服务器一般用centOS作为操作系统。
hadoop标志

hadoop简介

hadoop发展史


hadoop特性
一个文件有多个备份,对集群的硬件要求不是特别高,可编程,支持多语言


hadoop应用现状


版本演变


Hadoop项目结构


hadoop安装方式

安装双系统(因为我电脑配置还算可以,所以我实验时用的是虚拟机)
第一步:制作安装U盘
具体可参考百度经验文章戳这里
第二步:双系统安装
具体可参考百度经验文章戳这里

JDK和Hadoop安装
因为Hadoop是Java语言写的,所以要安装jdk。
先上传JDK,我放到了/home/czh/resources下
cd resources
tar -zxvf 压缩包名(eg: tar -zxvf jdk-7u71-linux-x64.gz)
然后将解压出的文件重命名为jdk
mv 解压出的文件名 jdk
然后配置环境变量,vi ~/.bash_profile
按E编辑文件,按i进入编辑模式,然后在文件末尾追加以下两句话
export JAVA_HOME=~/resources/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
(冒号表示两个值做连接运算。$PATH是PATH原来的值,即在原来的PATH之前增加了.和JAVA_HOME/bin这两个值)
添加完成之后,按esc->:wq保存退出。
再source ~/.bash_profile 让此文件生效
再java -version看是否配置成功。(注意修改配置文件的时候要每个节点单独修改)

crt连不上的原因:
ip地址变化
虚机ip和windows不在一个网段内
虚机hosts和windows端的hosts文件的配置
ip和主机名绑定问题
**********************************************************************************
安装Hadoop,先安装主节点
先将压缩包上传到/home/czh/resources目录下
cd
cd resources
tar -zxvf hadoop-2.6.4.tar.gz
将解压后的文件重命名为hadoop
mv hadoop-2.6.4 hadoop
**********************************************************************************
在主节点下vi ~/.bash_profile添加两行配置信息
export HADOOP_HOME=~/resources/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
一定要敲对,否则会找不到hadoop命令!!!!
保存退出之后
source ~/.bash_profile 让文件生效
安装Notepad++(方便操作而已)
如下三步创建新连接

然后点击如下位置链连接刚才新建的连接
连上之后右侧就会看见虚机下的目录
以下操作在如下目录操作 /resources/hadoop/etc/hadoop/

先将hadoop-env.sh文件双击打开,将第25行的JAVA_HOME赋值为自己的jdk路径,保存退出即可。

再打开yarn-env.sh文件
同理找到第23行修改JAVA_HOME路径为自己Linux下的jdk路径
![]()
在core-site.xml添加红框里的信息
<property>
<name>fs.defaultFS</name>
<value>hdfs://主机名:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/用户名/resources/hadoopdata</value>
</property>还要在主机 /home/用户名/resources/目录下新建一个hadoopdata文件用来存放临时文件

再打开hdfs-site.xml文件添加红框信息,2代表有两个副本,即两份文件,安全性得到保障
<property>
<name>dfs.replication</name>
<value>2</value>
</property>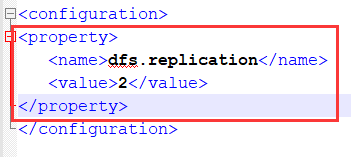
再打开yarn-site.xml文件如下添加
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property> 
在hadoop路径下创建mapred-site.xml文件,再将mapred-site.xml.template文件中的内容复制到创建的文件中,
再添加如下
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>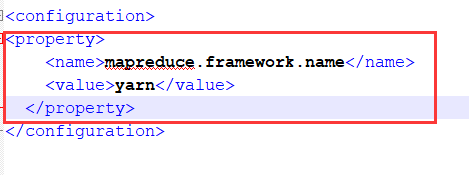
打开slaves文件
添加从节点名称
slave1
slave2在主节点上复制文件到从节点
切换到resources目录下,执行
scp -r hadoop slave1:~/resources/
scp -r hadoop slave2:~/resources/启动hadoop集群(只在主节点上做)
(1)执行hadoop namenode -format 来进行格式化

如上所示即为格式化成功。
(2)启动
cd resources/hadoop/sbin
ls查看文件,可看到start-all.sh文件
执行命令start-all.sh
验证是否成功(两种方式都做)
验证一:
交互窗口下输入jps
主节点应该启动了至少如下四个进程

从节点上应有至少如下三个进程
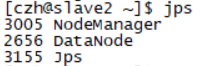
验证二:
在虚机上用浏览器网页方式验证
输入地址 master:50070
点击Datanode看到slave1和slave2都in service即成功

如果有问题,可用如下三种办法解决;
way1.重启hadoop(执行 stop-all.sh)
way2.重新格式化
way3(终极方法).删除所有节点下的Hadoopdata(临时文件),再在所有节点下重建hadoopdata文件,
再删除resources/hadoop/logs下的所有文件
再从上面的启动hadoop集群开始做一遍。
好啦,以后直接如下启动就好了!
cd resources/hadoop/sbin
start-all.sh
