1 分布式体系
如下图:
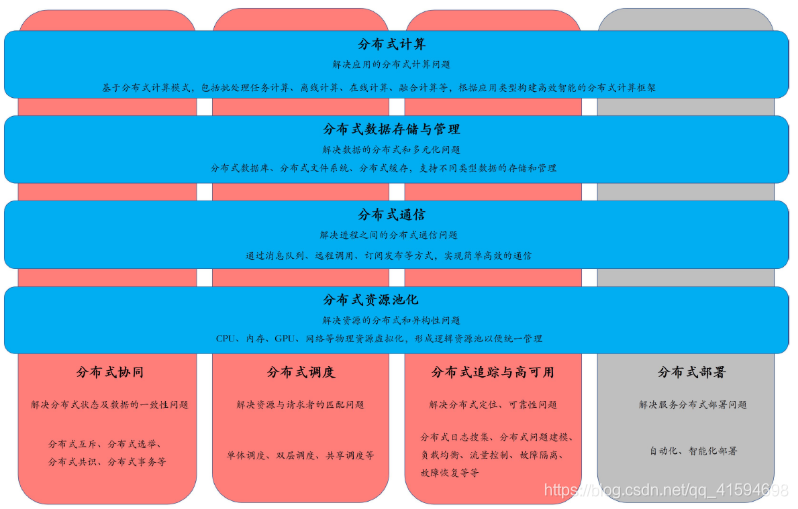
分布式资源池化、分布式通信、分布式数据存储与管理、分布式计算四大体系的划分符合业务架构设计的一般规律:“在一定资源上,进行一定通信,通过一定计算,完成一定数据的加工和处理,从而对外提供特定的服务”
而在分布式环境下,无论是资源、通信、数据还是计算,都需要去解决协同、调度、追踪高可用、部署的问题
2 什么是分布式
让我们从最原始的架构开始演变
- 单机模式:穷逼模式(穷逼:???老子就那么点用户,花那么多钱干啥?
概念:所有应用程序和数据均部署在一台电脑或服务器上,由一台计算机完成所有的处理
优点:功能、代码和数据集中,便于维护、管理和执行
缺点:单个计算机的处理能力取决于CPU和内存等硬件,但硬件的发展速度和性能是有限的,而且升级硬件的性价比也是要考虑的,因此CPU和内存等硬件的性能将成为单机模式的瓶颈;此外,将所有任务都交给一台计算机,也会存在单点失效问题。
- 数据并行/数据分布式模式:为解决单机模式的问题,并行计算得到了发展,进而出现了数据并行(数据分布式)模式
概念:
并行计算采用消息共享模式使用多台计算机并行运行或执行多项任务;
核心原理是每台计算机上执行相同的程序,将数据进行拆分放到不同的计算机上进行计算;
首先需要把单机模式中的应用和数据分离,才可能实现对数据的拆分,然后对同类型的数据进行拆分,比如不同服务器上的应用去不同的数据库上获取数据执行任务
好处:利用多台计算机并行处理多个请求,可以在相同的时间内完成更多的请求处理,解决了单机模式的计算效率瓶颈问题
缺点:
1 相同的应用部署到不同的服务器上,当大量用户请求过来时,如何能比较均衡地转发到不同的应用服务器上?负载均衡器
2 当请求量较大时,对数据库的频繁读写操作,使得数据库的 IO 访问成为瓶颈,怎么解决这个问题?使用读写分离
3 当有些数据成为热点数据时,会导致数据库访问频繁,压力增大,怎么解决这个问题?引入缓存机制,一方面可以减轻数据库的压力,另一方面也可以提升查询效率
4 如果单个请求特别复杂,数据并行模式的整体计算效率还是不够高,这个问题此模式没有办法解决,因此新模式需要解决此问题,也就是对提升单个任务的执行性能及降低时延无效
- 任务并行/任务分布式模式:提高单个任务的执行性能/缩短单个任务的执行时间
概念:
将单个复杂的任务拆分为多个子任务,从而使得多个子任务可以在不同的计算机上并行执行,每个子任务可以在多台计算机上运行
两个核心步骤:将单任务拆分成多个子任务;让多个子任务并行执行。
优点:你懂的
缺点:设计上复杂了很多
- 那分布式到底是啥?
分布式其实就是将相同或相关的程序运行在多台计算机上,从而实现特定目标的一种计算方式
数据并行/数据分布式模式和任务并行/任务分布式模式都算是分布式的一种实现,对于性能、可用性及可扩展性的要求产生了不同的分布式实现
那到底啥时候采用数据并行/数据分布式模式,啥时候采用任务并行/任务分布式模式呢?
一个简单的原则为:
任务执行时间短,数据规模大、类型相同且无依赖,则可采用数据并行/数据分布式模式;(别直接上任务并行/任务分布式模式,有点难顶的)
如果任务复杂、执行时间长,且任务可拆分为多个子任务,则考虑任务并行/任务分布式模式;
在实际业务中,通常是这两种模式并用
分布式和并行计算的区别:
分布式核心在于将任务拆分到不同的服务器上,强调数据、任务上的并行;
并行计算核心在于充分利用服务器CPU、内存等资源,可以将单个任务以多进程多线程方式来运行,强调单机上运算的并行;
分布式中每台服务器采用并行计算可以提高性能
#3 分布式系统的指标
首先要明确,分布式的目的是用更多的机器,处理更多的数据和更复杂的任务;因此性能、资源、可用性和可扩展性是分布式系统的重要指标
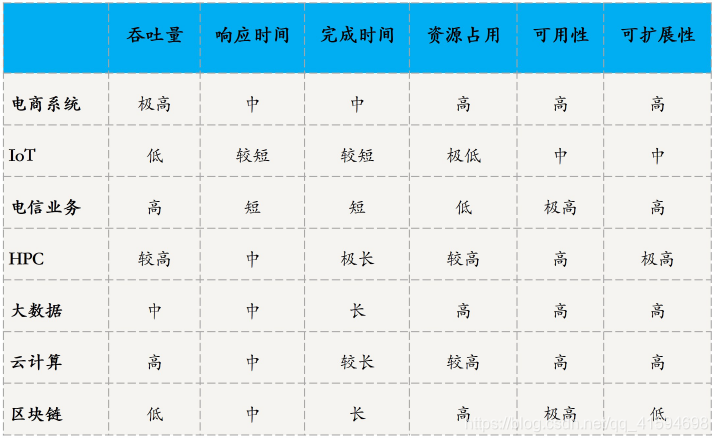
不同业务场景对指标的要求高低不同,需要根据业务来分析:
3.1 性能
性能用于衡量一个系统处理各种任务的能力
常见的性能指标(彼此可能互相冲突):吞吐量(Throughput)、响应时间(Response Time)、完成时间(Turnaround Time)
吞吐量:系统在一定时间内可以处理的任务数,这个指标可以非常直接地体现一个系统的性能
QPS,可确保某给定响应时间下的每秒到达的查询数的上限(简单理解:查询数每秒,用于衡量一个系统每秒处理的查询数);
这个指标通常用于读操作,越高说明对读操作的支持越好
TPS,即事务数每秒,用于衡量一个系统每秒处理的事务数;
这个指标通常对应于写操作,越高说明对写操作的支持越好
BPS,即比特数每秒,用于衡量一个系统每秒处理的数据量;
对于一些网络系统、数据管理系统,不能简单地按照请求数或事务数来衡量其性能,因为请求与请求、事务与事务之间也存在着很大的差异,比方说,有的事务需要写入更多的数据
响应时间:系统响应一个请求或输入需要花费的时间,这个指标直接影响到用户体验
完成时间:系统真正完成一个请求或处理需要花费的时间,这个指标对于需要计算海量数据或大规模的任务比较重要
3.2 资源
资源指一个系统提供正常能力需要占用的硬件资源,如 CPU、内存、硬盘等
一个系统在没有任何负载时的资源占用,叫做空载资源占用,体现了这个系统自身的资源占用情况。
对于同样的功能,空载资源占用越少,说明系统设计越优秀,越容易被用户接受。
一个系统满额负载时的资源占用,叫做满载资源占用,体现了这个系统全力运行时占用资源的情况,也体现了系统的处理能力。
同样的硬件配置上,运行的业务越多,资源占用越少,说明这个系统设计得越好。
3.3 可用性
可用性指系统在面对各种异常时可以正确提供服务的能力,可以用系统停止服务的时间与总的时间之比衡量,也可以用某功能的失败次数与总的请求次数之比来衡量
注意与可靠性的区别:可靠性通常用来表示一个系统完全不出故障的概率,可用性则更多的是指在允许部分组件失效的情况下,一个系统对外仍能正常提供服务的概率
3.4 可扩展性
可扩展性指分布式系统通过扩展集群机器规模提高系统性能 (吞吐、响应时间、 完成时间)、存储容量、计算能力的特性
常见指标是加速比(Speedup):一个系统进行扩展后相对扩展前的性能提升:
如果目标是为了提高吞吐量,则可以用扩展后和扩展前的吞吐量之比进行衡量。
如果目标是为了缩短完成时间,则可以用扩展前和扩展后的完成时间之比进行衡量。
如果目标是为了缩短响应时间,则可以用扩展前和扩展后的响应时间之比进行衡量。
