Spark流行的原因
优秀的数据模型和计算抽象
Spark 产生之前,已经有MapReduce这类非常成熟的计算系统存在了,并提供了高层次的API(map/reduce),把计算运行在集群中并提供容错能力,从而实现分布式计算。
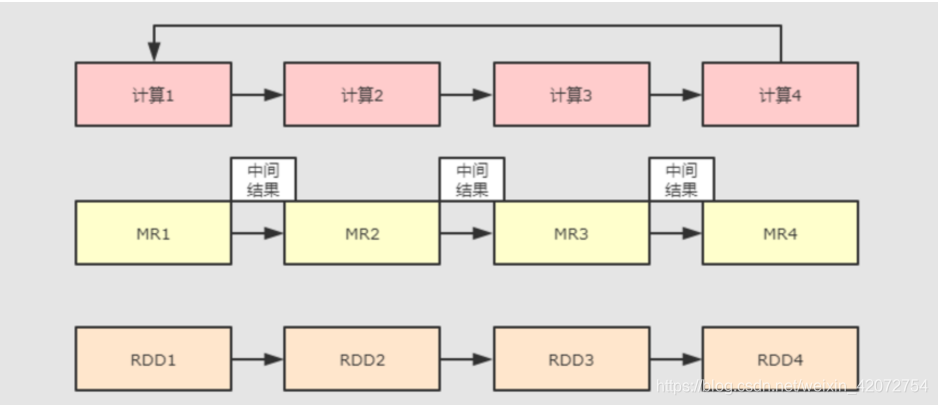
虽然MapReduce提供了对数据访问和计算的抽象,但是对于数据的复用就是简单的将中间数据写到一个稳定的文件系统中(例如HDFS),所以会产生数据的复制备份,磁盘的I/O以及数据的序列化,所以在遇到需要在多个计算之间复用中间结果的操作时效率就会非常的低。而这类操作是非常常见的,例如迭代式计算,交互式数据挖掘,图计算等。
认识到这个问题后,学术界的 AMPLab 提出了一个新的模型,叫做 RDD。RDD 是一个可以容错且并行的数据结构(其实可以理解成分布式的集合,操作起来和操作本地集合一样简单),它可以让用户显式的将中间结果数据集保存在内存中,并且通过控制数据集的分区来达到数据存放处理最优化.同时 RDD也提供了丰富的 API (map、reduce、foreach、redeceByKey…)来操作数据集。后来 RDD被 AMPLab 在一个叫做 Spark 的框架中提供并开源.
简而言之,Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。