一、目标检测是什么

最小外接矩形,也就是最后要回归的目标,也要打上一个标签,且希望和实际情况越接近越好。
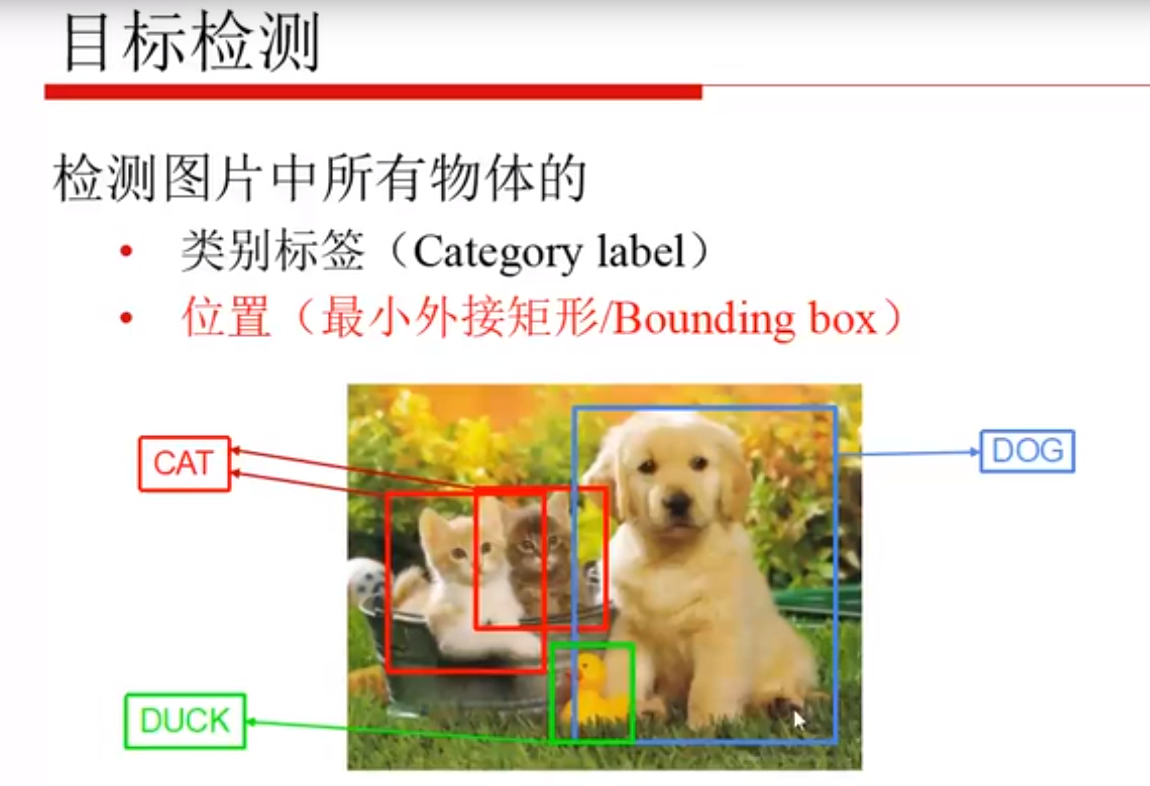
实例分割要显示每一个像素属于谁,更加复杂。
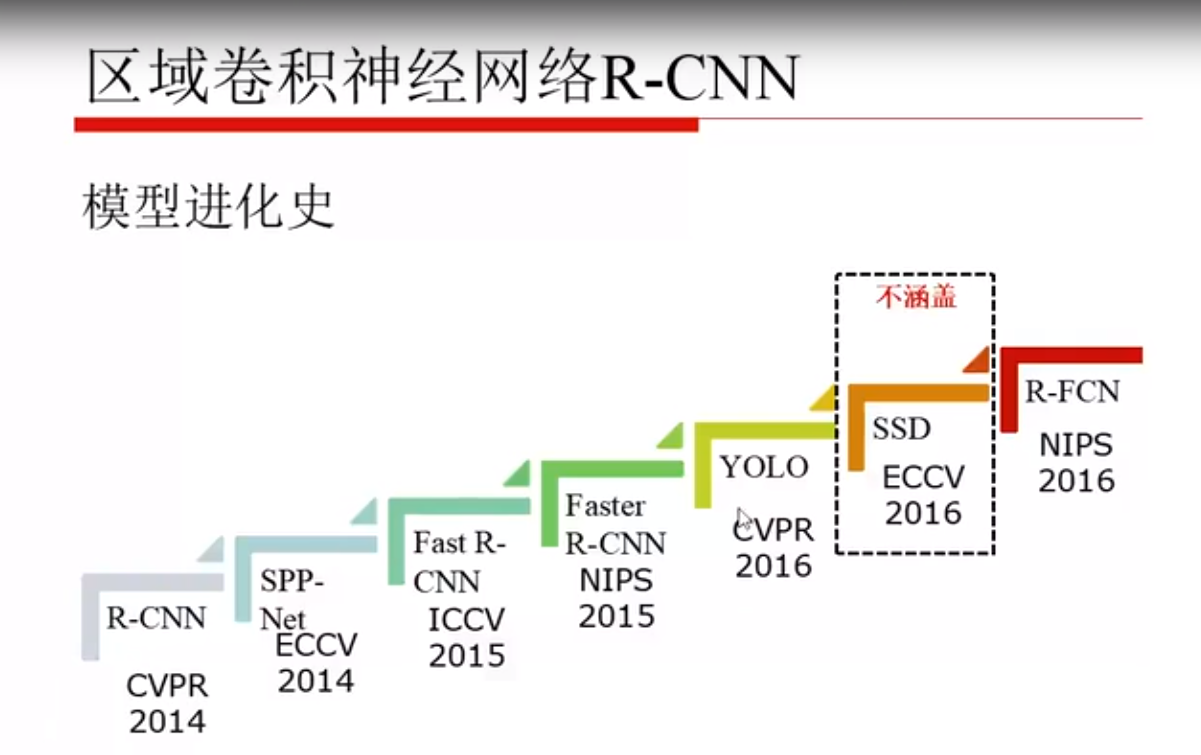

YOLO之前的模型都是两个步骤:
- 提取一些可能有目标的区域
- 识别区域中的是什么类别
二、RCNN
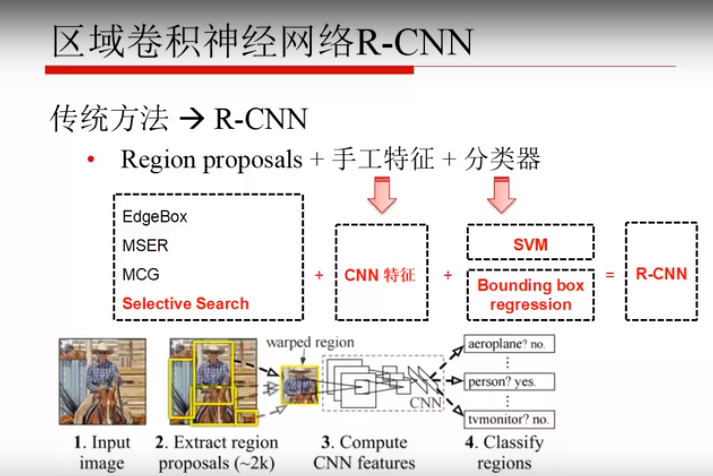
输入一张图像
利用特定方法生成大约2k个框,这些框包括所有可能成为候选框的区域(形状都不同,只是保证其是个矩形)
将框进行统一尺度
进行一些数据增强
CNN 特征提取(从某一层出来的特征保留)
送入SVM 进行分类,送入回归进行b-box的回归。


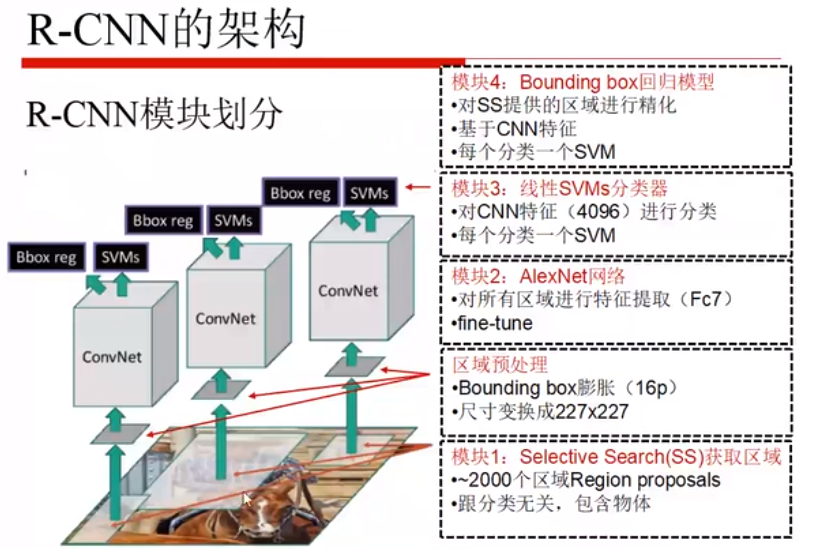
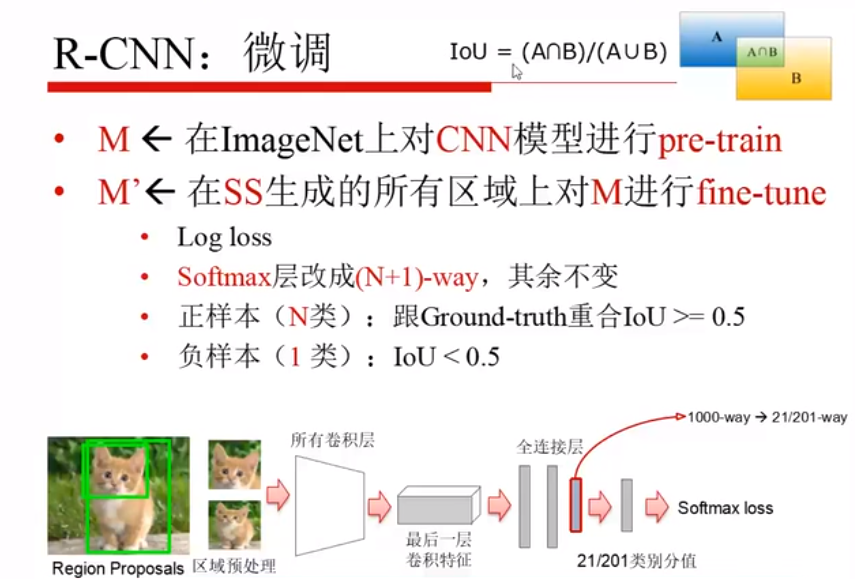
先对分类模型进行预训练,之后将SS生成的所有的一块一块的区域对模型微调,21、201(包含1个背景)是用到不同数据集,里边类别的多少就不同。
预训练后需要修改的:
- 目标函数 loss
- softmax的1000个输出,改成N+1个输出(检测的类别数)
- 正样本(N类):所有类别中,框和GT的IoU>=0.5的看成正样本
- 负样本(1类)):背景/没有框完整的,IoU<0.5
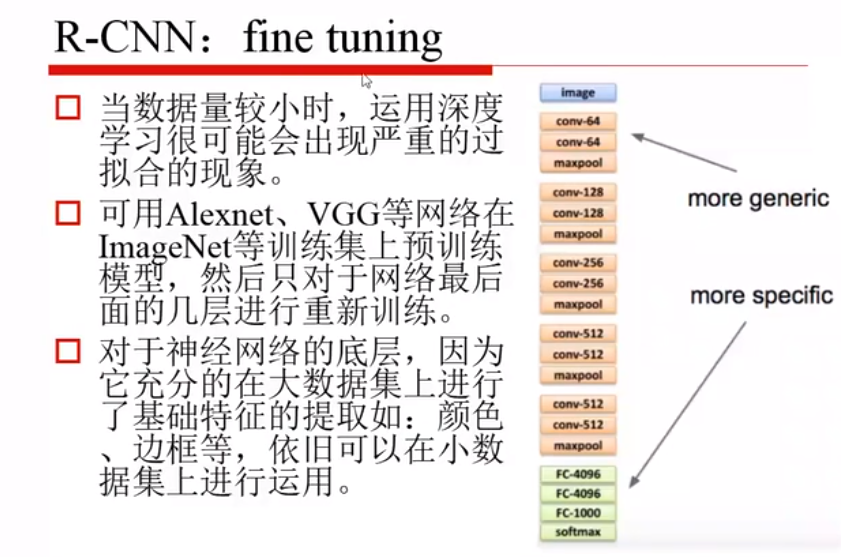
底层的特征是越通用的,越往上是越专用的,如果数据量小的话就只训练下面绿色的就可以,如果数据集较大的话,就训练下面两个模块即可。
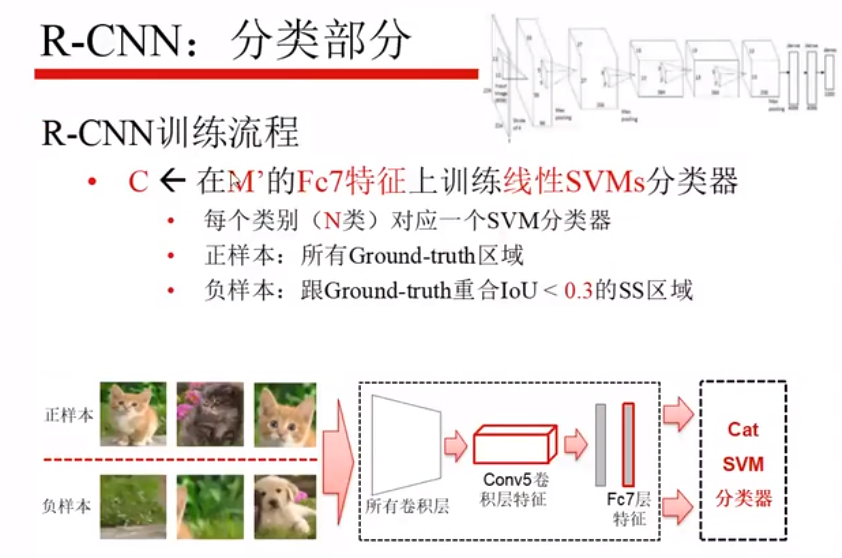
在M’的基础上,第七层是全连接层,将这个4096维的特征拿出来送入SVM中,使用的SVM是二分类器,正样本是某一类,负样本是除该类以外的所有类(包括背景)。
SVM训练完之后,可能会出现负样本概率也大于0.5,将这些收集起来,重新训练一下。

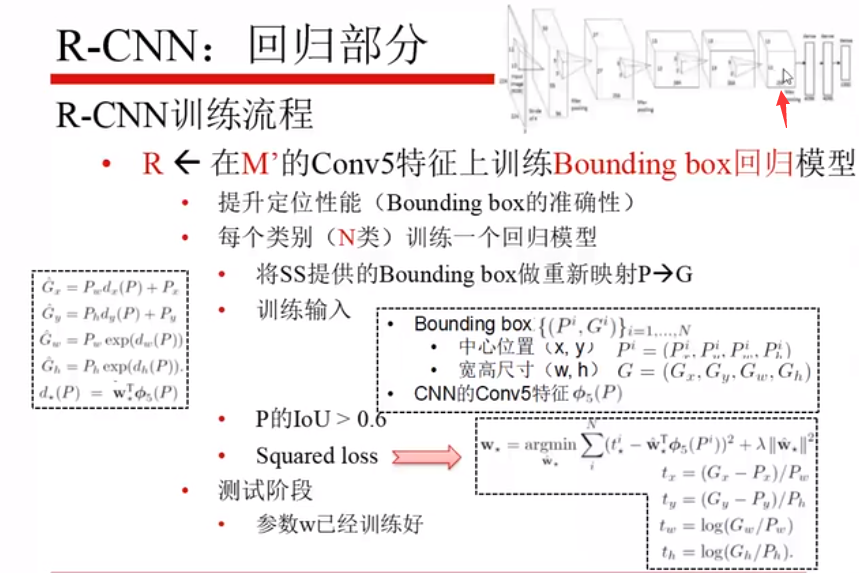
在fine-tuning之后的模型的第五层上训练回归模型,回归的目标是把SS滑出来的框和真实框(G)做一个回归,每一类单独回归,也就是SS 回归得到的猫的框(P)和猫的真实框做回归,每一类训练一个回归模型。
P 的要求:SS 选出来的框和 GT 框的 IoU >0.6,
输入的是第五层输出的特征,而不是坐标,输出是SS和GT的差值。
目标函数是最大化,定义了一个回归的模型,就是P和G平方差最小。

评价有两重精度:
- 某个类的平均精度:AP,PR 曲线下的面积,即 P 对 R 的积分。
- 所有类的平均精度求和/类别数,即所有类的平均精度的平均值。

AP: 单个类别的效果
当把上面的第一条线当做阈值,上面的都当做飞机,下面的都不当做飞机,则此时准确率很高,召回率不高,当把第二条线当做阈值时,准确率降低,召回率变高。这就是 PR 曲线。PR 曲线下的面积就是综合考虑 P 和 R 得到的结果。
mAP: 所有类别的效果的均值

三、SPPnet


RCNN:先对框中内容进行裁剪或拉伸,再进行卷积
SPPnet:先对整幅图像进行卷积,再进行SPP 操作
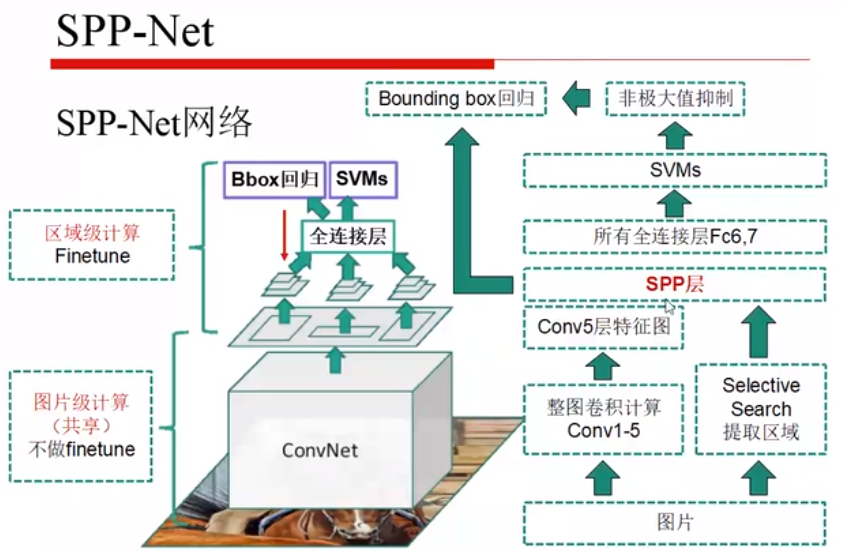
对输入进行4x4/2x2/1x1的最大池化,即所有的小区域都可以被划分成相同大小的像素级联,方便全连接层。
为什么可以先卷积,后 SS:因为卷积后特征的相对位置不变,即可以先卷积,然后在找到对应的框,提取特征图特征。

fine-tuning过程也有差别:预训练
SPP 处理
使用 SPP 特征来微调全连接层,不能微调卷积层,其他的过程和 RCNN 一样。

SPP :特征提取时间很大的变短了,但仍然是分类和回归分别训练,但不能微调卷积层参数(感受野太大,效率太低等)。

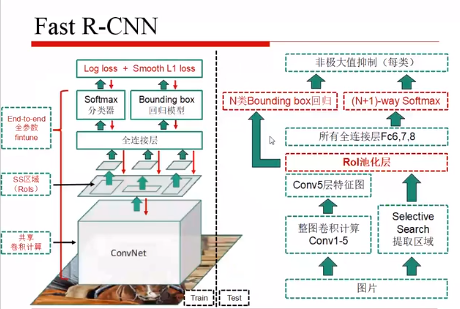
四、Fast R-CNN

R-CNN 和 SPP 都是训练两个头,而 Fast R-CNN 实现了多任务损失,取消了 SPP 模块,使得所有层的参数都可以fine-tuning。
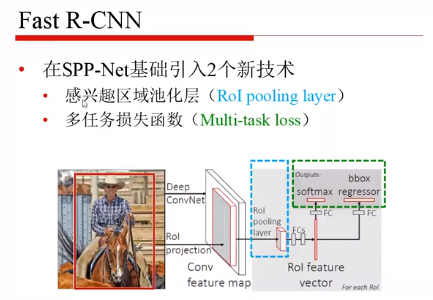
首先:全图做卷积,提取region proposal
其次:把第五层的卷积输出,和 region proposal 送入RoI pooling层
再次:把分类和回归头使用一个损失函数进行训练
RoI pooling:RoI pooling 是取了一个较细尺度的划分,来进行最大池化,再传入全连接层。
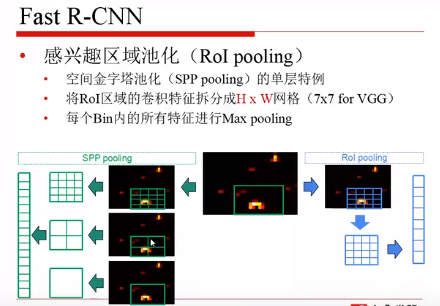
反向传播的不同:
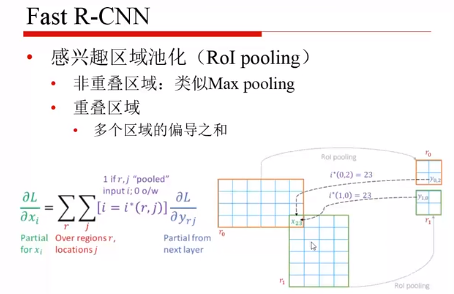
红色的框是区域建议的框,绿色的框是人工标注的 GT ,回归问题就是将红色的框映射为绿色的框。

exp永远为正,用于保证训练完之后的值不会变成负的。

多任务损失:分类+回归损失
分类损失:u是类别,p是概率分布,分类正确时,pu=1,-logpu接近于0,pu分类错误时,pu=0.2,-logpu会较大,即分到u上的概率要尽可能的大。
回归损失:当物体类别为背景时,就不存在回归问题了,故要先应用指示函数
smooth_L1:当x非常大的情况,相当于是离群点,会使得这批数据回归出现问题,故让离群点的影响小一点,即x较大时,让输出为 |x|-0.5,而不用平方。

batch:图片数量为2,每个图片中的 RoI 为64,此时 batch size 为128。
物体和背景的平衡:物体占1/4,背景占3/4。希望两者数据量平均点,样本量偏的太厉害会有问题,因为正向样本较少。

全连接层数据量大,故其采用了 SVD,将其分解为两个矩阵,也就是将全连接模型进行压缩,然后在重现出来,总的权重数量减少,加速运算。

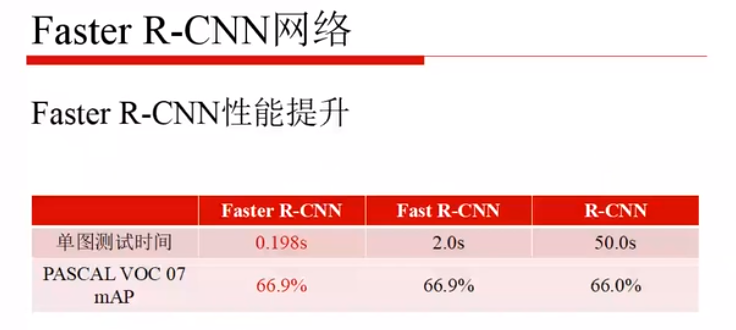
Fast RCNN的速度和性能都很好:
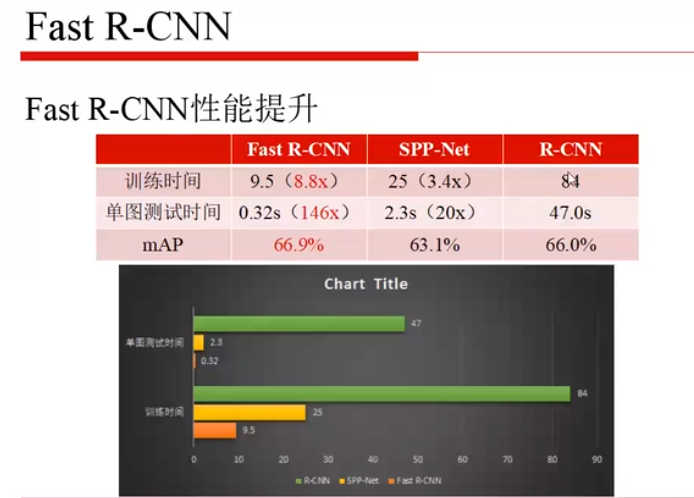
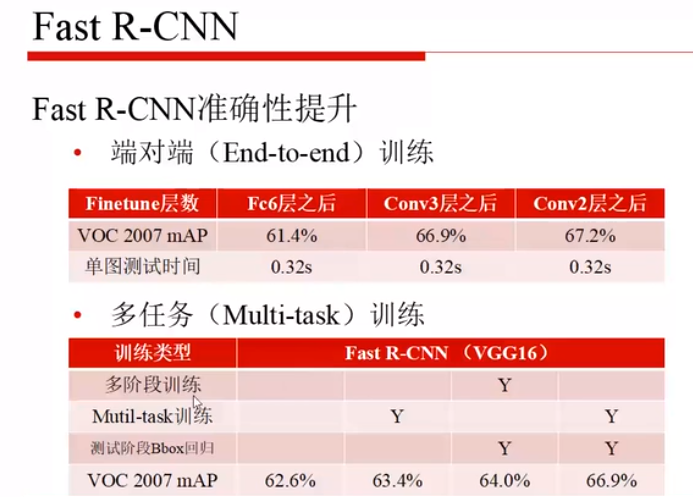
Fast R-CNN 的局限:

五、Faster R-CNN

RPN:量少质优
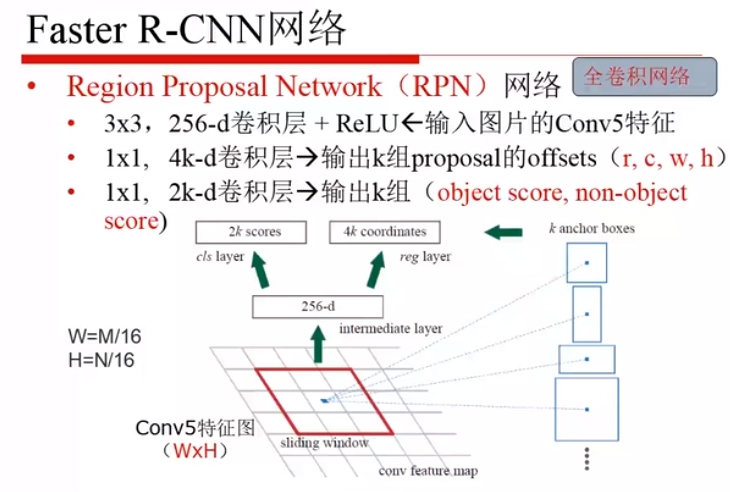
输入的图像经过卷积获得第五层卷积特征
3x3的卷积核
得到256维的卷积层
对256维的特征图分别进行两个不同的 1x1的卷积过程
一路进行分类,得到 2k 个得分(是物体/不是物体,k一般为9,也就是18,1x1x256x18),另一路进行回归,得到4k个参数(r/c/w/h)
将两者结合起来
候选框来源:
尺度:表示原始图像上的物体
纵横比:1:1,1:2,2:1
在候选框基础上,再做分类和回归。

损失函数:

训练:
- 先训练 RPN ,输出候选区域
- 将候选区域给到 Fast R-CNN 里边去,初始化仍然是 Imagenet 的参数
- 将第二步训练好的权重,作为第三层卷积层的初始化,固定住卷积层的参数,微调RPN自己的参数,也就是 RPN 此时给出的建议可能会比之前的那个更好点。
- 固定卷积层,微调剩余层。


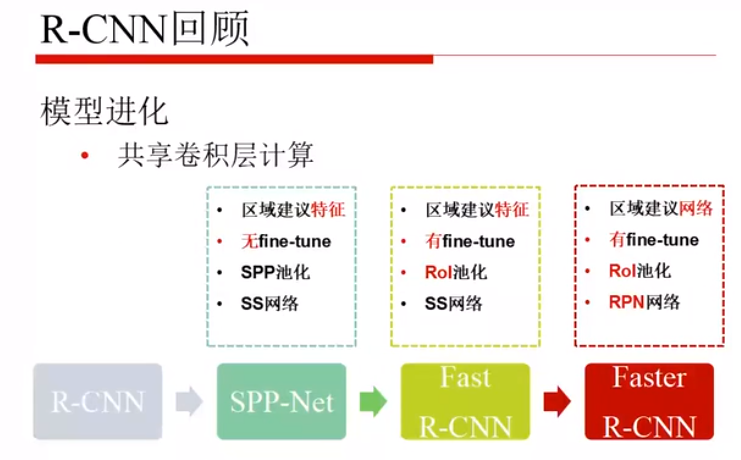
R-CNN 系列总结:

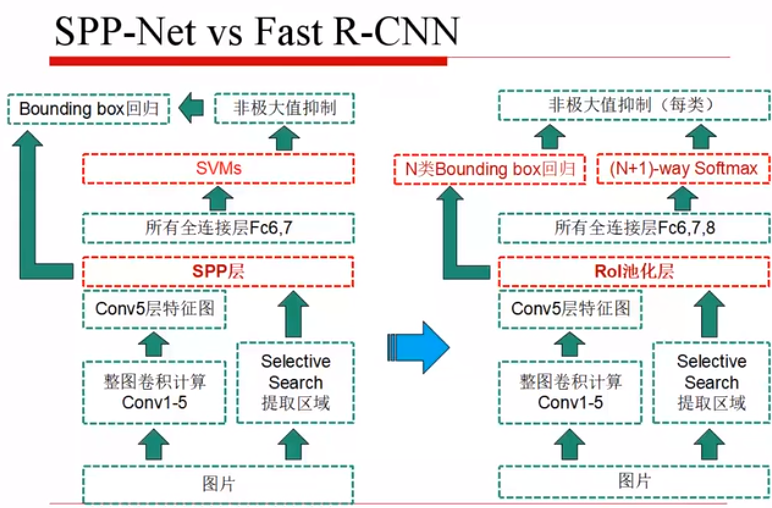
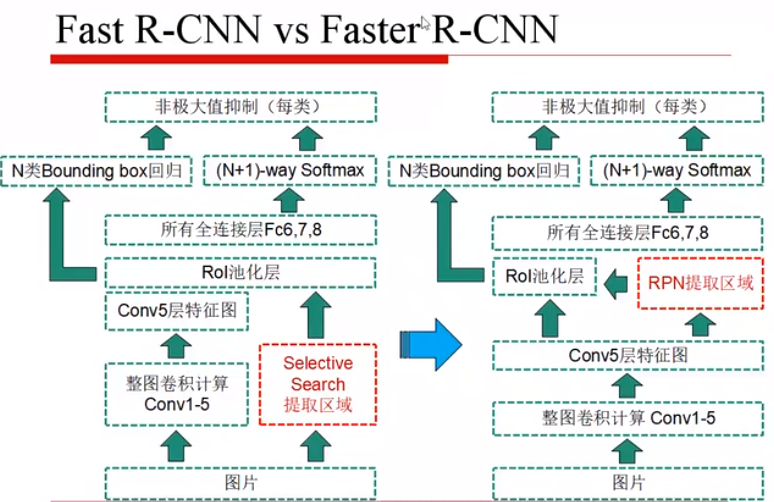

RoI-wise:基于RoI层所衍生的一些东西
CNN 的全卷积化趋势,因为全连接层参数太多。
CNN 一开始是用于分类的,所以对分类的性能是挺好的,即便是目标物体位置改变,卷积之后输入全连接层,也对分类结果影响不大。
但对于定位网络,全连接层是将整个图像的特征进行列向量话,肯定会对位置产生一定的影响,所以不希望回归网络最后是全连接网络。

六、R-FCN
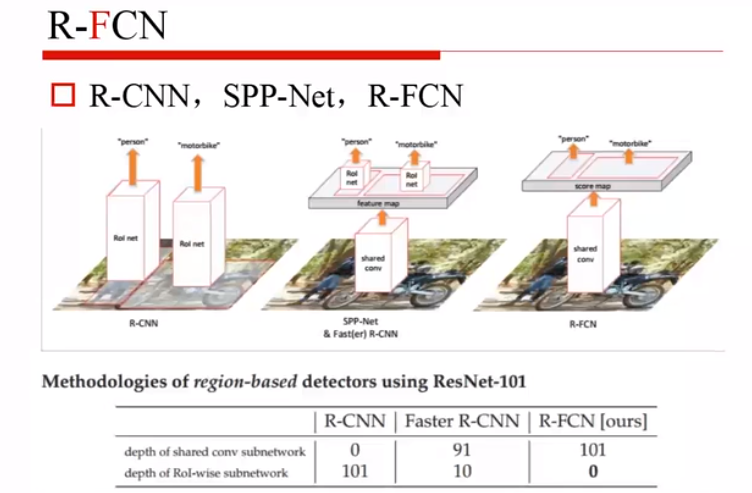
R-CNN:一旦有个框,就要卷积一遍
SPPnet:先卷积,再找框,框又要单独的一个个过子网络,再做全连接
R-FCN:全卷积网络

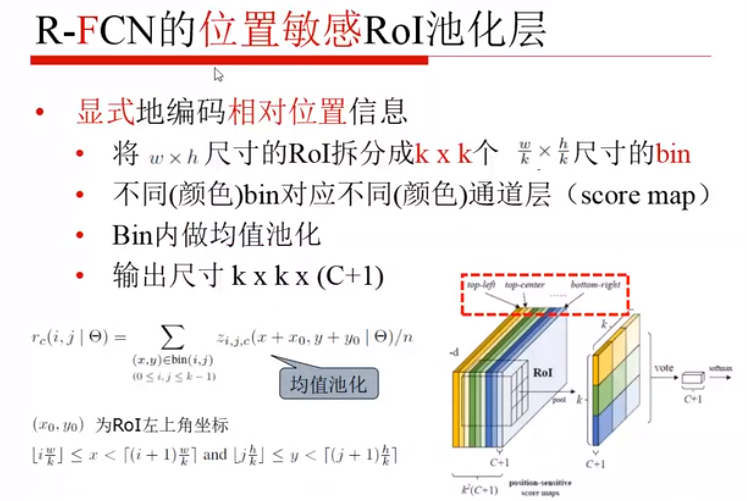
变换敏感性:
- 引入位置敏感分值图,score map(核心)
- 分值图上做的一个位置敏感池化处理(纵向的若干层,变成横向位置上的差异)
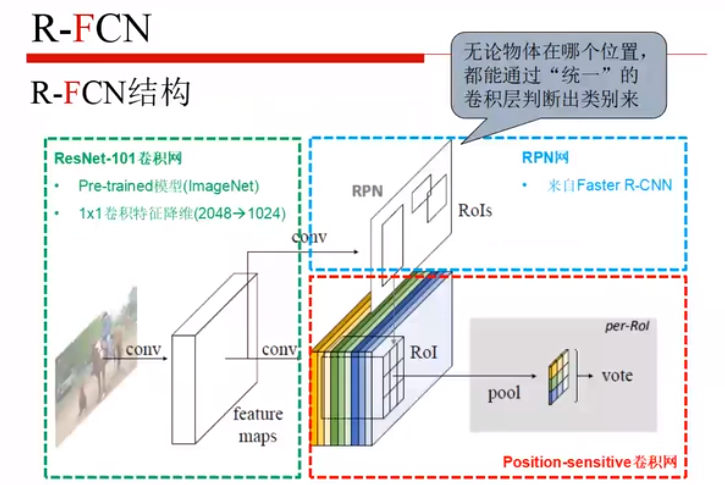
主干网络:resnet-101
卷积之后,一个分支输入RPN,另一个分支就是位置敏感分值图,黄色是找A类的特征,绿色的是找B类的特征,等等等,无论物体在哪个问题,只要哪个层是用来判断该物体的层,就能够检测出来那个物体,纵向的综合起来,然后投票,就能得到其是哪一类。

每一个片都代表C个物体的类+1个背景的类,每个类别都有k^2个score map,之后叠加起来,最后才用上 RoI。
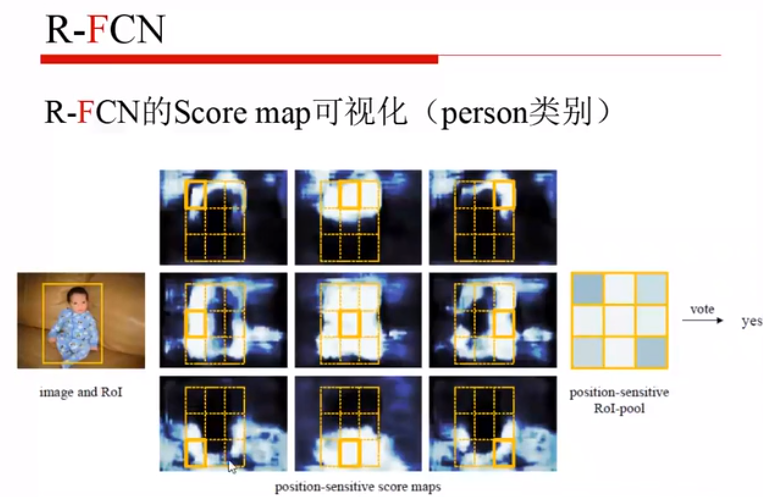

七、YOLO v1
YOLO v1 最多能识别九千个类别

之前的工作似乎都是做两件事,一件是分类,一件是定位,YOLO 是把所有的问题都当做回归问题来解决。
每一个图化成7x7的块,判断哪个块属于哪一类。
resize:让网络能够找到较小的物体
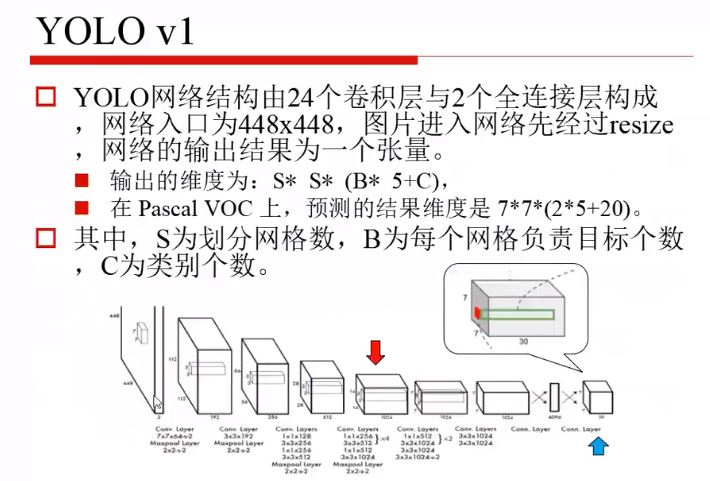
网络结构:
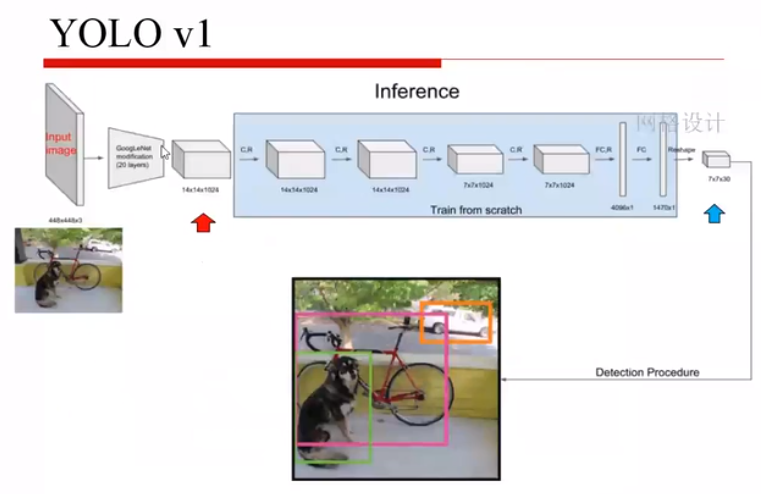
输入
GoogLeNet(简化成20层)
卷积和全连接层(fully connection)
reshape
输出最终结果,三维数据块7x7x30(前两维是划分的块,第三维是)

输入的维度:上采样的图片
输出的维度:7x7x30
B:2(两个b-box)
5:位置(四个值)和置信度
C:20个目标类别

两个b-box,一个宽的,一个窄的。
公式:confidence=Pr(object)*IoU
Pr:是一个目标的概率
IoU:GT的框和预测的b-box的IoU

30个值:
前10个:两个框,每个框预测5个值(定位和置信度),全都是归一化的
后20个:针对每个类别的概率(Pr(class|object)),已知是目标的情况下,是哪一个类别的概率。
测试阶段:


蓝色框:首先判断定位定的准不准,平方在括号外边,都是坐标的协调系数,没有改两者的协调系数。
红色框:1——指示函数,是目标是1,不是目标是0,之后置信度相减

黄色的框置信度肯定很高,绿色的框和黄色框重合度较大,所以将重合度大于一定阈值的剔除。
判断类别:
98个box:7x7x2
C:b-box里边是否还有目标的置信度,做一个阈值处理,之后做NMS
NMS:不考虑具体是什么类别,先考虑重合且分数没有他高的框去掉。


优点:
一共只有98个候选框,故检测物体的速度快;
不是目标而判断成目标的情况较少;
能学到更加抽象的特征。
缺点:
精度低;
定位较差;
小物体检测不好,因为一个栅格只预测2个物体,再经过NMS,可能就只能预测一个物体。
八、YOLO v2
在 YOLO v1上做了7个改变:
- BN
- 高精度分类器,v1中使用的预训练好的模型是基于256x256训练得来的,v2中使用高精度图像来预训练,能够更好的发现小目标
- 添加了 anchor ,v1用了两个,多了anchor能够使得召回率明显提升
- 使用 k-means 方法来训练了 b-box,找到更合适的b-box的宽高比,有5类是比较明显的,故选择了5个b-box,这些b-box各自是不同的尺寸,瘦高型的较多。




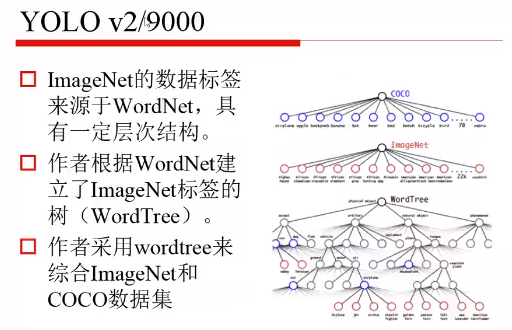
将 Imagenet 和 coco 结合起来了,一共9000个分类。
九、YOLO v3

- 损失函数改变,sofrmax只能输出最大的,Logistic loss 可以多分类,有得分。
- V3使用了3个anchor,分层级的变成了9个

scale1预测大尺度目标,scale2预测中间尺度目标,scale3预测小尺度的目标。


