摘要
【隐语义模型】doc query 向量相似度
【DSSM】提出的一个判别模型(所以学习思路为:条件分布、模型参数后验概率最大、(似然函数· 参数先验)最大、最大似然)
【Word hashing】提出的一种可以处理海量数据的方法
简介
传统检索场景下的匹配方法:
一、词汇层面的匹配(字面匹配)
- 代表:TFIDF、 BM25
- 不足:无法解决词语的多意同义问题、语序对语义问题(如“深度学习“和“学习深度“)
二、文档中的关键字~查询词(语义匹配)
- 潜语义模型
- 代表: LSA PLSA LDA
- 不足:非监督学习,目标函数和实际检索任务的评价方法联系并不紧密
还有两种方法是对语义模型的拓展:
【点击数据】没懂
【深度自编码器】
- 通过深度学习的方法学习query和doc之间的层级结构
- 不足:因为同样是非监督学习,使得模型效果并不比 关键词匹配 好太多;模型学习仍然需要大规模矩阵计算
三、新方法:DSSM
- 用【 DNN】 对给定query下的doc进行排序,即将query 和doc通过非线性映射到一个简单语义空间,然后计算余弦相似性;NN 是一个判别模型,也是非监督学习训练的,但是和潜语义模型不同的是,直接对web doc排序进行优化
- 用【word hashing】处理 large vocabularies, 将query和doc的高维向量映射到低维向量(基于3个词)
相关工作
DSSM是两个之前相关研究基础上的工作。
隐语义模型和点击数据的使用
一般使用SVD对词-文档矩阵进行低维空间的映射,然后计算余弦距离。
除此之外,还可以使用 翻译模型(translation model)进行语义匹配。这种模型是通过 query和其点击文档 对儿来进行训练的。翻译模型和潜语义模型的不同就在于,前者直接学习的是两个term间的关系( query中的term 和 doc中的term)。如果有大量的点击数据的话,这种模型表现效果非常好。
深度学习
提出了一种 语义哈希(semantic hashing)用于信息检索(就是利用了深度自编码器最后的那层特征)。过程有两步:
- 通过stackRBM将doc的 term向量表示 映射到低维空间;
- 最小化交叉墒的方式优化模型参数
模型中间层的输出可作为特征对文档进行排序。
不足:
1. 给定一个query,不能区分这个doc是不是和query相关的。(因为模型是对相关doc的自编码,就是在学自己);
2. 为了减少计算量,对于一篇doc只选择出现最频繁的2000个word。
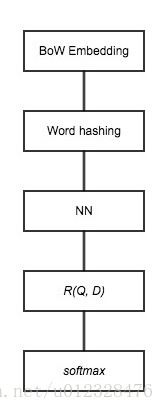
DSSM
DNN获取语义特征
输入:BoW的高维特征,即统计每一个 term 在 query、doc 分别出现的次数(不做归一化处理)。
输出:语义特征空间的低维特征
高维特征不能直接进 DNN,要先通过 word hashing
Word hashing
将一个word,前后加#,然后三个字母的切,这样两个不同的单词会不会产出相同的三元组,论文里面做了统计,说了这个冲突的概率非常的低,500K个word可以降到30k维,冲突的概率为0.0044%
DSSM训练过程
假定query和点击的doc是相关(或者部分相关)的,通过监督学习的方法学习模型参数(即,最大化条件概率:给定query,doc被点击的概率)。目标函数是被点击doc的概率的交叉验证熵。对网络参数{W, b}可导,所以通过基于梯度下降的方法进行优化。
正负样本通过doc是否被点击来标注。正负样本比例1:4,负样本随机采样。论文中,负样本的采样方式对最终结果无明显影响(讲真这是我读此篇论文最大的收获)
