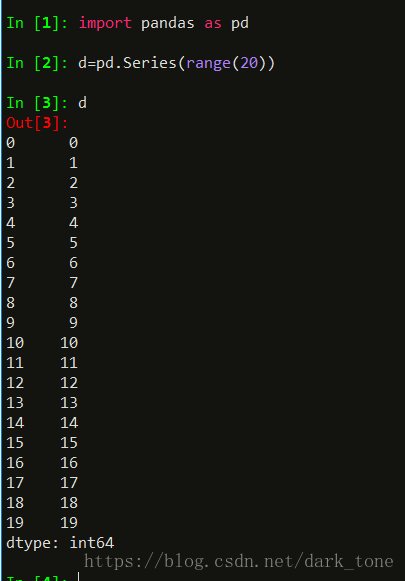
数据有两列,左边的是索引,右边的数据。
对比一下Numpy 与 Pandas
前者更关注一组数据的结构表达,即数据的纬度。后者更关注数据的应用表达。
创建
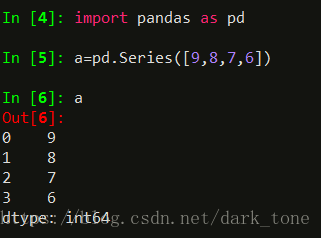
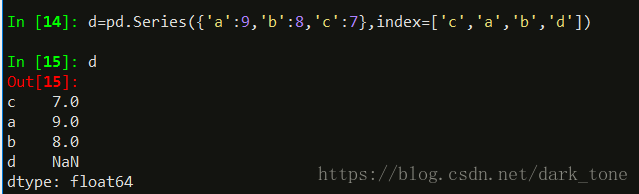
还可以使用index=[]形式来指定索引。
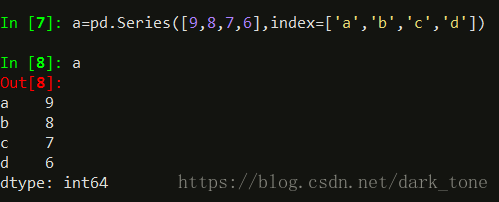
Series可以由如下类型创建
python列表,python字典,标量值(一个值),ndarray,其他函数。
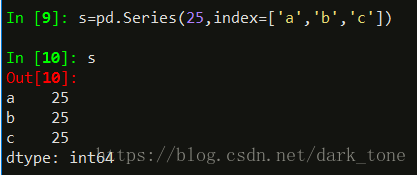
标量值创建:
与字典类型非常相似,创建,键就是索引:
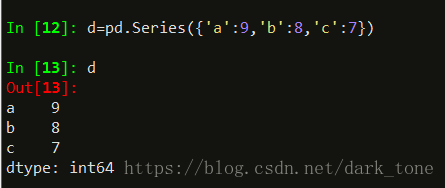
当指定的索引,与字典创建的索引不同时,两者会自动合并,‘d’索引没有对应的值,以NAN标记,其他的值都由int64变成了float64,因为pandas基于Numpy,Numpy默认就是浮点数。
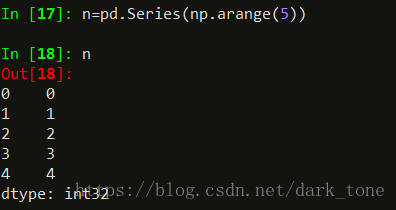
从ndarray类型创建
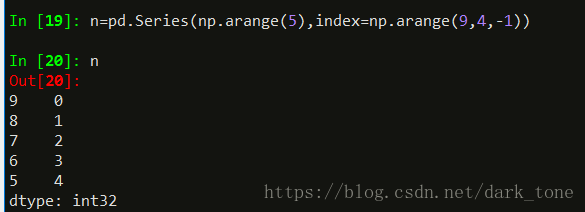
不仅值可以由ndarray类型创建,索引也可以由ndarray类型创建:
基本操作
因为series类型包括index和values两部分,所以其操作也可以归纳成这两部分,和ndarray类型,字典类型相似。
index关键字可以省略。
对于一个series类型,通过.index获得索引,类型名字叫做‘index’.values获得数据,array表明是numpy类型:
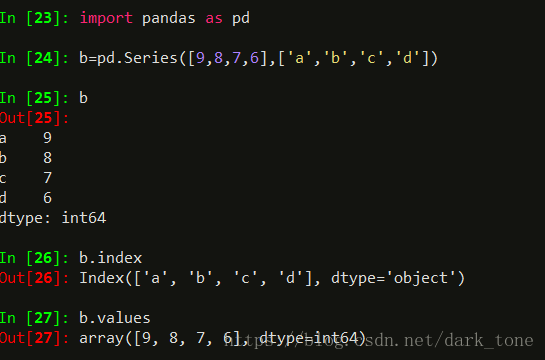
通过这个测试揭露了pandas的本质,值部分就是numpy类型,单独新建了一个索引与值关联,两者结合到一起,就是series类型。
或者可以把pandas理解成一种“新字典”,key 就是自动新建的索引,values就是numpy。
顺理成章,能够直接通过key获得values:
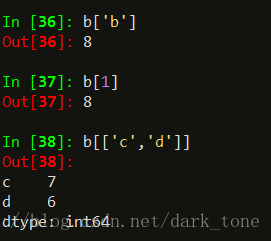
注意series类型就算用户自定义了索引,其默认的索引也自动生成,所以可以通过b[1]获取值,但是这两种索引不能混合使用;而在获取多个values时,key要用,号和[]号再次标记。
切片操作:
可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
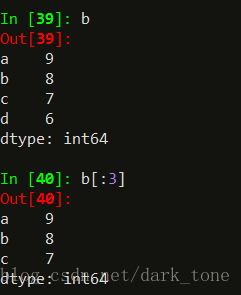
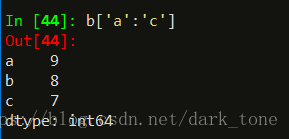
区别在于,如果用自定义索引切片,包括最右边,‘c’索引依然被切片
判断一个自定义索引是否在series类型中,用关键字in,in不会判断自动索引:
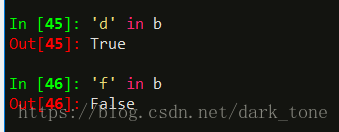
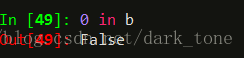
也可以用get()方法获取values:
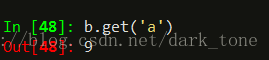
Numpy中的运算和操作可用于series类型。
两个series类型合并,即series+series,自动对齐操作:
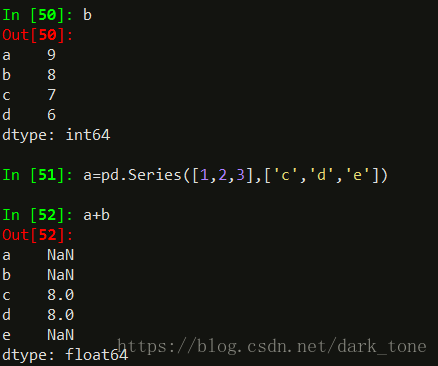
索引值相同的值进行运算,索引不同的值置为NaN.
Series对象和索引都可以有一个名字,存储在属性.name中
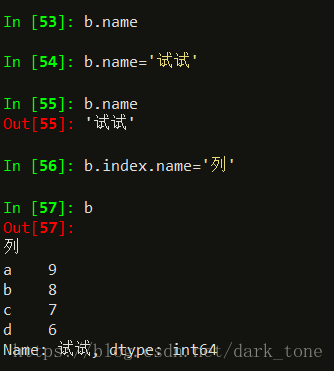
默认的时候,b是没有额外名字,b.name无显示。可以指定series对象的名字,和索引的名字。
修改值注意,只需要一个[],和返回值不同。
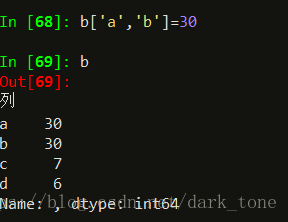
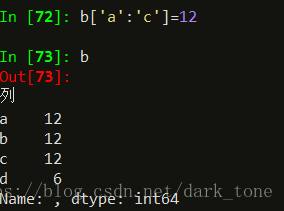
怎么修改series的索引呢?
我暂时只知道可以用.index重新赋值:
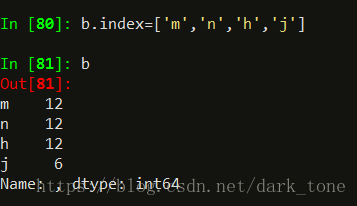
感觉还是不太方便,如果我只想修改其中一个索引,要全部重新赋值??比如只想把‘h’修改为‘t’,其他不变,不知道能不能指定修改?