学习redis之前,要了解NoSQL。。
一、NoSql概述
由于关系型数据库很难实现:
1.高并发读写
2.海量数据的高校率存储和访问
3.高可扩展性和高可用性
所以出现NoSql,(Not Only SQL)非关系型数据库,是不同于传统的关系型数据库的一种全新数据库管理系统的统称,用于超大规模数据的存储(例如朋友圈每秒可能有上万条数据的读写),这些数据存储不需要固定格式,并且可以横向扩展。
NoSql的产品:mongoDB、Redis、CouchDB等
NoSql数据库的四大分类:
- 键值对(Key-Value)存储:比如Redis,优点是快速查询,缺点是存储的数据缺少结构化
- 列存储:比如HBase,优点是快速查询,可扩展性强,缺点是功能相对于局限
- 文档数据库:比如mongoDB,优点是数据结构要求不高,缺点是查询性能不高,而且缺少统一的查询语法
- 图形数据库:比如InfoGrid(应用于社交网络),优点是利用图结构算法,缺点对整个图进行计算才能得出结果,不容易做分布式的集群方案
4类NoSql优缺点比较
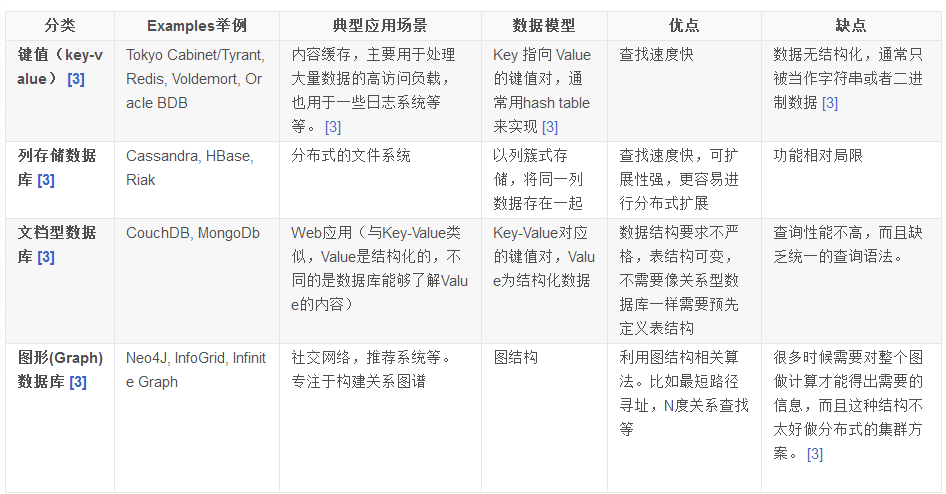
表格来源:https://blog.csdn.net/oleichang/article/details/48626471
NoSql特点:
- 易扩展(去掉关系,可扩展)
- 灵活的数据模型(不需要建立各种字段)
- 大数据量,高性能的存储(非常高的读写性能)
- 高可用(不太影响性能的情况下,使用高可用框架)
NoSql应用:大型Web网站
二、Redis概述
C语言开发开源的高性能的键值对数据库,通过提供多种键值数据类型来适应不同场景下的需求,目前支持的数据类型有:字符串类型、散列类型、列表类型、有序集合类型、集合类型。新浪、知乎、github都在使用redis数据库。
应用场景:
- 缓存:数据查询、新闻、商品信息这些我们经常放入缓存当中;
- 在线好友的列表
- 任务队列:秒杀、抢购;
- 网站访问统计
- 数据过期处理
- 应用排行榜
- 分布式集群架构中的session分离
Redis的安装:
具体安装方式可参考:http://www.runoob.com/redis/redis-install.html,超详细安装教程。
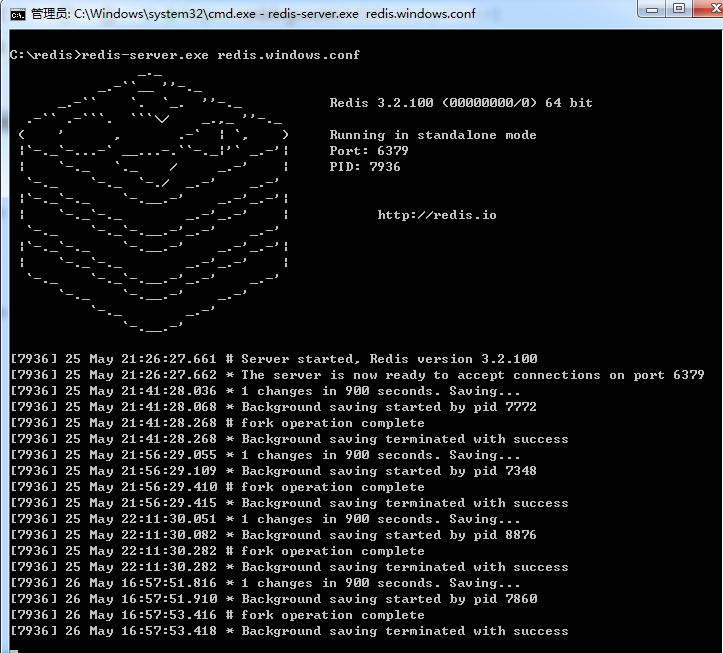
安装完毕,打开Redis服务(windows):
- 在redis的解压根目录下打开cmd窗口,输入redis-server.exe redis.windows.conf,显示如下,说明启动成功
- 再打开一个cmd窗口进入Redis解压根目录,输入redis-cli.exe -h 127.0.0.1 -p 6379
Jedis介绍:
Jedis是Redis官方首选的Java客户端开发包
Jedis源码下载地址:https://github.com/xetorthio/jedis(没有jar的下载地方)
Jedis.jar下载地址:http://mvnrepository.com/artifact/redis.clients/jedis
commons-pool2.jar下载地址:http://mvnrepository.com/artifact/org.apache.commons/commons-pool2
下面是Java对Redis的读写代码:
1.单实例连接
1 @Test 2 /** 3 * 单实例的测试 4 */ 5 public void demo1(){ 6 //1.设置ip 端口号 7 Jedis jedis = new Jedis("127.0.0.1", 6379); 8 //2.存入键值对 9 jedis.set("name", "zhuwei"); 10 //3.取得键值对 11 String value = jedis.get("name"); 12 System.out.println(value); 13 //4.释放资源 14 jedis.close(); 15 }
// 输出结果:zhuwei
2.连接池连接
1 /** 2 * 连接池方式连接 3 */ 4 public void demo2(){ 5 // 获得连接池的配置对象 6 JedisPoolConfig config = new JedisPoolConfig(); 7 // 设置连接池最大连接数 8 config.setMaxTotal(10); 9 // 设置最大空闲连接数 10 config.setMaxTotal(5); 11 12 // 获得连接池 13 JedisPool jedisPool = new JedisPool(config, "127.0.0.1", 6379); 14 15 // 获得连接 16 Jedis jedis = null; 17 try { 18 // 通过连接池获得连接 19 jedis = jedisPool.getResource(); 20 // 设置数据 21 jedis.set("name", "jinzf"); 22 // 获得数据 23 String value = jedis.get("name"); 24 System.out.println(value); 25 } catch (Exception e) { 26 e.printStackTrace(); 27 } finally { 28 // 释放连接 29 jedis.close(); 30 // 释放连接池 31 jedisPool.close(); 32 }
//输出结果:jinzf
Redis的数据结构:
key定义注意事项:
- 不要过长
- 不要过短
- 最好有统一的命名规范
1.存储String
- 以二进制存储,存入和获取的数据相同
- value最大长度512M
- 常用命令
- set key value --存入
- get key --获取
- del key --删除
- incr key --整数增长1,如果key不存在,默认值是0
- decr key --整数递减1,如果key不存在,默认值是0
- incrby key n --整数key增长n,默认值是0
- decrby key n --整数key递减n,默认值是0
- append key n --字符串key后面拼接n,如果key不存在,会创建key,值是n
2.存储Hash
- String key和String value的map容器,非常适合存储值、对象的信息
- 每一个Hash可以存储4294967295个键值对
- 常用命令
- hset key (key value) --存入 eg:hset mykey username zhuwei(存入一个key为mykey的map,value是username zhuwei)
- hmset key (key1 value1 key2 value2...) --存入对个键值对
- hget key value-key --获取key中map的key为value-key的值
- hmget key value-key1 value-key2 --获取key中map的key为value-key1和value-key2的值
- hgetall key --获得全部键值对
- hdel key value-key1 value-key2 --删除多个map
- del key --删除key的整个Hash
- hincrby key value-key n --key中的value-key增长n
- hexists key value-key --key中是否存在value-key,1:存在 0:不存在
- hlen key --获取key整个Hash的属性长度
- hkeys key --获取key整个Hash的全部value-key
- hvalues key --获取key整个Hash的全部value-value值
3.存储List
- ArrayList使用数组方式存储数据,根据下标查找数据速度快,但是插入元素涉及到元素的位移,速度变慢
- LinkedList使用双向连接方式存储数据,插入元素只改变前后元素的指针指向,所以速度快,查找元素涉及到遍历整个链表,速度变慢
- 双向链表中增加数据
- 双向链表删除数据
- 常用命令
- lpush key n1 n2 n3 --左侧添加元素,存放之后顺序为:n3 n2 n1
- rpush key n1 n2 n3 --右侧添加元素,存放之后顺序为:n1 n2 n3
- lrange key 0 n --取出下标为0-n的元素,0 -1 :显示全部元素 0 -2 显示到倒数第二个元素
- lpop key --从左侧弹出
- rpop --从右侧弹出
- llen key --输出长度
- lpushx key x --在头部添加x元素,如果key不存在,不会存入x
- lrem key n m --从头删除n个m
- lrem key -n m --从后删除n个m
- lset key n x --在第n个角标处添加x元素
- linsert key before n x --在第一个n之前插入x
- linsert key after n x --在第一个n之后插入x
- rpoplpush key1 key2 --取出key1的最后一个元素,插入到key2的第一个元素处
- rpoplpush常应用于消息队列,来完成多个程序之间的消息交互
4.存储set
- 没有排序的字符集合,不允许出现重复的元素
- 包含的最大元素个数是4294967295
- 常用命令
- sadd key a b c --添加元素
- srem key n -- 删除key中n元素
- smenbers key --输出key中元素
- sismember key n --判断key中是否含有元素n
- sdiff key1 key2 --求key1 key2的差集运算
- sinter key1 key2 --求key1 key2的交集运算
- sunion key1 key2 --求key1 key2的并集运算
- scard key -- 输出key的元素个数
- srandmenber key--随机返回key中的一个元素
- sdiffstore key key1 key2 --将key1和key2的差集存到key中
- sinterstore key key1 key2 --将key1和key2的交集存到key中
- sunion key key1 key2 --将key1和key2的并集存到key中
- set的应用场景:
- 记录唯一性的数据(访问博客的某一Ip,保证ip的唯一性)
- 维护数据对象之间的关联关系(买了某一商品的人存入一个set中,买了另一种商品的人存入另一个set中,求同时购买了两种商品的人,set之间做交集即可)
5.存储sorted-set
- sorted-set和set都是字符串的集合,都不允许有重复的成员
- sorted-set没有key中的成员都有一个分数与之关联
- 成员在集合中的位置是有序的,分数可以重复
- 删除、添加、更新成员都是很快的
- 主要应用场景:游戏的积分排行、微博的热门话题、构建索引数据
- 常用命令
- zadd key score1 n score2 m... --添加元素n的分数是score1,m的分数是score2,分数重复会替换掉原来的分数
- zscore key n --获得key中n的分数
- zrem key n --删除key中的n
- zrange key 0 -1 (withscores) --输出key的所有成员(并且输出分数),从小到大
- zcard key --输出key的元素的个数
- zrevrange key 0 -1 (withscore) --从大到小输出数据
- zremrangebyrank key 0 4 --按照下标删除key中的元素
- zremrangebyscore key score1 score2 --按照分数范围删除key中的元素
- zrangebyscore key score1 score2 withscore limit n m --输出key中分数范围在score1和score2之间的前2位,分数从小到大排序
- zincrby key n x--将key中的x的分数加n
- zcount key score1 score2 --输出key中分数范围在score1和score2之间的元素个数
keys的通用操作:
- keys * --获得所有keys
- key * my? --获得以my开头的keys
- del key1 key2 key3... --删除key1 key2 key3
- exists key --是否存在key,0 不存在,1 存在
- rename key newkey --重命名
- expire key time --设置key的过期时间time(秒)
- ttl key --获得key还剩多少时间过期(没有设置超时时间返回-1)
- type key--获得key的类型
Redis的特性:
- 多数据库
- 一个Redis可以创建多个数据库(最多16个,下标0-15,默认连接0),客户端可以指定连接哪个数据库。
- select n --切换数据库n
- move key n --将当前数据库中的key移动到n号数据库
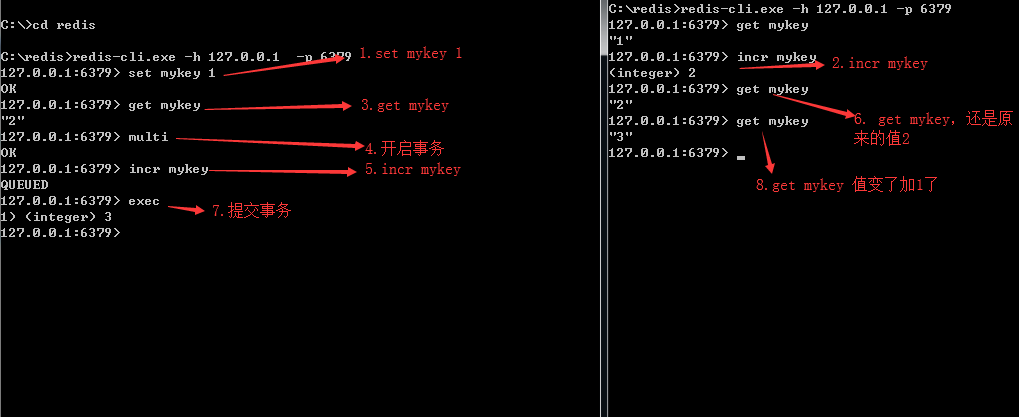
- 事务
- multi --开启事务(和关系数据库begin差不多)
- exec --提交(和关系数据库的commit差不多)
- discard --回滚(和关系数据库的rollback差不多)
- 下面演示下事务的过程:开启两个客户端同时连接第0个数据库
Redis的持久化:
redis的高性能是因为它的数据都存储在了内存当中,为了保证redis在重启之后数据不会丢失,需要将数据从内存当中同步到磁盘上,这个过程叫持久化操作。redis有两种持久化方式。
- RDB方式:默认支持,不需要配置,指在指定的时间间隔内,将内存中的数据集快照写入到磁盘。
- AOF方式:以日志的方式记录服务器所处理的每一个操作,在redis服务启动之初,读取这个日志文件,重新构建数据库,来保证启动后数据库的数据是完整的
- 不持久化:通过配置,禁用持久化,redis将是一个缓存的形式存在
- 同时使用RDB和AOF方式
RDB
- 优势:
- 整个redis的数据库只包含一个文件
- 非常利于灾难恢复,只有一个文件利于copy
- 使用单独的子进程读写文件,保证了redis的高性能
- 缺点:
- 不能保证数据的高可用性,在时间间隔之间数据库出现宕机,来没来得及保存数据,数据会丢失
- 数据集非常大的时候,服务器需要停止较长时间处理保存数据的操作
- 配置:
- redis的解压根目录下,找到下面的文件,可以修改RDB的配置参数
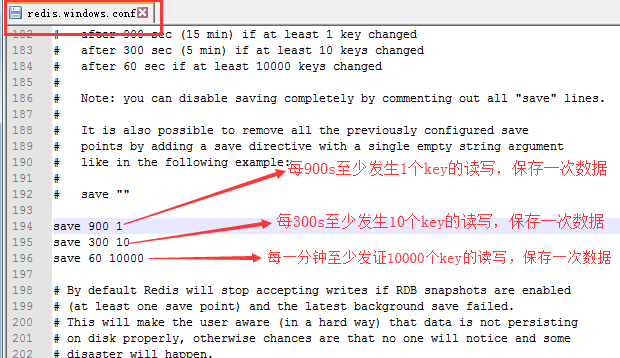
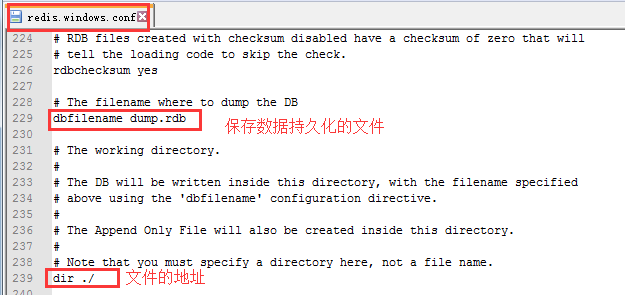
- redis的解压根目录下,找到下面的文件,可以修改RDB的配置参数
AOF
- 优势:
- 更高的数据完整性(3中写入方式:每秒写入[异步写入,效率较高]、每修改写入[效率最低]、不持久化),最多丢失1s的数据
- 对日志文件用append追加形式操作,出现宕机不会影响已经写入的数据
- 日志过大,会自动启动重写机制
- 日志格式清晰,容易进行数据重建
- 缺点:
- 相同数据集,AOF的文件比RDB文件大
- 根据同步策略不同,运行效率低于RDB(每修改同步时,效率低)
- 配置:
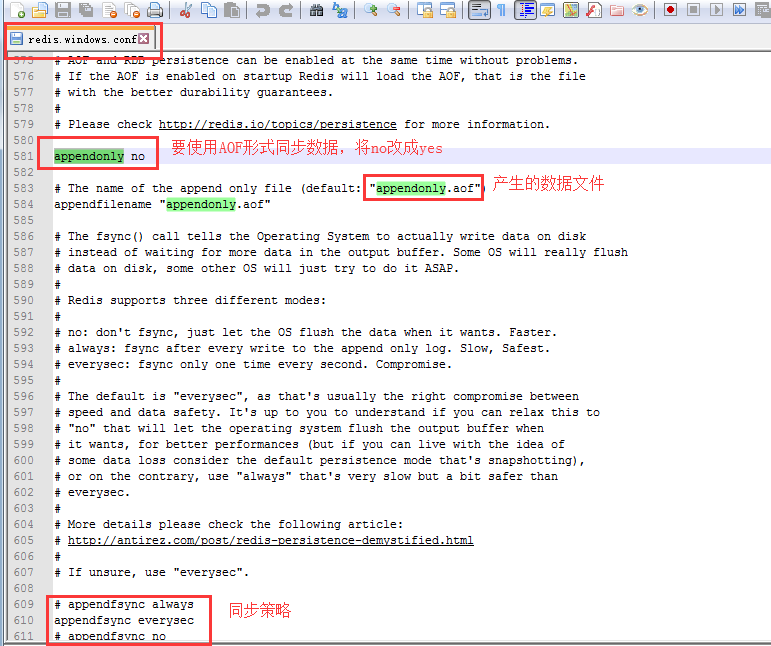
- 修改完文件,将redis停掉,重新启动
总结:
Nosql
jedis
redis入门
redis的数据类型及常用命令
redis的持久化