无监督学习1–聚类算法
什么是无监督学习?
无监督学习是指在未加标签的数据中,根据数据之间本身的属性特征和关联性对数据进行区分,相似相近或关联性强的数据放在一起,而不相似不相近、关联性不强的数据不放在一起。
无监督学习的本质是:利用无标签的数据学习数据的分布或数据与数据之间的关系。
无监督学习最常应用的场景是部分降维算法、聚类算法和关联算法。
关于有监督学习和无监督学习
在有监督学习中,例如分类问题,要求事先必须明确知道各个类别的信息,其建立的前提是所有待分类项都有一个类别与之对应。但实际上分类问题可能获取到的数据记录对应的类别信息无法明确,尤其是处理海量数据时,如果通过预处理对数据进行打标,以满足分类算法的要求,代价非常大。
有监督学习中最常见的是分类问题,而无监督学习中最常见的是聚类问题,聚类问题不依赖预定义的类和类标号的训练实例。关注事物本身的特征分析。
什么是聚类算法?
1.聚类分析
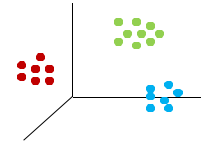
聚类分析是分析研究对象(样品或变量)如何按照多个方面的特征进行综合分类的一种多元统计方法,它是根据物以类聚的思想将相似的样品(或变量)归为一类。
把对象分为不同的类别,类别是依据数据的特征确定的。
把相似的东西放在一起,类别内部的差异尽可能小,类别之间的差异尽可能的大。
聚类分析的作用:
作为单独过程,用于对数据进行打标,即数据画像。
作为分类等其他学习任务的前驱过程,如聚类算法可以作为一些监督算法的前驱过程。
2.聚类分析的两个基本问题
(1)性能度量:
通过某种性能度量,对聚类结果的好坏进行评估。
聚类性能度量一般分两类:
外部指标:将聚类结果与某个“参考模型”进行比较,如将聚类学习结果与业务专家给出的划分结果进行比较。
内部指标:直接考察聚类结果不利用任何参考模型。
(2)距离计算:
常用的距离度量方法包括:欧几里得距离(简称欧氏距离)和余弦相似度,两者都是评定个体间差异的大小的。
欧氏距离会受指标不同单位刻度影响,需要先对数据进行标准化,在聚类问题中,如果两个样本点的欧氏距离越大,表示两者差异越大。如下表示两个p维的样本点Xi,Xj之间的欧式距离:
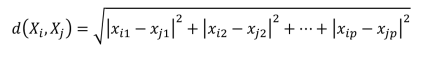
余弦相似度不会受指标刻度的影响,余弦值落于区间[-1 , 1] ,值越大,差异越小。

3.聚类算法的应用场景:
(1)挖掘内部
作为其他分析任务的前置过程。对数据本身进行一定的聚类后再进行其他建模算法,比如先聚类再分类。
(2)行业
离群点检测 :
离群点检测是数据挖掘中重要应用,任务就是发现与大部分观察对象显著不同的对象,大部分的数据挖掘方法会将这种差异信息视作噪声进行预处理,但是另外的一些应用中,离群点本身携带有重要的异常信息,是需要被关注和研究的。
离群点检测已经被广泛应用到电信、信用卡诈骗检测,贷款审批,电子商务,网络入侵和天气预报等领域,甚至可以利用离群点检测分析运动员的统计数据,以发现异常运动员。
应用方式:
利用聚类算法,找到远离其他簇的小簇;
首先聚类所有对象,然后评估对象属于簇的程度,对不同距离的点进行打分。
注意:离群点指的是与“普通”点相对应的“异常”点,而这些“异常”点往往值的注意。
用户画像构建方面:
根据客户数据,将相似性较高的客户聚为一类,打标签,进行客户类别细分。
业务推荐和精准营销方面:
通过构建用户画像进行业务推荐和精准营销。

4.常用聚类算法介绍
基于原型聚类(partitioning methods) :
基于原型:给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,算法首先给出一个初始的分组方法,以后通过反复迭代的方法改变分组,使得每一次改进之后的分组方案都较前一次好,而所谓好的标准就是:同一分组中的记录越近越好,而不同分组中的纪录越远越好,大部分划分方法是基于距离的;
如:K-Means算法,K-Mediods 算法
基于层次聚类(hierarchical methods) :
基于层次:对给定的数据集进行层次似的分解,直到某种条件满足为止。具体又可分为“自底向上”和“自顶向下”两种方案,可以是基于距离的或基于密度或连通性的;
如:Hierarchical Clustering算法、BIRCH算法
基于密度聚类(density-based methods) :
基于密度:其指导思想是只要一个区域中的点的密度大过某个阈值,就把它加到与之相近的聚类中去;
如:DBSCAN算法
注意:对不同的聚类算法应用选择原则如下:
是否适用于大数据量,算法的效率是否满足大数据量高复杂性的要求。
是否能应付不同的数据类型,能否处理符号属性。
是否能发现不同类型的聚类。
是否能应付脏数据或异常数据。
是否对数据的输入顺序不敏感
5.K-Means聚类算法
什么是K-Means?

基于各个样本点与各个聚集簇的中心点距离远近,进行划分的聚类算法。
K-Means算法首先选择K个初始质心,其中K是用户指定的参数,即所期望的簇的个数。这样做的前提是已经知道数据集中包含多少个簇,但很多情况下,我们并不知道数据的分布情况。如何有效地确定K值,提供以下几种方法:
从实际问题出发,人工指定比较合理的K值,通过多次随机初始化聚类中心选取比较满意的结果
(1)

(2)
枚举法:用不同的K值进行聚类
分别计算类内距离均值和类间距离均值之比,选择最小的那个K值。对不同K值都产生2次聚类,选择两次聚类结果最相似的K值
6.K-Means算法的优缺点
优点:
简单、易于理解、运算速度快;
对处理大数据集,该算法保持可伸缩性和高效性;
当簇接近高斯分布时,它的效果较好。
缺点:
在 K-Means算法是局部最优的,容易受到初始质心的影响;
在 K-Means算法中K值需要事先给定的,有时候K值的选定非常难以估计;
在簇的平均值可被定义的情况下才能使用,只能应用连续型数据;
该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的性能(时间和计算资源)开销是非常大的;
对噪声和孤立点数据敏感。
7.K-Mediods
基于原型的另一种聚类算法,也是对K-Means算法的一种改进。
算法描述
- 随机选取一组样本作为中心点集;
- 每个中心点对应一个簇;
- 计算各样本点到各个中心点的距离(如欧氏距离),将样本点放入距离中心点最短的那个簇中;
- 计算各簇中,距簇内各样本点距离的绝对误差最小的点,作为新的中心点;
- 如果新的中心点集与原中心点集相同,算法终止;如果新的中心点集与原中心点集不完全相同,返回2)。
