最初的数据库架构

如上图用户库,直接单库,读写都在这一个库上面
这种架构最先遇到的问题就是,随着业务增长带来的读瓶颈,因为大多数都是读多写少的问题
如何解决?
主从同步,读写分离,扩充读性能

主从会碰到什么问题?主从数据不一致

解决什么问题?分组+分片, 解决存储容量的问题,提升读性能,提升写性能
带来什么问题? sql扩展性的问题,牺牲掉sql的一些特性
没有解决什么问题?
1.高可用的问题
2.路由的问题
1.范围做路由: 1-1kw在0库,1kw-2kw在1库等等,
一、会导致负载不均衡等等,
假如uid前1kw的都是活跃用户,导致0库负载高。扩展性高
2.哈希:解决负载不均,数据量负载不均,访问不均,只要哈希的key比较均衡。
一、扩展性差,从2库到4库,需要迁移数据。
二、业务方需要关注路由规则。
解法一:搞个路由服务,解耦,
缺点:额外的一次调用服务
垂直拆分

user单库拆分成 user_base和user_ext, 访问频繁但是比较短的数据放到user_base库里面,访问比较少,数据比较多的放到user_ext
解决什么问题?
带来读性能的提升,为啥?数据buffer的缓存,关系型数据库以行存储的,数据少缓存的更多。
带来什么问题?
多次数据库访问,在业务层做聚合
没有解决什么问题?
高可用,扩展
垂直拆分和业务联系比较紧密,具体业务具体分析
二、高可用
典型的服务架构

判断系统是否高可用:关掉其中一台机器,试试访问是否正常,嘿嘿嘿
看其他层的高可用是如何保证的,对于数据层是否有启示?
反向代理层nginx高可用

web层高可用

server层高可用

缓存高可用

可以看出基本都是复制冗余
如何保证读库的高可用?

存在什么问题:
主从延迟的问题,数据冗余会引发一致性问题
怎么解决:
下面
如何保证写库的高可用?

存在什么问题?
数据一致问题,写复杂
怎么解决?
下面
读写高可用
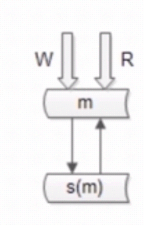
读写一致性问题,缓解
带来问题:
读性能缓解不了
如何提升读的性能?
1,索引
一、写性能降低
二、索引占用内存大,数据命中率低,读缓存也会有问题,太多索引也会引起读性能问题
有什么优化方案?

一主多从, 如果后台有大数据量的访问需求,拿出其中一个从库做备库,按自己的需要建立索引,读分离,减少对线上的影响,类似mongo的隐藏节点。
现在建索引都是在主库键,然后同步到从库上去。
主库其实没必要建索引:如果只写的话,带来的问题是配置不一致
2.提升读性能,增加从库
存在什么问题?
(1)从库越多,同步越慢
(2)数据不一致
怎么优化?
见下面
3.增加缓存
未服务化

已经服务化

带来的问题:
1.数据不一致 2.业务修改
缓存的最佳实践
Cache Aside Patern
对于读请求
1.先读cache,再读db
2.如果cache hit,则直接返回数据
3.如果cache miss,则访问db,并将数据set回缓存
写请求
1.淘汰缓存,而不是更新缓存
2.写操作先操作数据库,再淘汰缓存:
为什么淘汰缓存,而不是更新缓存

淘汰缓存带来的成本:
1.是多一次cache miss
更新缓存:
1.写并发的一致性问题
2.回写成本可能比较高,比较复杂的业务,可能需要取回db或者缓存里的数据,计算完再set回去。
为什么先写数据库,再淘汰缓存?
假设先淘汰缓存,会出现并发读写(概率大),可能不一致,但其实不根治

Cache Aside Patern存在什么问题?
如果先操作数据库,再淘汰缓存,在原子性被破坏时:
(1)修改数据库成功了
(2)淘汰缓存失败了
导致,数据库与缓存的数据不一致,原子性被破坏(概率小),可能不一致
四、一致性优化
为什么会出现?

这个不一致其实很短的
二、行业内的优化方案
方案一:忽略
任何脱离业务的架构设计都是耍流氓,绝大部分业务,例如:百度搜索,淘宝订单,QQ消息,58帖子都允许短时间内不一致
方案二:强制读主,缓存也会用的

方案三:选择性读主
1.写时记录

2.读时判断

如何实现?

中间件知道哪个库,哪个表,哪个key是写操作或者读操作。 对于需要比较强一致的读请求的话,由这个中间层去读主库,而不是去读从库,但是不需要比较一致性的读请求,还落到从库上。
使用redis或者memcache,将写请求的key设置一个比较短的过期时间(主从同步延时时间)。 读的话先去查看缓存里有没有,有的话表示发生过改动,去读主库。也就是db和缓存双写。
缓存不一致
为什么会出现这个问题?
写后立即读问题,主从同步延迟问题,脏数据进缓存,且一直不淘汰

优化方案:二次淘汰缓存,消除主从不一致带来的副作用

如何解决?
1.异步淘汰缓存,确保从库已经同步成功
2.设定超时时间,极限情况下有机会修正-》设置比较合适的过期时间,过期了会自动修正
3.获取自己在service层定时异步 二次淘汰
如何知道从库已经同步成功?
监听从库的binlog,当业务的某一个key在从库上写成功了,再去淘汰cache
五、扩展性优化
典型为服务架构数据库扩容
典型场景
特点:数据量大/吞吐量大/高可用
系统架构:微服务
数据层如何高可用
数据层如何扩展
综合情况

要解决什么问题?
一.吞吐量持续增大,如何进一步增加实例?
二.数据量持续增大,如何进一步水平扩展?
1.停服扩容。最简单的

2.追日志
1.记录日志(服务升级),对db写操作的要写一行日志,打印时间,db,table,primary_key等等

2.数据迁移(小工具1)

3.数据补齐(小工具2),日志里记录的增量数据
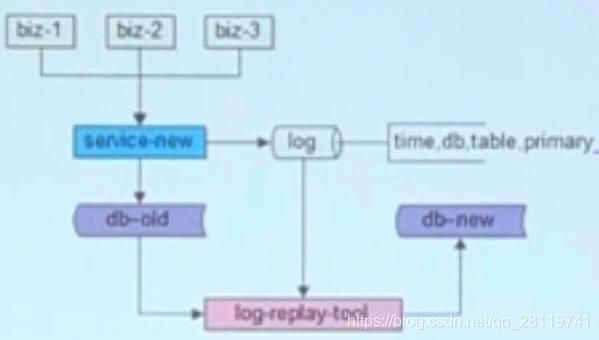
4.数据校验(小工具3)

3.双写



假设某一条记录在迁移,突然这条数据被删了,旧库没了,新库还在迁移,所以就又把这条数据写进去了,所以我们需要迁移校验工具
4.双倍扩容法,只支持2库变4库,4库变8库等双倍扩容,但不需要改代码
1.改配置

2.reload配置

3.收尾

4.最终结果

各类业务场景水平切分实践
如何拆?用哪个属性拆分?
四类典型场景
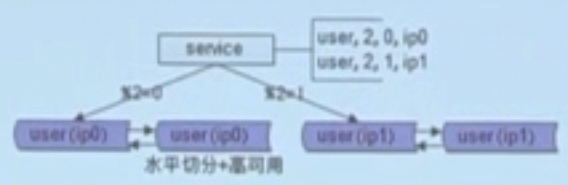
单key 用户库如何拆分:user(uid,xxoo)
1对多 帖子库如何拆分:tiezi(tid,uid,xxoo)
多对多 好友库如何拆分:friend(uid,friend_uid,xxoo)
多key 订单库如何拆分:order(oid, buyer_id,seller_id, xxoo)
用户库,10亿数据量
user(uid,uname,passwd,age,sex,create_time,...)
业务需求
(1)1%登录请求 =》where uname=xxx and passwd=xxx
(2)99%查询请求 =》where uid=xxx
方案:按uid分库分表
那login_name上的查询怎么样?
用户中心实践
1.索引表
建立个索引表有2个字段,uid和login_name
多了一次数据库访问
索引表存不下,再按login_name分库
2.缓存映射法
原理相同,使用redis等记录
3.login_name生成uid
会有冲突,很少这么干
4.基因法:应用场景比较局限, 基因不可变。不支持多种登录方式:邮箱,手机号等等。
这个3位最多支持8个库,应该多考虑最多的库数,决定多少位。

除了login_name后台复杂,批量,分页的查询怎么办?
前台与后台分离:

通过数据层解耦
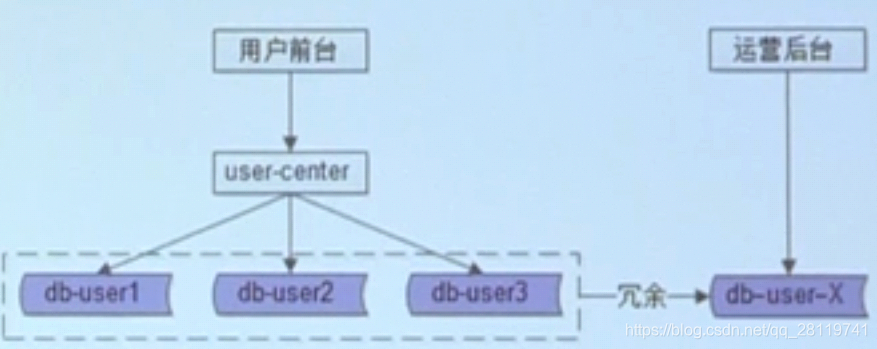
通过服务层解耦

帖子库拆分?
帖子库,15亿数据量
tiezi(tid, uid, title, content, time);
业务需求如下:
(1)查询帖子详情(90%请求)
select * from tiezi where tid = $tid
(2)查询用户所有发帖(10%请求)
select *from tiezi where uid=$uid
帖子中心实战
按照uid分库
同一个uid的所有tid在一个库
tid中融入uid基因

当然也可以和上面引入临时表来解决,存储的就比较多了
除了uid/tid,标题/内容的查询怎么办?使用搜索引擎

引入的问题: 数据不一致
定期全量检测并修复数据
好友库拆分实战
好友库,1亿数据量
friend(uid,friend_uid,nick,memo,xxoo);
业务需求如下:
(1)查询我的好友(50%请求)=》用于界面展示
select friend_uid from friend where uid = $my_uid
(2)查询加我为好友的用户(50%请求)=》用户反向通知
select uid from friend where friend_uid = $my_uid
不管通过uid/fuid哪个分库,只能满足一个查询,这时候的基因法不好用了,因为我们控制不了fuid,意思就是我们不知道哪个uid会加好友,所以加不了基因。
好友中心实践:数据冗余
服务同步冗余

服务异步冗余

线下异步冗余

数据冗余有什么副作用?
数据不一致
如何保证数据一致性?
最终一致性是常见实践
实践:
1.线下扫全库:
缺点:慢, 一致性的数据会被多次扫描

2.线下扫增量

3.线上实时检测

订单库如何拆分?
订单库,10亿数据量
order(oid,buyer_id,seller_id, order_info, xxoo)
业务需求如下:
(1)查询订单信息(80%请求)
select * from order where oid = $oid
(2)查询我买的东西(19%请求)
select * from order where buyer_id = $my_uid
(3)查询我卖出的东西(1%请求)
select * from order where seller_id = $my_uid
基因法和数据冗余综合应用
---------------------------------------------------------------------------------以下内容废弃----------------------------------------------------------------------------------------
1.中间件
中间件知道哪个库,哪个表,哪个key是写操作或者读操作。 对于需要比较强一致的读请求的话,由这个中间层去读主库,而不是去读从库,但是不需要比较一致性的读请求,还落到从库上。
如何实现?
使用redis或者memcache,将写请求的key设置一个比较短的过期时间(主从同步延时时间)。 读的话先去查看缓存里有没有,有的话表示发生过改动,去读主库。也就是db和缓存双写。
2.强制读主库
这个从库就没啥意义了,读写都在写库上
会有什么问题?
主库单点问题,不高可用,也没有解决读性能
怎么解决?
使用双主, 主主之间同步。
如何解决读性能问题
服务化+缓存
有什么问题? 缓存不一致
缓存不一致,如何解决?
1.Cache Aside Patern
淘汰缓存,而不是更新缓存
读请求有缓存先读缓存,如果数据命中直接返回,未命中读从库
写请求,先写数据库,再淘汰缓存:
为什么会不一致?
问题1:先写数据库,再淘汰缓存,立刻发生了个读操作, 主从同步延时,从库还是旧数据,又把脏数据放到了缓存里面。
如何解决?
异步淘汰缓存,确保从库已经同步成功
设定超时时间,极限情况下有机会修正-》设置比较合适的过期时间,过期了会自动修正
如何知道从库已经同步成功?
监听从库的binlog,当业务的某一个key在从库上写成功了,再去淘汰cache
