文章目录
- 1. 措施
- 2.Scrapy Middleware用法简介(下面几个操作都需要用到这个文件)
- 3.随机延时爬取
- 4.禁止cookies
- 5.若不禁止cookies,就加上header和cookie
- 转自:https://blog.csdn.net/sinat_41721615/article/details/99625952
- 5.1 方式一:cookies需要写成字典形式
- 5.2 方式二:cookies不需要写成字典形式
- 6. 随机user-agent
- 7.ip池(目前用到的最大杀招)
1. 措施
爬的太猖狂,容易被封ip。避免被封,就要采取一些措施
策略1:设置download_delay下载延迟,数字设置为5秒,越大越安全,老师说15~90秒。。。
策略2:禁止Cookie,某些网站会通过Cookie识别用户身份,禁用后使得服务器无法识别爬虫轨迹
策略3:使用user-agent池。也就是每次发送的时候随机从池中选择不一样的浏览器头信息,防止暴露爬虫身份
策略4:使用IP池,这个需要大量的IP资源,貌似还达不到这个要求
策略5:分布式爬取,这个是针对大型爬虫系统的,对目前而言我们还用不到(没用过)
策略6:伪造x-forward-for,伪装自身为代理,让服务器不认为你是爬虫(没用过)
2.Scrapy Middleware用法简介(下面几个操作都需要用到这个文件)
2.1 文件位置
2.2 简介
转自:https://www.cnblogs.com/onefine/p/10499320.html
介绍:
Downloader Middleware即下载中间件,它是处于Scrapy的Request和Response之间的处理模块。
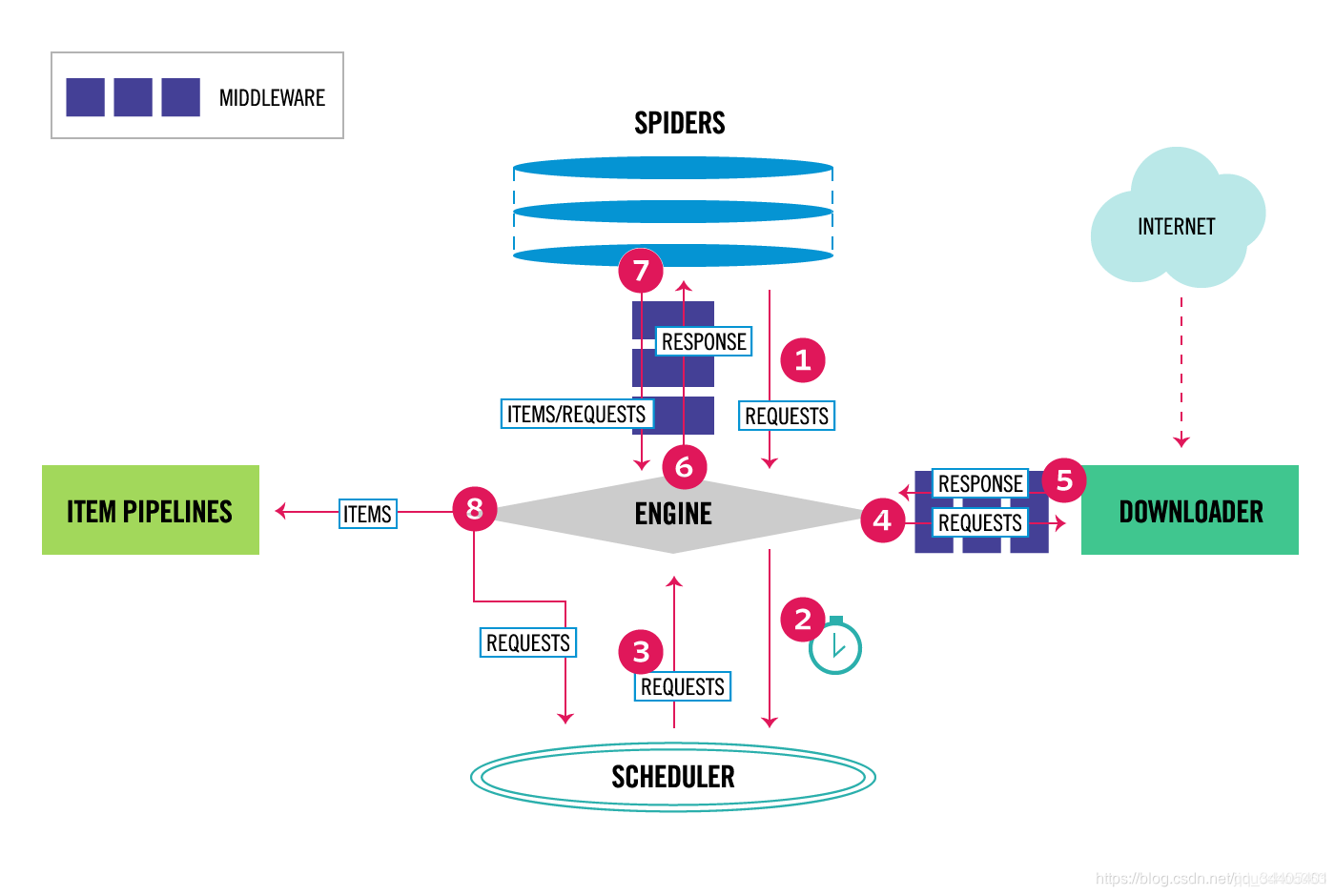
Scheduler从队列中拿出一个Request发送给Downloader执行下载,这个过程会经过Downloader Middleware的处理。另外,当Downloader将Request下载完成得到Response返回给Spider时会再次经过Downloader Middleware处理。
也就是说,Downloader Middleware在整个架构中起作用的位置是以下两个:
1.在Scheduler调度出队列的Request发送给Doanloader下载之前,也就是我们可以在Request执行下载之前对其进行修改。
2.在下载后生成的Response发送给Spider之前,也就是我们可以在生成Resposne被Spider解析之前对其进行修改。
Downloader Middleware的功能十分强大,修改User-Agent、处理重定向、设置代理、失败重试、设置Cookies等功能都需要借助它来实现。下面我们来了解一下Downloader Middleware的详细用法。
3.随机延时爬取
scrapy中有一个参数:DOWNLOAD_DELAY 或者 download_delay 可以设置下载延时,不过Spider类被初始化的时候就固定了,爬虫运行过程中没发改变。
方式一:这个项目下的所有爬虫延时(已尝试)
1.首先在middlewares.py里写
import random
import time
#延时爬取,随机时间
class RandomDelayMiddleware(object):
def __init__(self, delay):
self.delay = delay
@classmethod
def from_crawler(cls, crawler):
delay = crawler.spider.settings.get("RANDOM_DELAY", 10)
if not isinstance(delay, int):
raise ValueError("RANDOM_DELAY need a int")
return cls(delay)
def process_request(self, request, spider):
delay = random.randint(0, self.delay) #0到self.delay中随机延时,下面代码设置的是3
time.sleep(delay)
2.然后在settings.py里写
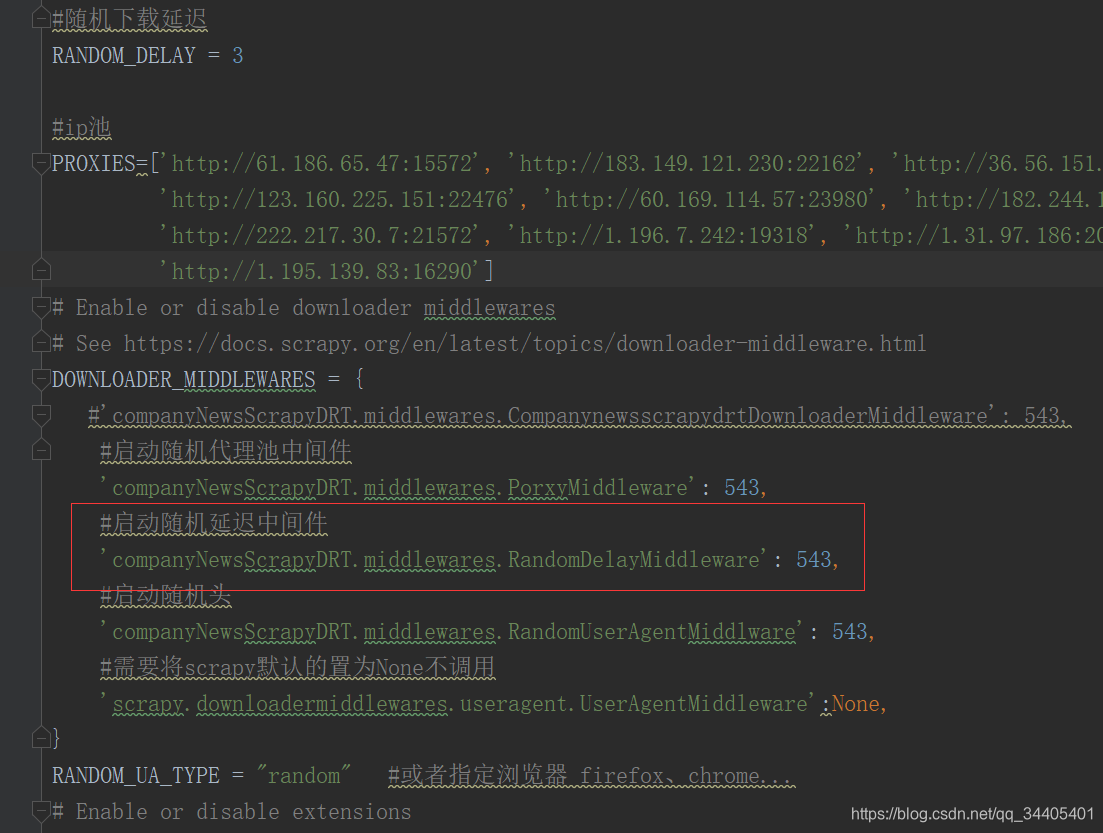
#随机下载延迟,这里延时3s,一般延时是15~90s
RANDOM_DELAY = 3
3.最后在settings.py的DOWNLOADER_MIDDLEWARES里启动随机延时
方式二:单独spider延时(未尝试)
1.首先了解scrapy项目中settings参数的使用详解里的custom_settings
转自:https://blog.csdn.net/he_ranly/article/details/85092065
custom_settings可以理解为spider的个性设置,通常我们在一个项目目录下会有很多个spider,但是只有一个settings.py全局配置文件,为了让不同的spider应用不同的设置,我们可以在spider代码中加入custom_settings设置。
例如:
spiders/somespider.py:
from ..custom_settings import *
class Spider1(CrawlSpider):
name = "spider1"
custom_settings = custom_settings_for_spider1
pass
class Spider2(CrawlSpider):
name = "spider2"
custom_settings = custom_settings_for_spider2
custom_settings.py:
custom_settings_for_spider1 = {
'LOG_FILE': 'spider1.log',
'CONCURRENT_REQUESTS': 100,
'DOWNLOADER_MIDDLEWARES': {
'spider.middleware_for_spider1.Middleware': 667,
},
'ITEM_PIPELINES': {
'spider.mysql_pipeline_for_spider1.Pipeline': 400,
},
}
custom_settings_for_spider2 = {
'LOG_FILE': 'spider2.log',
'CONCURRENT_REQUESTS': 40,
'DOWNLOADER_MIDDLEWARES': {
'spider.middleware_for_spider2.Middleware': 667,
},
'ITEM_PIPELINES': {
'spider.mysql_pipeline_for_spider2.Pipeline': 400,
},
}
在spider里有两个蜘蛛spider1、spider2里,我们引入了来自custom_settings的配置变量custom_settings_for_spider1、custom_settings_for_spider2,通过这些变量,我们分别对两个爬虫的log文件、并发数、应用的中间件和管道文件进行了设置。
custom_settings的优先级在命令行以下,比settings.py要高。
2.实现
转自:https://blog.csdn.net/mouday/article/details/81512748
1.middlewares.py的部分是一样的,这里就是多了个日志打印
# -*- coding:utf-8 -*-
import logging
import random
import time
class RandomDelayMiddleware(object):
def __init__(self, delay):
self.delay = delay
@classmethod
def from_crawler(cls, crawler):
delay = crawler.spider.settings.get("RANDOM_DELAY", 10)
if not isinstance(delay, int):
raise ValueError("RANDOM_DELAY need a int")
return cls(delay)
def process_request(self, request, spider):
delay = random.randint(0, self.delay)
logging.debug("### random delay: %s s ###" % delay)
time.sleep(delay)
2.直接在spider里写
custom_settings = {
"RANDOM_DELAY": 3,
"DOWNLOADER_MIDDLEWARES": {
"middlewares.random_delay_middleware.RandomDelayMiddleware": 999,
}
}
具体位置是:
*******引入头文件
class Spider1(CrawlSpider):
name = "spider1"
custom_settings = {
"RANDOM_DELAY": 3,
"DOWNLOADER_MIDDLEWARES": {
"middlewares.random_delay_middleware.RandomDelayMiddleware": 999,
}
}
pass
4.禁止cookies
上网搜‘浏览器禁止cookie’
5.若不禁止cookies,就加上header和cookie
转自:https://blog.csdn.net/sinat_41721615/article/details/99625952
5.1 方式一:cookies需要写成字典形式
通过yield scrapy.Request(url=url, headers=headers, cookies=cookies, callback=self.parse)添加,也就是添加请求头。
1.浏览器中cookies:
Cookie:_T_WM=98075578786; WEIBOCN_WM=3349; H5_wentry=H5; backURL=https%3A%2F%2Fm.weibo.cn%2Fdetail%2F4396824548695177; ALF=1568417075; SCF=Ap5VqXy_BfNHBEUteiYtYDRa04jqF4QPJBULzWo7c1c_noO0GpnJW3BqhIkH7JXJSwWhL0qSg69_Vici5P7NbmY.; SUB=_2A25wUOt6DeRhGeFM41AT9y3LyDSIHXVTuvUyrDV6PUJbktANLVXzkW1NQL_2tT4ZmobAs5b6HbIQwSRXHjjiRkzj; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFWyDsTszIBJPBJ6gn7ccSM5JpX5K-hUgL.FoME1hzES0eNe0n2dJLoI0YLxK-L1K.L1KMLxK-L1KzLBoeLxK-L12BLBK2LxK-LBK-LB.BLxK-LBK-LB.BLxKnLB-qLBoBLxKnLB-qLBoBt; SUHB=0S7CWHWuRz1aWf; SSOLoginState=1565825835
2.转化为字典格式:
def transform(self,cookies):
cookie_dict = {}
cookies = cookies.replace(' ','')
list = cookies.split(';')
for i in list:
keys = i.split('=')[0]
values = i.split('=')[1]
cookie_dict[keys] = values
return cookie_dict
3.因此headers和cookies是:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
cookies = {'_T_WM': '98075578786', 'WEIBOCN_WM': '3349', 'H5_wentry': 'H5', 'backURL': 'https%3A%2F%2Fm.weibo.cn%2Fdetail%2F4396824548695177', 'ALF': '1568417075', 'SCF': 'Ap5VqXy_BfNHBEUteiYtYDRa04jqF4QPJBULzWo7c1c_noO0GpnJW3BqhIkH7JXJSwWhL0qSg69_Vici5P7NbmY.', 'SUB': '_2A25wUOt6DeRhGeFM41AT9y3LyDSIHXVTuvUyrDV6PUJbktANLVXzkW1NQL_2tT4ZmobAs5b6HbIQwSRXHjjiRkzj', 'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9WFWyDsTszIBJPBJ6gn7ccSM5JpX5K-hUgL.FoME1hzES0eNe0n2dJLoI0YLxK-L1K.L1KMLxK-L1KzLBoeLxK-L12BLBK2LxK-LBK-LB.BLxK-LBK-LB.BLxKnLB-qLBoBLxKnLB-qLBoBt', 'SUHB': '0S7CWHWuRz1aWf', 'SSOLoginState': '1565825835'}
4.传值:
yield scrapy.Request(url=url, headers=headers, cookies=cookies, callback=self.parse)
5、修改COOKIES_ENABLED
当COOKIES_ENABLED是注释的时候scrapy默认没有开启cookie
当COOKIES_ENABLED没有注释设置为False的时候scrapy默认使用了settings里面的cookie
当COOKIES_ENABLED设置为True的时候scrapy就会把settings的cookie关掉,使用自定义cookie
所以需要在settings.py文件中设置COOKIES_ENABLED = True
并且在settings.py文件中设置ROBOTSTXT_OBEY = False #不遵守robotstxt协议
5.2 方式二:cookies不需要写成字典形式
在setting.py文件中添加cookies与headers — 最简单的方法
1.settings文件中给Cookies_enabled=False和DEFAULT_REQUEST_HEADERS解注释
2.在settings的DEFAULT_REQUEST_HEADERS配置的cookie就可以使用了

6. 随机user-agent
6.1 手动添加方式(未尝试)
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等,因此不同浏览器的user-agent不同。
1.可以把多个User-Agent作为一个配置在setting文件中
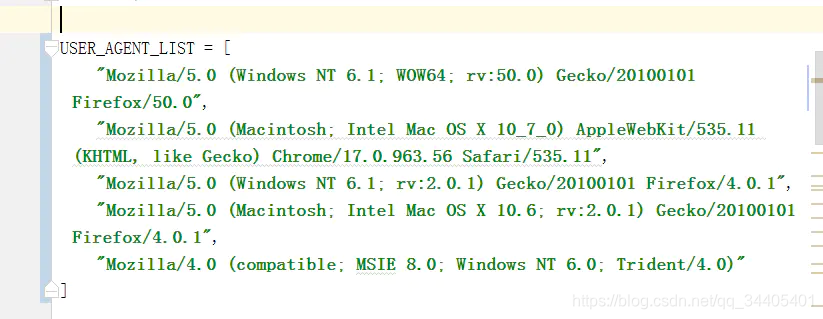
user_agent_list = [
"ua1",
"ua2",
"ua3",
]
然后再编写middlewares.py
class RandomUserAgentMiddleware(object):
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.user_agent_list = crawler.get("user_agent_list", [])
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
#方法一:需要在settings中将系统默认的请求头禁掉
request.headers.setdefault("User-Agent", random.choice(self.user_agent_list))
#方法二:不需要在settings中禁
request.headers['User-Agent'] = random.choice(self.user_agent_list)
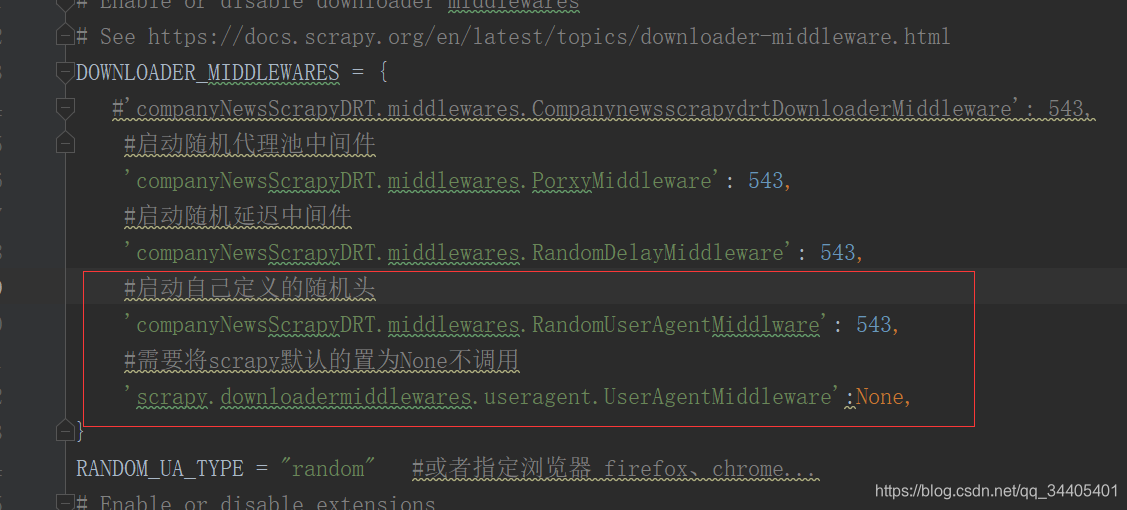
最后在settings.py中设置DOWNLOAD_MIDDLEWARES,将系统默认的随机请求头给禁掉,再添加我们自己定义的随机UserAgent,对应上面代码process_request中的第一个方法
6.2 自动方式,通过第三方库随机生成请求头
通过pip install fake-useragent,从而直接通过fake_useragent第三方库来随机生成请求头.
下载好后记得导入
最开始看的:https://www.cnblogs.com/qingchengzi/p/9633616.html
6.2.1 标准用法(已尝试)
1.middlewares.py中:
from fake_useragent import UserAgent
#随机更换user-agent
class RandomUserAgentMiddlware(object):
'''随机更换user-agent,基本上都是固定格式和scrapy源码中useragetn.py中UserAgentMiddleware类中一致'''
def __init__(self,crawler):
super(RandomUserAgentMiddlware,self).__init__()
self.ua = UserAgent()
#从配置文件settings中读取RANDOM_UA_TYPE值,默认为random,可以在settings中自定义
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE","random")
@classmethod
def from_crawler(cls,crawler):
return cls(crawler)
def process_request(self,request,spider):#必须和内置的一致,这里必须这样写
def get_ua():
return getattr(self.ua,self.ua_type)
request.headers.setdefault('User-Agent',get_ua())
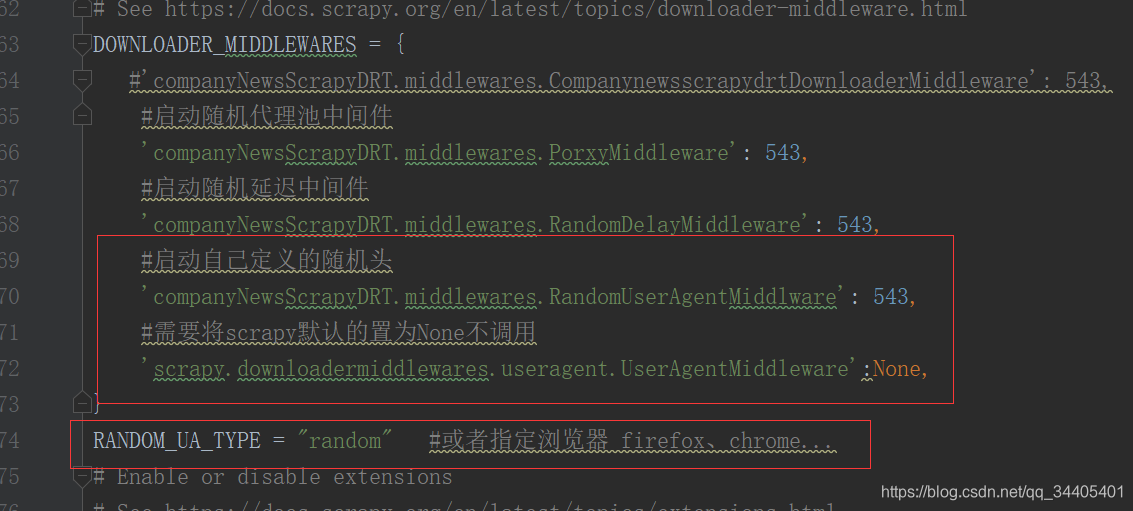
2.首先我们在setting配置文件中设置一个变量RANDOM_UA_TYPE,它的功能是可以按照我们自己配置的值来选择useragent。并且再把系统的禁掉,启动自己的
RANDOM_UA_TYPE:
# 随机选择UA
RANDOM_UA_TYPE = "random"
# 只选择ie的UA
RANDOM_UA_TYPE = "ie"
因此最终settings:
6.2.2 简易用法,用在request中,不是scrapy
转自:https://blog.csdn.net/qq_38251616/article/details/86751142
安装成功后,我们每次发送requests请求时通过random从中随机获取一个随机UserAgent,两行代码即可完成UserAgent的不停更换。
from fake_useragent import UserAgent
headers= {'User-Agent':str(UserAgent().random)}
r = requests.get(url, proxies=proxies, headers=headers, timeout=10)
6.2.3 报错解决办法:注意每次用前都要更新
我在使用fake_useragent中遇到如下的报错,在起初误认为是部分网站对某些UserAgent的屏蔽导致的fake_useragent调用出错,后来追究下来发现是由于fake_useragent中存储的UserAgent列表发生了变动,而我本地UserAgent的列表未更新所导致的,在更新fake_useragent后报错就消失了。
fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached
更新fake_useragent,在命令行中输入pip install -U fake-useragent即可完成更新,Python的其他包也可以用这种方法完成更新pip install -U 包名。
7.ip池(目前用到的最大杀招)
7.1 代码
1.setttings设置ip池:
ip是否可以使用可以用ip质量检查网站检查:http://www.jsons.cn/ping/

2.middlewares.py中添加:
import scrapy
import random
#代理ip池,随机更换ip
class ProxyMiddleware(object):
# 设置Proxy
def __init__(self, ip):
self.ip = ip
@classmethod
def from_crawler(cls, crawler):
return cls(ip=crawler.settings.get('PROXIES'))
def process_request(self, request, spider):
ip = random.choice(self.ip)
request.meta['proxy'] = ip
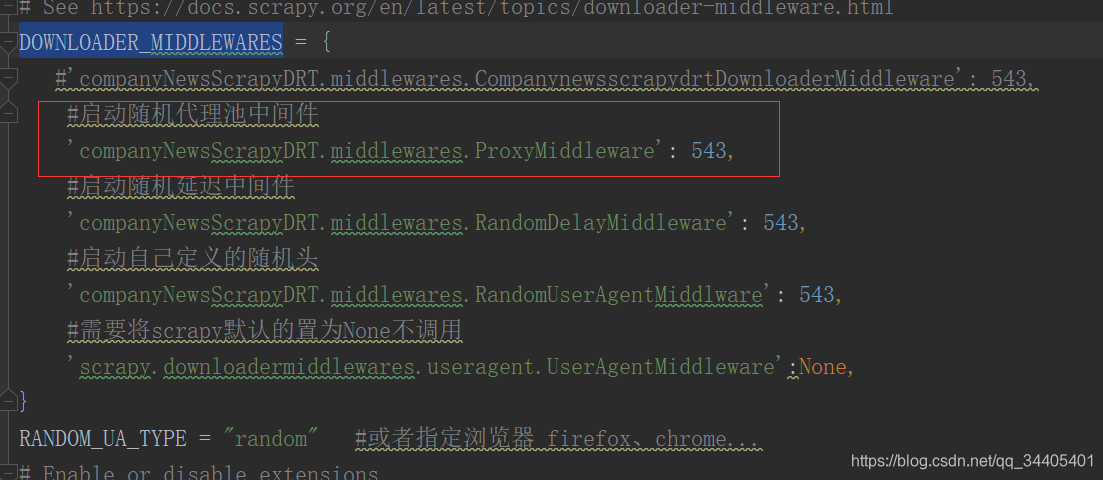
3.settings的DOWNLOADER_MIDDLEWARES中开启
7.2 问题一:运行爬虫后报10060或10061错误,就是服务器积极拒绝或连接方 一段时间后没有正确答复等,反正就是连接失败
7.2.1 第一步尝试:免费ip网站寻找ip
出现这种问题就是IP的问题,换一批就好,因此我在下面的网站中找了一批又一批ip:
快代理、代理66、有代理、西刺代理、guobanjia
但是一直还是有问题。
7.2.2 第二步尝试:网上自动获取可用id
转自:https://www.jianshu.com/p/8449b9c397bb
自动把成功的id放到proxies.txt中,但是用了成功的id还是不行
# *-* coding:utf-8 *-*
import requests
from bs4 import BeautifulSoup
import lxml
from multiprocessing import Process, Queue
import random
import json
import time
import requests
class Proxies(object):
"""docstring for Proxies"""
def __init__(self, page=3):
self.proxies = []
self.verify_pro = []
self.page = page
self.headers = {
'Accept': '*/*',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8'
}
self.get_proxies()
self.get_proxies_nn()
def get_proxies(self):
page = random.randint(1, 10)
page_stop = page + self.page
while page < page_stop:
url = 'http://www.xicidaili.com/nt/%d' % page
html = requests.get(url, headers=self.headers).content
soup = BeautifulSoup(html, 'lxml')
ip_list = soup.find(id='ip_list')
for odd in ip_list.find_all(class_='odd'):
protocol = odd.find_all('td')[5].get_text().lower() + '://'
self.proxies.append(protocol + ':'.join([x.get_text() for x in odd.find_all('td')[1:3]]))
page += 1
def get_proxies_nn(self):
page = random.randint(1, 10)
page_stop = page + self.page
while page < page_stop:
url = 'http://www.xicidaili.com/nn/%d' % page
html = requests.get(url, headers=self.headers).content
soup = BeautifulSoup(html, 'lxml')
ip_list = soup.find(id='ip_list')
for odd in ip_list.find_all(class_='odd'):
protocol = odd.find_all('td')[5].get_text().lower() + '://'
self.proxies.append(protocol + ':'.join([x.get_text() for x in odd.find_all('td')[1:3]]))
page += 1
def verify_proxies(self):
# 没验证的代理
old_queue = Queue()
# 验证后的代理
new_queue = Queue()
print('verify proxy........')
works = []
for _ in range(15):
works.append(Process(target=self.verify_one_proxy, args=(old_queue, new_queue)))
for work in works:
work.start()
for proxy in self.proxies:
old_queue.put(proxy)
for work in works:
old_queue.put(0)
for work in works:
work.join()
self.proxies = []
while 1:
try:
self.proxies.append(new_queue.get(timeout=1))
except:
break
print('verify_proxies done!')
def verify_one_proxy(self, old_queue, new_queue):
while 1:
proxy = old_queue.get()
if proxy == 0: break
protocol = 'https' if 'https' in proxy else 'http'
proxies = {protocol: proxy}
try:
if requests.get('http://www.baidu.com', proxies=proxies, timeout=2).status_code == 200:
print('success %s' % proxy)
new_queue.put(proxy)
except:
print('fail %s' % proxy)
if __name__ == '__main__':
a = Proxies()
a.verify_proxies()
print(a.proxies)
proxie = a.proxies
with open('proxies.txt', 'a') as f:
for proxy in proxie:
f.write(proxy+'\n')
