一、哈夫曼树
1、哈夫曼树简介
哈夫曼树(Huffman)树又称最优二叉树,是指对于一组带有确定权值的叶子结点所构造的具有带权路径长度最短的二叉树。从树中一个结点到另一个结点之间的分支构成了两结点之间的路径,路径上的分支个数称为路径长度。二叉树的路径长度是指由根结点到所有叶子结点的路径长度之和。如果二叉树中的叶子结点都有一定的权值,则可将这一概念拓展:设二叉树具有n个带权值的叶子结点,则从根结点到每一个叶子结点的路径长度与该叶子结点权值的乘积之和称为二叉树路径长度,记做:
WPL = W1L1 + W2L2 + ...... + WnLn;其中:n为二叉树中叶子结点的个数;Wk为第k个叶子的权值;Lk为第k个叶子结点的路径长度。
2、哈夫曼树的构造过程
1. 对数据中出现过的元素各产生一个树叶节点,并赋予其出现的频率。
2. 令N为T1和T2的父节点,其中T1和T2是出现频率最低的两个节点,令N的频率为T1和T2的频率之和。
3. 消去两个节点,插入N节点,重复前面的步骤。


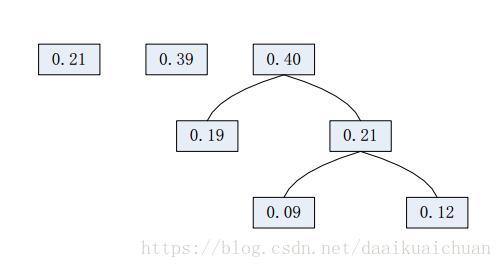
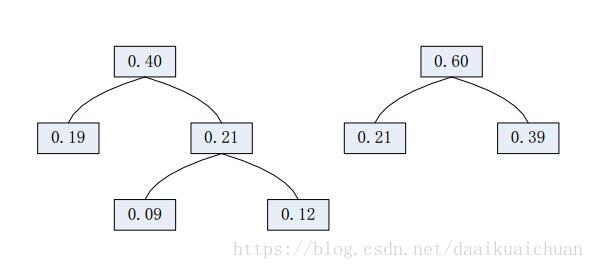
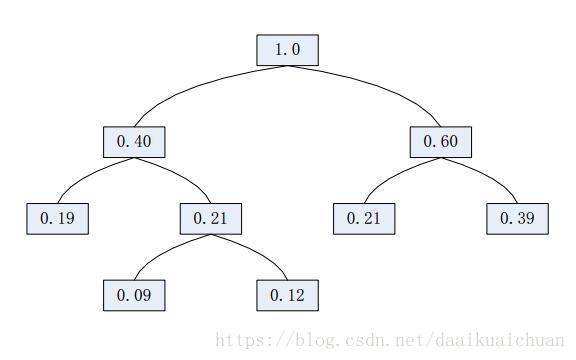
3、构造哈夫曼树的demo:
#include <iostream>
#include <deque>
#include <vector>
#include <tuple>
#include <algorithm>
using namespace std;
typedef struct HuffumanTree
{
int weight;//权值
HuffumanTree *left;//左儿子节点
HuffumanTree *right;//右儿子节点
}*htree;
tuple<htree, int> creat_tree(vector<int> &vec)
{
int ans = 0;
deque<htree> forest;//森林
const int sz = vec.size();
for (int i = 0; i < sz; ++i)//将所有节点看作n棵树的森林
{
htree ptr = new HuffumanTree;
ptr->weight = vec[i];
ptr->left = ptr->right = nullptr;
forest.push_back(ptr);
}
for (int i = 0; i < sz - 1; ++i)
{
//对所有节点的权值排序(也可以使用优先级队列)
sort(forest.begin(), forest.end(), [](htree a, htree b) { return a->weight < b->weight; });
//选取权值最小的两棵树,并删除
auto a = forest.front();
forest.pop_front();
auto b = forest.front();
forest.pop_front();
//构建新的树,加入到队列
htree ptr2 = new HuffumanTree;
ptr2->weight = a->weight + b->weight;
ptr2->left = a;
ptr2->right = b;
forest.push_back(ptr2);
//累加权值
ans += ptr2->weight;
}
auto root = forest.front();
deque<htree>().swap(forest);
return make_tuple(root, ans);
}
void print_tree(htree root)
{
if (root != nullptr)
{
//打印所有节点及其左右儿子的权值
cout << root->weight << endl;
if (root->left != nullptr)
cout << root->left->weight << endl;
else
cout << "no left child" << endl;
if (root->right != nullptr)
cout << root->right->weight << endl;
else
cout << "no right child" << endl;
print_tree(root->left);
print_tree(root->right);
}
}
int main(int argc, char const *argv[])
{
vector<int> a = { 1, 2, 2, 5, 9 };
htree root;
int sum;
tie(root, sum) = creat_tree(a);
cout << sum << endl;
print_tree(root);
return 0;
}二、哈夫曼编码
哈夫曼编码(Huffman Coding)是一种编码方法,哈夫曼编码是可变字长编码(VLC)的一种。
哈夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
1、构建哈夫曼编码
首先根据数据出现的频率建立一棵哈夫曼树,假如我有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1,那么构建的哈夫曼树如下所示:
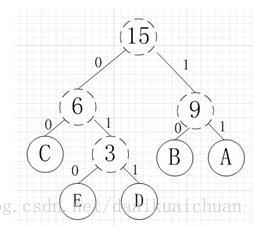
如果节点在父结点左侧,则编码为 0,若在右侧,则编码为 1。
所以各字符对应的编码为:A->11,B->10,C->00,D->011,E->010