文章目录
0 写在前面
材料源自某高校课程ppt,恕不共享
1 推荐书籍
关于强化学习推荐的经典书籍有两本,如下:
- An Introduction to Reinforcement Learning, Sutton and Barto, 1998
- Algorithms for Reinforcement Learning, Szepesvari
2 入门简介
2.1 机器学习
强化学习是机器学习的一个特殊分支,通常意义上,机器学习分类监督、非监督和强化学习,所以强化学习有时又叫半监督学习,关系如下图:

2.1 RL的特点
RL的特点主要体现在:
- 没有supervisor,只有reward信号
- 反馈不是及时的,而是延迟的
- 具有时间关联性,顺序的而不是i.i.d(独立同分布)
- agent(智能体)的action会影响它之后接收的的data
2.3 实例
应用RL的实例有很多,具体如:
- 直升飞机的特技表演(stunt manoeuvre),参考b站
- 棋类:Backgammon
- 双足机器人行走
- atari
3 rewards
reward定义为一个标量反馈信号,表示agent在t时刻时的表现,而agent的工作是使累积的reward最大化,RL就是基于这种奖励假设(reward hypothesis)
3.1 奖励假设
即RL任务中所有的目标都等价于期望的累积奖励的最大化。
All goals can be described by the maximisation of expected cumulative reward
3.2 举例
比如在双足机器人行走任务中,每个time step(时间步)机器人能够成功前进就加一个正值的奖励,如果倒了就加负奖励,持续循环,直至累积的奖励最大化。
4 Sequential Decision Making(序列决策制定)
我们的目标既然是使累积的奖励最大化,那么就得考虑以下几种情况:
- 即agent(智能体)每步的action可能会有一个长远的效果(consequences)
- 奖励可能延迟
- 可能牺牲短期奖励会得到更大的长远奖励,反之也可能得到短期奖励会失去长远奖励。
4.1 两个基本问题
这里必须将RL与规划(planning)的区别理清楚。
4.1.1 强化学习
RL中:
- 环境一开始未知
- agent会与环境互动
- agent会不断提高策略(policy)
4.1.2 规划
- 环境已知
- The agent performs computations with its model (without any external interaction)
- agent也会不断提高策略(policy)
- a.k.a. deliberation, reasoning, introspection, pondering, thought, search
5 智能体与环境
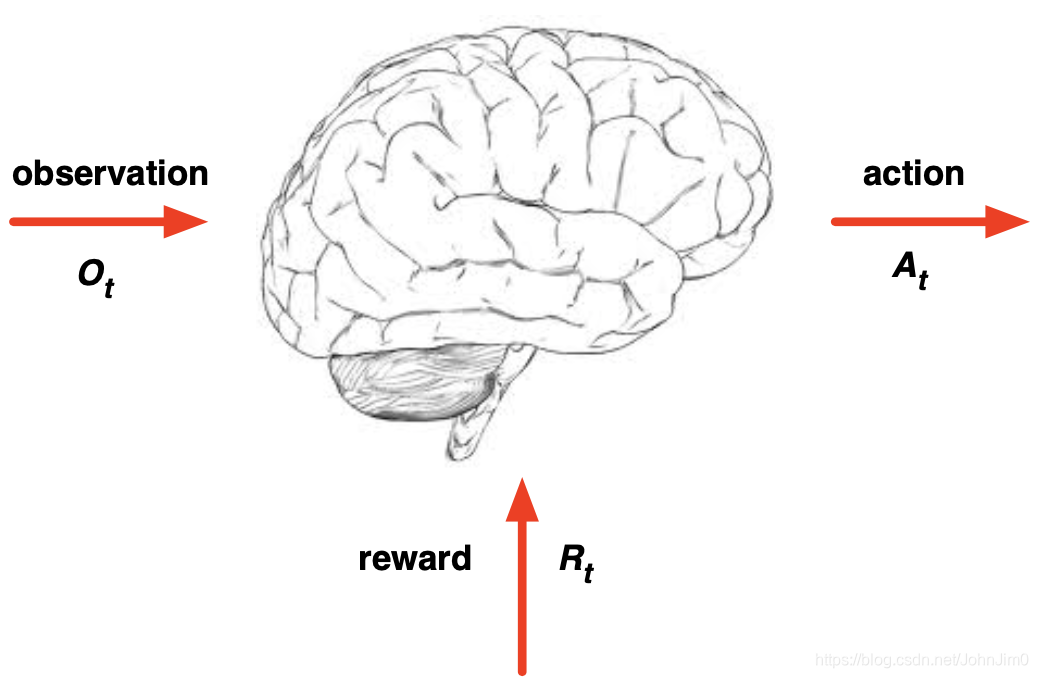
图中大脑表示智能体(agent),在每个time step中,
-
agent
1)执行action
2)接收observation -
env(环境)
1)接收action
2)反馈下一步的observation
3)反馈下一步的reward
6 History and State
6.1 history
即包含observation,actions,rewards的序列,比如截止到t时间的所有可观测变量
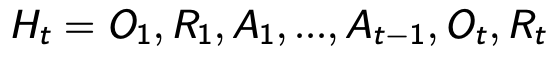
依赖于history,agent会选择下一步的action,而env会选择或者反馈observation或reward
6.2 状态(state)
即决定接下来发生什么的信息,是history的函数

同样环境和智能体都有各自的状态
- env state
1)env用来选择下一步observation/reward的data
2)env state通常对agent不可见
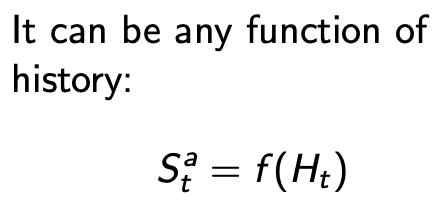
- agent state
1)即agent用来选择下一步action的信息
2)也是RL算法使用的信息
7 信息状态(马尔可夫状态)
a.k.a.(also known as) Markov state, 即从history中包含的所有有用信息
7.1 定义
马尔可夫属性的充要条件如下:
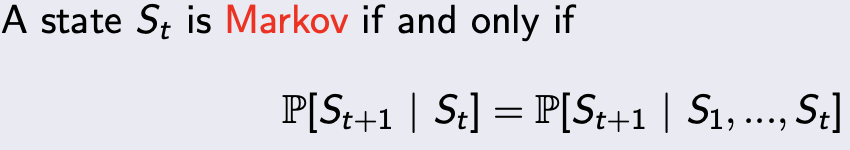
- 即未来的state只跟当前的state有关
- 当state具有M属性,env state和history都可以推出具有markov属性
8 env(环境)
环境分为两种,一种全部可观测的,一种部分可观测的
8.1 Full Observable Environments
Full observability的意思就是agent directly observes environment state, 即env state对agent完全可见。 此时, Agent state = environment state = information state:
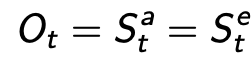
8.2 Partially Observable Environments
Partial observability的意思就是 agent indirectly(间接) observes environment,这种情况比较常见比如
- 一个只带有相机的robot能看见前方的视觉信息,却不能准确获取环境中的位置
- 打牌游戏中我们只能看见牌面上的牌。
对应地在这种环境下,agent state ̸= environment state,相应地决策就是partially observable Markov decision process (POMDP)
并且由于agent state不等于env state了,所以必须有另外的表示方式,此处三处例子:
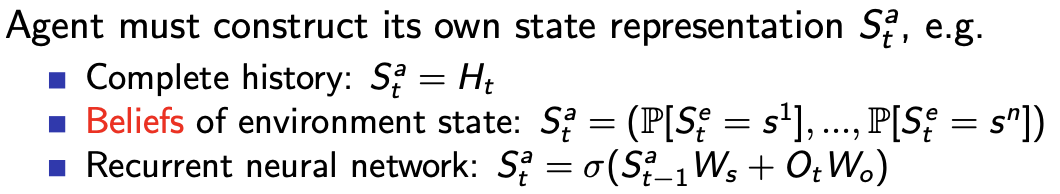
9 RL智能体
9.1 组成成分
一个RLagent必须至少包含以下一种component
-
Policy
即 agent’s behaviour function -
Value function
即how good is each state and/or action -
Model
agent’s representation of the environment
9.2 policy
即agent’s behavior,是state到action的map(映射),或者说每个time step根据当前状态需要执行的action,通常分为两类:
- Deterministic policy
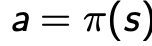
- Stochastic policy
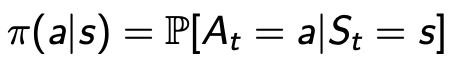
9.3 值函数
即对未来奖励的预测,来评估这些状态的好坏,常见的值函数形式如下::
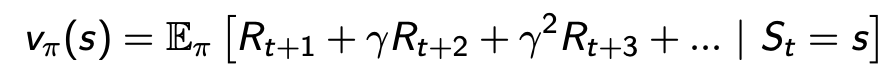
9.4 Model
即用来预测环境下一步变化的模型
9.5 迷宫(maze)示例

如图是一个迷宫,**智能体(agent)**需从start位置走到goal位置,那么它的actions就是上,下,左,右这四个动作,states就是当前所在的位置坐标,在每个time step中,agent移动一格,由于我们通常需要最短完成走迷宫的任务,我们可以设置经过每个time step就给一个-1的reward。
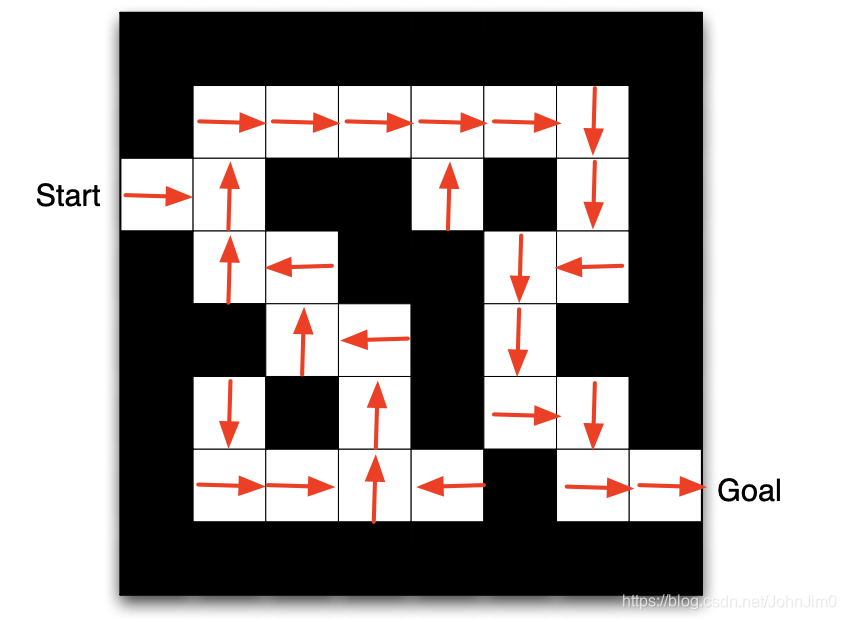
如上图表示了一个policy,即根据当前的state(也就是位置)所要采取的action(箭头所指的方向),为了寻找最优策略,我们需要value function来表示,即每个state对应不同的值,如下

一个常见的思路就是每次选择value最小的state作为下一步的state并执行相应的action,如下:
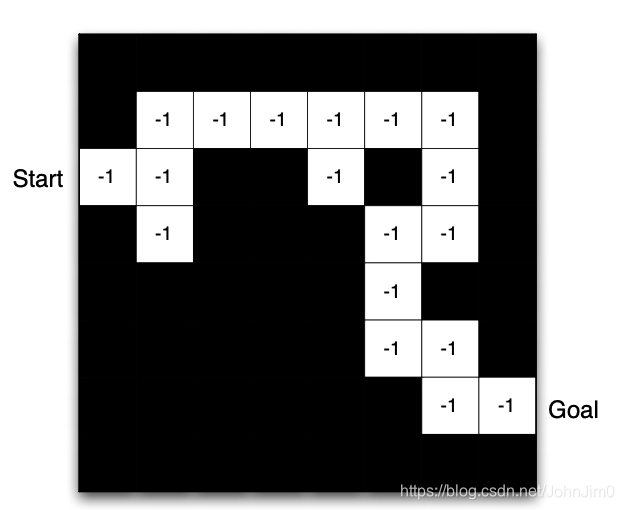
这就是一个可能的最优策略,目前只讲action,reward,policy这些基本概念,至于如何完成这个过程,可参见第2课马尔可夫决策过程。
9.6 智能体分类
RL智能体通常有两种分类方式,第一种如下:
-
Value Based
No Policy (Implicit)
Value Function -
Policy Based
Policy
No Value Function -
Actor-Critic
Policy
Value Function
第二种如下:
-
Model Free
Policy and/or Value Function
No Model -
Model Based
Policy and/or Value Function
Model
10 探索与利用
RL就像试错学习(trial-and-error learning),智能体需要根据在环境中的经验找到最佳策略,并且保证不失掉太多的奖励。其中探索(Exploration) 意思是寻找环境中的更多信息,利用(Exploitation) 则利用探索到的已知信息是奖励最大化,这两者通常同等重要。
比如选择餐馆时,去一家新的参观就是探索,选择你最喜欢的就是利用过程。
11 预测与控制
**预测(prediction)**即给定一个策略来评估未来的动作等,**控制(control)**即寻找一个最佳策略来使未来的动作最优化。这个概念了解即可。
