一、确保目标区间足够大
STL容器在被添加时(通过insert、push_front、push_back等)自动扩展它们自己来容纳新对象。这是一个很不错的特性,有些程序员因为这个信仰而被麻痹,认为他们不必担心要为容器中的对象腾出空间,因为容器自己可以照顾好这些。但是当程序员想向容器中插入对象但并没有告诉STL他们所想的时,问题出现了。这里有一个常见例子:
int transmogrify(int x); // 这个函数从x产生一些新值
vector<int> values; // 把数据放入values
...
vector<int> results;
transform(values.begin(), // 把transmogrify应用于
values.end(), // values中的每个对象
results.end(), // 把这个返回的values
transmogrify); // 附加到results的末尾
// 这段代码有bug!
//因为*results.end()没有对象,*(results.end()+1)也没有!调用transform是错误的,因为它会给不存在的对象赋值。STL是一个库,不是你肚子里的蛔虫。在本例中,说“请把transform的结果放入叫做results容器的结尾”的方式是调用back_inserter来产生指定目标区间起点的迭代器:
vector<int> results;
transform(values.begin(), // 把transmogrify应用于
values.end(), // values中的每个对象,
back_inserter(results), // 在results的结尾
transmogrify); // 插入返回的values在内部,back_inserter返回的迭代器会调用push_back,所以你可以在任何提供push_back的容器上使用back_inserter(也就是任何标准序列容器:vector、string、deque和list)。如果你想让一个算法在容器的前端插入东西,你可以使用front_inserter。在内部,front_inserter利用了push_front,所以front_insert只和提供那个成员函数的容器配合(也就是deque和list):
... // 同上
list<int> results; // results现在是list
transform(values.begin(),
values.end(), // 在results前端
front_inserter(results), // 以反序
transmogrify); // 插入transform的结果front_inserter让你强制算法在容器前端插入它们的结果,back_inserter让你告诉它们把结果放在容器后端,有点惊人的是inserter允许你强制算法把它们的结果插入容器中的任意位置:
vector<int> values; // 同上
...
vector<int> results; // 同上,只是现在
... // 在调用transform前results已经有一些数据
transform(values.begin(),
values.end(),//把transmogrify的结果插入results的中间
inserter(results, results.begin() + results.size()/2),
transmogrify); 正确高效地写这个例子的代码的方法是使用reserve和插入迭代器:
vector<int> values; // 同上
vector<int> results;
results.reserve(results.size() + values.size()); // 避免不断地重新分配内存
transform(values.begin(),
values.end(), // 把transmogrify的结果
back_inserter(results), // 写入results的结尾,
transmogrify); // 处理时避免了重新分配【Note】:
(1)无论何时你使用一个要求指定目的区间的算法,确保目的区间已经足够大或者在算法执行时可以增加大小。如果你选择增加大小,就使用插入迭代器,比如ostream_iterators或从back_inserter、front_inserter或inserter返回的迭代器。
二、了解各种与排序有关的选择
1、patical_sort:获取前N个元素,这个N个元素已排序;
比如,如果你有一个Widget的vector,你想选择20个质量最高的Widget发送给你最忠实的客户,你需要做的只是排序以鉴别出20个最好的Widget,剩下的可以保持无序。你需要的是部分排序,有一个算法叫做partial_sort,它能准确地完成它的名字所透露的事情:
bool qualityCompare(const Widget& lhs, const Widget& rhs)
{
// 返回lhs的质量是不是比rhs的质量好
}
...
partial_sort(
widgets.begin(), // 把最好的20个元素
widgets.begin() + 20, // (按顺序)放在widgets的前端
widgets.end(),
qualityCompare);
... // 使用widgets...调用完partial_sort后,widgets的前20个元素是容器中最好的而且它们按顺序排列,也就是,质量最高的Widget是widgets[0],第二高的是widgets[1]等。这就是你很容易把最好的Widget发送给你最好的客户,第二好的Widget给你第二好的客户等。
2、nth_element :获取任意顺序的前N个元素
如果你关心的只是能把20个最好的Widget给你的20个最好的客户,但你不关心哪个Widget给哪个客户,partial_sort就给了你多于需要的东西。在那种情况下,你需要的只是任意顺序的20个最好的Widget。STL有一个算法精确的完成了你需要的,虽然名字不大可能从你的脑中迸出。它叫做nth_element。
nth_element (
widgets.begin(), // 把最好的20个元素
widgets.begin() + 20, // 放在widgets前端,
widgets.end(), // 但不用担心
qualityCompare); // 它们的顺序正如你所见,调用nth_element本质上等价于调用partial_sort。它们结果的唯一区别是partial_sort排序了在位置1-20的元素,而nth_element不。但是两个算法都把20个质量最高的Widget移动到vector前端。
nth_element除了能帮你找到区间顶部的n个元素,它也可以用于找到区间的中值或者找到在指定百分点的元素:
vector<Widget>::size_type goalOffset = // 指出兴趣的Widget
0.25 * widgets.size(); // 离开始有多远
nth_element(
begin, begin + goalOffset,
end, qualityCompare); // 找到质量值为75%的Widget
... // goalPosition现在指向质量等级为75%的Widget3、stable_sort:sort的稳定版本
partial_sort是不稳定的。nth_element、sort也没有提供稳定性,但是有一个算法——stable_sort——它完成了它的名字所透露的。如果当你排序的时候你需要稳定性,你可能要使用stable_sort。STL并不包含partial_sort和nth_element的稳定版本。
4、partition :将集合分隔为满足和不满足某个标准两个区间
比如,移动所有质量等级为2或更好的Widget到widgets前端,我们定义了一个函数来鉴别哪个Widget是这个级别。
bool hasAcceptableQuality(const Widget& w)
{
// 返回w质量等级是否是2或更高;
}传这个函数给partition:
vector<Widget>::iterator goodEnd =
partition( // 把所有满足hasAcceptableQuality
widgets.begin(), // 的widgets移动到widgets前端,
widgets.end(), // 并且返回一个指向第一个
hasAcceptableQuality); // 不满足的widget的迭代器此调用完成后,从widgets.begin()到goodEnd的区间容纳了所有质量是1或2的Widget,从goodEnd到widgets.end()的区间包含了所有质量等级更低的Widget。如果在分割时保持同样质量等级的Widget的相对位置很重要,我们自然会用stable_partition来代替partition。
算法sort、stable_sort、partial_sort和nth_element需要随机访问迭代器,所以它们可能只能用于vector、string、deque和数组。对标准关联容器排序元素没有意义,因为这样的容器使用它们的比较函数来在任何时候保持有序。唯一我们可能会但不能使用sort、stable_sort、partial_sort或nth_element的容器是list,list通过提供sort成员函数做了一些补偿。(有趣的是,list::sort提供了稳定排序。)所以,如果你想要排序一个list,你可以,但如果你想要对list中的对象进行partial_sort或nth_element,你必须间接完成:
把元素拷贝到一个支持随机访问迭代器的容器中,然后对它应用需要的算法;
建立一个list::iterator的容器,对那个容器使用算法,然后通过迭代器访问list元素;
使用有序的迭代器容器的信息来迭代地把list的元素接合到你想让它们所处的位置。
5、关于排序算法的总结:
如果你需要在vector、string、deque或数组上进行完全排序,你可以使用sort或stable_sort。
如果你有一个vector、string、deque或数组,你只需要排序前n个元素,应该用partial_sort。
如果你有一个vector、string、deque或数组,你需要鉴别出第n个元素或你需要鉴别出最前的n个元素,而不用知道它们的顺序,nth_element是你应该注意和调用的。
如果你需要把标准序列容器的元素或数组分隔为满足和不满足某个标准,你大概就要找partition或stable_partition。
如果你的数据是在list中,你可以直接使用partition和stable_partition,你可以使用list的sort成员函数来代替sort和stable_sort。如果你需要partial_sort或nth_element提供的效果,你就必须间接完成这个任务。
三、如果你真的想删除元素,就在类似remove的算法后接上erase
先看一个错误的实例:
vector<int> v; // 建立一个vector<int> 用1-10填充它
v.reserve(10);
for (int i = 1; i <= 10; ++i) {
v.push_back(i);
}
cout << v.size(); // 打印10
v[3] = v[5] = v[9] = 99; // 设置3个元素为99
remove(v.begin(), v.end(), 99); // 删除所有等于99的元素
cout << v.size(); // 仍然是10!remove不是真正意义上的删除,因为它做不到!它只是使所有要被删除的元素放在尾部,不用被删除的元素放在前部。
正确的删除元素的方法:
vector<int> v;
v.erase(remove(v.begin(), v.end(), 99), v.end()); // 真的删除所有等于99的元素
cout << v.size(); // 现在返回7
list<int> li; // 建立一个list
li.remove(99); // 除去所有等于99的元素:真的删除元素,所以它的大小可能改变了【Note】:
(1)remove_if ,unique和remove类似,都需要跟erase连用才可以真正删除数据,同样,对于list是个特殊。
四、提防在指针的容器上使用类似remove的算法
采用remove/erase方式删除指针容器中的数据会造成内存泄漏,如:
class Widget{
public:
...
bool isCertified() const; // 这个Widget是否通过检验
...
};
vector<Widget*> v; // 建立一个vector然后用动态分配的Widget
v.push_back(new Widget); // 的指针填充
v.erase(remove_if(v.begin(), v.end(), // 删除未通过检验的
not1(mem_fun(&Widget::isCertified))), // Widget指针
v.end());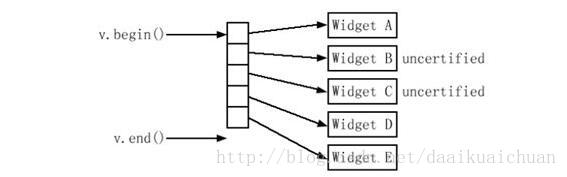
Widget C和Widget B的内存不会被释放(“要被删除”的指针已经被那些“不会被删除”的指针覆盖了),造成内存泄漏,使用智能指针可以避免这一情况。
【Note】:
(1)当容器中存放的是指向动态分配的对象的指针的时候,应该避免使用remove和类似的算法(remove_if和unique)。
五、用accumulate或for_each来统计区间
本条款总结了用自定义的方式统计(summarize)区间的方法,主要有两种(在头文件中):
1、accumulate存在两种形式
第一种是: 带有一对迭代器和初始值的形式,它可以返回初始值加由迭代器划分出的区间中值的和:
list<double> ld; // 建立一个list
... // 放一些double进去
double sum = accumulate(ld.begin(), Id.end(), 0.0); // 计算它们的和,从0.0开始(也可以是int)另一种形式带有一个初始和值与一个任意的统计函数,实例:
//统计字符串的长度总和
string::size_type
stringLengthSum(string::size_type sumSoFar,const string& s)
{
return sumSoFar + s.size();
}
set<string> ss; // 建立字符串的容器,
... // 进行一些操作
string::size_type lengthSum =
accumulate(
ss.begin(), // 把lengthSum设为对
ss.end(), // ss中的每个元素调用stringLengthSum的结果,
0, // 使用0作为初始统计值
stringLengthSum); 2、for_each
带有一个区间和一个函数(一般是一个函数对象)来调用区间中的每个元素,但传给for_each的函数只接收一个实参(当前的区间元素),而且当完成时for_each返回它的函数。值得注意的是,传给(而且后来要返回)for_each的函数可能有副作用。
除了副作用问题,for_each和accumulate的不同主要在两个方面。首先,accumulate的名字表示它是一个产生区间统计的算法,for_each听起来好像你只是要对区间的每个元素进行一些操作,而且,当然,那是那个算法的主要应用。用for_each来统计一个区间是合法的,但是它没有accumulate清楚。