1 分布式互斥
对于同一共享资源,要求同一时刻只能有一个程序能够访问,防止出错
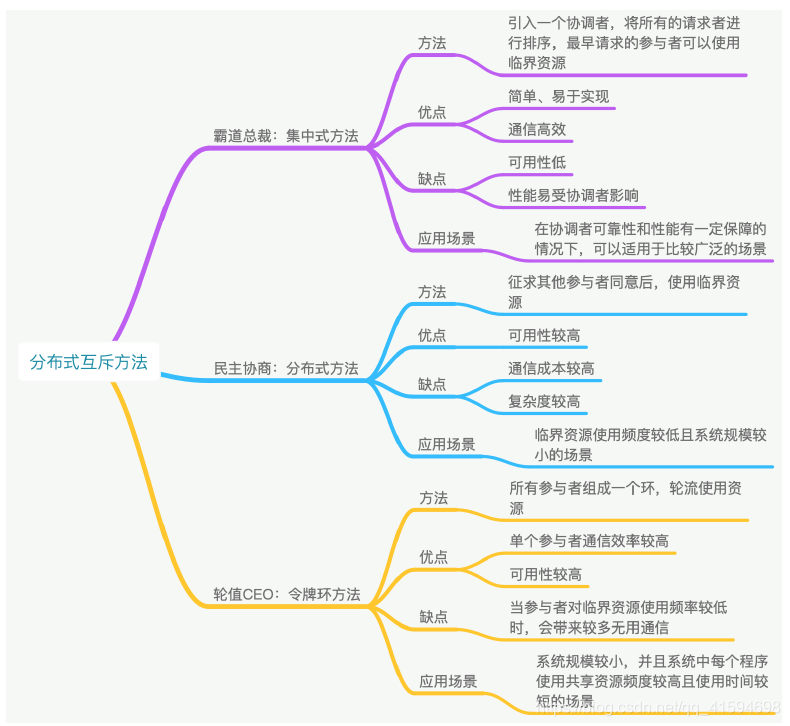
1.1 集中式算法
引入一个协调者程序,得到一个分布式互斥算法:
每个程序在需要访问临界资源时,先给协调者发送一个请求;
如果当前没有程序使用这个资源,协调者直接授权请求程序访问,否则,按照FIFO规则进行排队等待;
如果有程序使用完资源,则通知协调者,协调者从队列里取出排在最前面的请求,并给它发送授权消息,拿
到授权消息的程序,可以直接去访问临界资源
一个程序完成一次临界资源访问,需要如下几个流程和消息交互(三次):
向协调者发送请求授权信息,1 次消息交互;
协调者向程序发放授权信息,1 次消息交互;
程序使用完临界资源后,向协调者发送释放授权,1 次消息交互。
优点:直观、简单、信息交互量少、易于实现、程序只需和协调者通信,程序之间无需通信
缺点:协调者可能会成为系统的性能瓶颈、单点故障(使用主备)
场景:比较广泛
1.2 分布式算法(组播和逻辑时钟的算法)
当一个程序要访问临界资源时,先向系统中的其他程序发送一条请求消息,在接收到所有程序返回的同意消息后,才可以访问临界资源;
其中,请求消息需要包含所请求的资源、请求者的 ID,以及发起请求的时间
如果当前程序正在使用资源,其他程序申请了这个资源,那么当前程序会将这个申请资源的程序放在队列里,等到释放此资源,就向队列里的第一个需要此资源的程序发送”同意使用资源“的消息,并从队列移除此程序(机制:先到先得、投票需全票通过)
队列需要记录请求资源的时间、对应的程序、申请的资源
一个程序完成一次临界资源的访问,需要进行如下几个流程和信息交互(2*(n-1)):
向其他 n-1 个程序发送访问临界资源的请求,总共需要 n-1 次消息交互;
需要接收到其他 n-1 个程序回复的同意消息,方可访问资源,总共需要 n-1 次消息交
互。
优点:每个程序按时间顺序公平地访问资源、简单粗暴、易于实现
缺点:可用性比集中式算法低,原因如下:
1 当系统内需要访问临界资源的程序增多时,容易产生“信令风暴”,也就是程序收到的请求完全超过了自己的处理能力,而导致自己正常的业务无法开展;
2 一旦某一程序发生故障,无法发送同意消息,那么其他程序均处在等待回复的状态中,使得整个系统处于停滞状态,导致整个系统不可用;
改进:如果检测到一个程序故障,则直接忽略这个程序,无需再等待它的同意消息
场景:适合节点数目少且变动不频繁的系统,且由于每个程序均需通信交互,因此适合P2P结构的系统。(Hadoop)
1.3 令牌环算法(一致性哈希)
所有程序构成一个环结构,令牌按照顺时针(逆时针)方向在程序之间传递,收到令牌的程序有权访问临界资源,访问完成后将令牌传送到下一个程序;
若该程序不需要访问临界资源,则直接把令牌传送给下一个程序。
优点:
不需要像分布式算法那样挨个征求其他程序的意见了,所以相对而言,在令牌环算法里单个程序具有更高的通信效率;
同时,在一个周期内,每个程序都能访问到临界资源,因此令牌环算法的公平性也很好,甚至更好;
缺点:
不管环中的程序是否想要访问资源,都需要接收并传递令牌,所以也会带来一些无效通信(可以进行加权处理);
单点故障问题,可以这么改进:若某一个程序出现故障,则直接将令牌传递给故障程序的下一个程序,这样稳定性也挺好的
场景:非常适合通信模式为令牌环方式的分布式系统(移动自组织网络系
统:无人机通信),即系统规模较小,并且系统中每个程序使用临界资源的频率高且使用时间比较短
1.4 两层结构的分布式令牌环算法
如上三个算法都不适用于规模过大、节点数量过多的系统,可以使用两层结构的分布式令牌环算法,把整个广域网系统中的节点组织成两层结构,可以用于节点数量较多的系统,或者是广域网系统。
在该算法中,局域网是较低的层次,广域网是较高的层次;
每个局域网中包含若干个局部进程和一个协调进程;
局部进程在逻辑上组成一个环形结构,在每个环形结构上有一个局部令牌 T 在局部进程间传递;
局域网与局域网之间通过各自的协调进程进行通信,这些协调进程同样组成一个环结构,这个环就是广域网中的
全局环;
在这个全局环上,有一个全局令牌在多个协调进程间传递。
1.5 总结对比
2 分布式选举
集群里选出一个主节点,由它来协调和管理其他节点,以保证集群有序运行和节点间数据的一致性。
2.1 Bully算法
选举原则是“长者为大“,即在所有活着的节点中,选取ID最大的节点作为主节点。
算法说明:
节点的角色有两种:普通节点和主节点;
初始化时,所有节点都是平等的,都是普通节点,并且都有成为主的权利;
选主成功后,有且仅有一个节点成为主节点,其他所有节点都是普通节点;
当且仅当主节点故障或与其他节点失去联系后,才会重新选主
在选举过程中,需要用到以下3种消息:
Election:用于发起选举
Alive:对 Election 消息的应答
Victory:竞选成功的主节点向其他节点发送的宣誓主权的消息
选举前提:集群中每个节点均知道其他节点的 ID
选举流程:
每个节点判断自己的 ID 是否为当前活着的节点中 ID 最大的:
如果是,则直接向其他节点发送 Victory 消息,宣誓主权;
如果不是,则向比自己 ID 大的所有节点发送Election 消息,并等待其他节点的回复;若在给定的时间范围内:
本节点没有接收到来自比自己ID 大的节点的 Alive 消息,则认为自己成为主节点(可能ID更大的节点出问题了,或者网络不好),并向其他节点发送 Victory 消息,宣誓自己成为主节点;
本节点接收到来自比自己ID 大的节点的 Alive 消息,说明有比我ID大的且没故障、网络没问题的,则等待其他节点发送 Victory 消息;若本节点收到比自己 ID 小的节点发送的 Election 消息,则回复一个 Alive 消息,告知其他节点,我比你大,重新选举。
优点:选举速度快、算法复杂度低、简单易实现
缺点:
需要每个节点有全局的节点信息,因此额外信息存储较多;
任意一个比当前主节点 ID 大的新节点或节点故障后恢复加入集群的时候,都可能会触发重新选举,成为新的主节点,如果该节点频繁退出、加入集群,就会导致频繁切主。
2.2 Raft算法
核心思想是“少数服从多数”,获得投票最多的节点成为主。
算法说明:
集群节点的角色有 3 种:
Leader:主节点,同一时刻只有一个 Leader,负责协调和管理其他节点;
Candidate:候选者,每一个节点都可以成为 Candidate,节点在该角色下才可以被选为新的 Leader;
Follower:Leader 的跟随者,不可以发起选举
选举流程:
初始化时,所有节点均为 Follower 状态。
开始选主时,所有节点的状态由 Follower 转化为 Candidate,并向其他节点发送选举请求。
其他节点根据接收到的选举请求的先后顺序,回复是否同意成为主;
在每一轮选举中,一个节点只能投出一张票若发起选举请求的节点获得超过一半的投票,则成为主节点,其状态转化为 Leader,其他节点的状态则由 Candidate 降为 Follower;
Leader节点与Follower节点之间会定期发送心跳包,以检测主节点是否活着,如果主节点故障,会立马发起选举,重新选出一个主节点当Leader节点的任期到了,即发现其他服务器开始下一轮选主周期时,Leader 节点的状态由 Leader 降级为 Follower,进入新一轮选主
优点:选举速度快、算法复杂度低、易于实现
缺点:要求
系统内每个节点都可以相互通信,且需要获得过半的投票数才能选主成功,因此通信量大;稳定性高于Bully算法,是因为当有新节点加入或节点故障恢复后,会触发选主,但不一定会真正切主,除非新节点或故障后恢复的节点获得投票数过半,才会导致切主。
场景:etcds、Redis
2.3 ZAB算法
相比于 Raft 算法的投票机制,ZAB 算法增加了通过节点 ID 和数据 ID 作为参考进行选主,节点 ID 和数据 ID 越大,表示数据越新,优先成为主
也就是说相比于Raft算法,ZAB 算法尽可能保证数据的最新性。所以,ZAB 算法可以说是对 Raft 算法的改进,具有了优先级
算法说明:
集群节点的角色有 3 种:
Leader:主节点;
Follower:跟随者节点;
Observer:观察者,无投票权选举过程中,集群中的节点拥有 4 个状态:
Looking:选举状态。当节点处于该状态时,它会认为当前集群中没有 Leader,因此自己进入选举状态;
Leading 状态:领导者状态。表示已经选出主,且当前节点为 Leader;
Following 状态:跟随者状态。集群中已经选出主后,其他非主节点状态更新为Following,表示对 Leader 的追随;
Observing 状态:观察者状态。表示当前节点为 Observer,没有投票权和选举权
选举流程:推荐阅读https://mp.weixin.qq.com/s/6Lai6Gw9h2YAinS4QqNOLA
优点:
性能高、对系统无特殊要求;
稳定性比较好,当有新节点加入或节点故障恢复后,会触发选主,但不一定会真正切主,除非新节点或故障后恢复的节点数据 ID 和节点ID 最大,且获得投票数过半,才会导致切主。
缺点:
采用广播方式发送信息,若节点中有 n个节点,每个节点同时广播,则集群中信息量为 n*(n-1) 个消息,容易出现广播风暴;
除了投票,还增加了对比节点 ID 和数据 ID,这就意味着还需要知道所有节点的 ID 和数据ID,所以选举时间相对较长
场景:ZooKeeper
2.4 选举算法的技巧
“多数派”选主算法(Raft、ZAB)通常采用奇数节点,而不是偶数节点,因为在偶数节点的情况下,无法选出主,必须重新投票选举。但即使重新投票选举,两个节点拥有相同投票数的概率也会很大
3 分布式共识
在多个节点均可独自操作或记录的情况下,使得所有节点针对某个状态达成一致的过程;
通过共识机制,可以使得分布式系统中的多个节点的数据达成一致;
分布式选举过程就是一个分布式共识问题
分布式选举大多是基于多数投票策略实现的,如果用于分布式在线记账一致性问题中,那么记账权通常会完全掌握到主节点的手里,这使得主节点非常容易造假,且存在性能瓶颈;(区块链)
分布式在线记账:指在没有集中的发行方,也就是没有银行参与的情况下,任意一台接入互联网的电脑都能参与买卖,所有看到该交易的服务器都可以记录这笔交易,并且记录信息最终都是一致的,以保证交易的准确性;
如何保证交易的一致性,就是该场景下的分布式共识问题
在分布式在线记账问题中,针对同一笔交易,有且仅有一个节点或服务器可以获得记账权,然后其他
节点或服务器同意该节点或服务器的记账结果,达成一致;
即分布式共识包括两个关键点:获得记账权和所有节点或服务器达成一致。
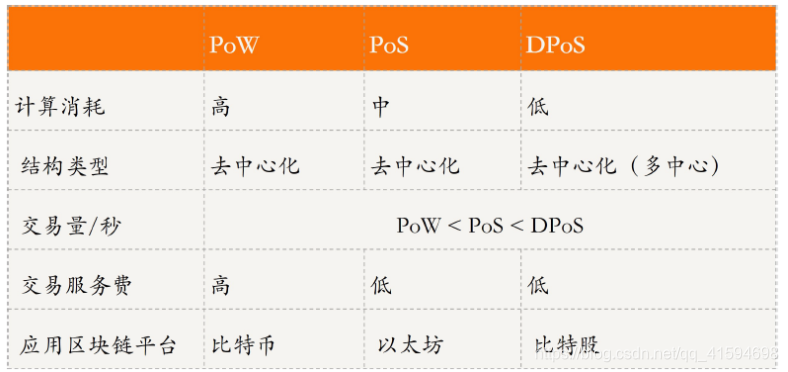
3.1 PoW(Proof-of-Work,工作量证明;区块链1.0阶段)
以每个节点或服务器的计算能力(算力)来竞争记账权的机制,是一种使用工作量证明机制的共识算法;
也就是说,谁的计算力、工作能力强,谁获得记账权的可能性就越大
算法说明:
算力的体现:每个节点都去解一道题,谁能先解决谁的能力就强。
假设每个节点会划分多个区块用于记录用户交易的信息,那么此算法获取记账权的原理是:
利用区块的 index、前一个区块的哈希值、交易的时间戳、区块数据和 nonce 值,通过SHA256哈希算法计算出一个哈希值,并判断前 k 个值是否都为0:(nonce 值是用来找到一个满足哈希值的数字;k 为哈希值前导零的个数,标记了计算的难度,0 越多计算难度越大。)
如果不是,则递增 nonce 值,重新按照上述方法计算;
如果是,则本次计算的哈希值为要解决的题目的正确答案;
谁最先计算出正确答案,谁就获得这个区块的记账权达成共识的过程,就是获得记账权的节点将该区块信息广播给其他节点,其他节点判断该节点找到的区块中的所有交易都是有效且之前未存在过的,则认为该区块有效,并接受该区块,达成一致。
优点:允许全网 50% 的节点出错,因此,如果要破坏系统,则需要投入极大成本(有全球 51% 的算力,则可尝试攻击比特币)
缺点:
每次达成共识需要全网共同参与运算,增加了每个节点的计算量;
如果题目过难,会导致计算时间长、资源消耗多;如果题目过于简单,会导致大量节点同时获得记账权,冲突多;
这些问题,都会增加达成共识的时间(也就是说共识达成的周期长、效率低,资源消耗大)
3.2 PoS(Proof-of-Stake,权益证明;2.0)
为了解决 PoW 算法的缺点,引入了 PoS 算法;
核心原理:由系统权益代替算力来决定区块记账权,拥有的权益越大获得记账权的概率就越大。
算法说明:
权益:每个节点占有货币的数量和时间,而货币就是节点所获得的奖励;
PoW 算法充分利用了分布式在线记账中的奖励,支持“利滚利”。公式:利息 = (币数 * 持有的天数 * 利率 / 365)
例子:
比如持有 100 个币,总共持有了 50 天,那么,币龄就为 5000;
这时如果发现了一个 PoS 区块,币龄就会被减少 365;
每被减少 365 币龄,就可以从区块中获得 0.05 个币的利息 (可理解为年利率 5%);
此时,利息 = 100 * 50 *5% /365 = 0.68 个币。不同节点通过公式计算自己的利息,谁最大,谁将自己的区块广播给其他节点,当然必须保证该区块的有效性
优点:与PoW相比
PoS不需要消耗大量的就能够保证区块链网络的安全性;
不需要在每个区块中创建新的货币来激励记账者参与当前网络的运行,在一定程度上缩短了达成共识所需要的时间。
缺点:与PoW相比
持币越多或持币越久,币龄就会越高,持币人就越容易挖到区块并得到激励,而持币少的人基本没有机会,这样整个系统的安全性实际上会被持币数量较大的一部分人掌握,容易出现垄断现象。
3.3 DPoS(Delegated Proof of Stake,委托权益证明;3.0)
为了解决 PoS 算法的缺点,提出了此算法:类似股份制公司的董事会制度,普通股民虽然拥有股权,但进不了董事会,他们可以投票选举代表(受托人)代他们做决策;
DPoS 是由被社区选举的可信帐户来拥有记账权
算法说明:
为了成为正式受托人,用户要去社区拉票,获得足够多的信任,用户根据自己持有的货币数量占总量的百分比来投票
选出k(比如 101) 个受托节点,它们的权利是完全相等的;
受托节点之间争取记账权是根据算力进行竞争的;
如果受托节点提供的算力不稳定,计算机宕机或者利用手中的权力作恶,随时可以被握着货币的普通节点投票踢出整个系统,而后备的受托节点可以随时顶上去
优点:与PoS相比
由投票选举出的若干信誉度更高的受托人来记账,解决了所有节点均参与竞争导致消息量大、达成一致的周期长的问题,也就是说,DPoS 能耗更低,具有更快的交易速度;
每隔一定周期会调整受托人,避免受托人造假和独权
缺点:与PoS相比
由于大多数持币人通过受托人参与投票,投票的积极性并不高;
一旦出现故障节点,DPoS 无法及时做出应对,导致安全隐患
3.4 总结对比
- 一致性与共识的区别
一致性:分布式系统中的多个节点之间,给定一系列的操作,在约定协议的保障下,对外界呈现的数据(状态)是一致的
共识:分布式系统中多个节点之间,彼此对某个状态达成一致结果的过程
也就是说一致性强调的是结果,共识强调的是达成一致的过程,共识算法是保障系统满足不同程度一致性的核心技术
4 分布式事务
不同业务会运行在不同的机器上,比如订单机器和库存机器,针对同一笔订单,当且仅当订单操作和减库存操作一致时,才能保证交易的正确性;
也就是说一笔订单只有这两个操作都完成,才能算做处理成功,否则处理失败,这个问题就是分布式事务要解决的问题
分布式事务基本能够满足 ACID,但随着分布式系统规模不断扩大,复杂度急剧上升,达成强一致性所需时间周期较长,限定了复杂业务的处理;
为了适应复杂业务,出现了BASE理论,该理论的一个关键点就是采用最终一致性代替强一致性,算是ACID的弱化
4.1 基于 XA 协议的二阶段提交协议方法(强一致性)
XA协议可以分为两部分:事务管理器和本地资源管理器
算法说明:
原理类似分布式互斥的集中式算法:
事务管理器作为协调者,负责各个本地资源的提交和回滚;
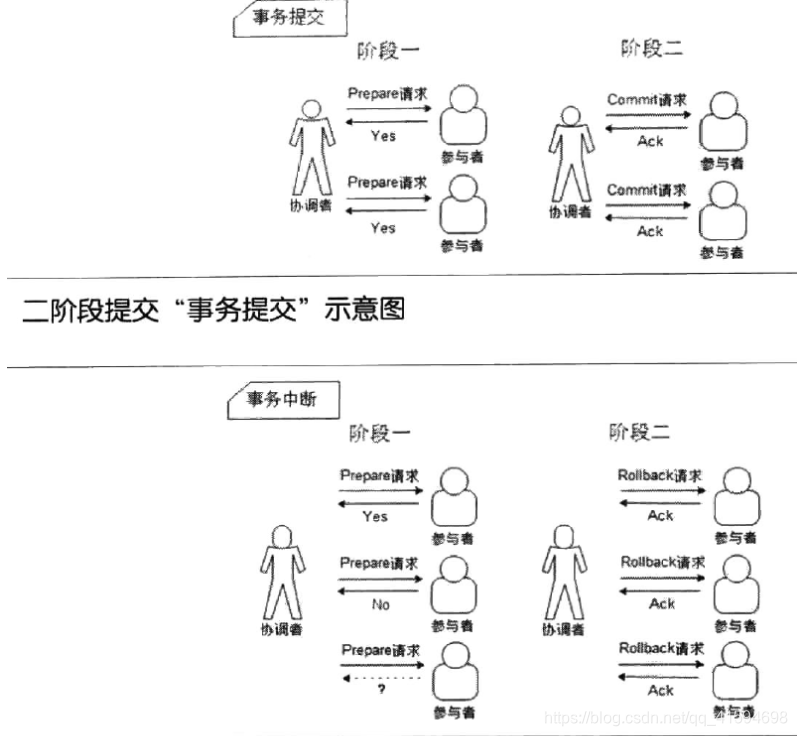
资源管理器就是分布式事务的参与者,通常由数据库实现(实现XA接口)二阶段提交协议(The two-phase commitprotocol,2PC)用于保证分布式系统中事务提交时的数据一致性,是 XA 在全局事务中用于协调多个资源的机制。
二阶段提交协议算法说明:投票(voting)和提交(commit)
第一阶段:投票
协调者(Coordinator,即事务管理器)会向事务的参与者(Cohort,即本地资源管理器)发起执行操作的 CanCommit 请求,并等待参与者的响应;
参与者接收到请求后,会执行请求中的事务操作,记录日志信息但不提交;
待参与者执行成功,则向协调者发送“Yes”消息,表示同意操作;若不成功,则发送“No”消息,表示终止操作。第二阶段:提交
当所有的参与者都返回了响应后(Yes 或 No 消息)后,系统进入了提交阶段;
在提交阶段,协调者会根据所有参与者返回的信息向参与者发送 DoCommit 或 DoAbort 指令:
若协调者收到的都是“Yes”消息,则向参与者发送“DoCommit”消息,参与者会完成剩余的操作并释放资源,然后向协调者返回“HaveCommitted”消息;
如果协调者收到的消息中包含“No”消息,则向所有参与者发送“DoAbort”消息,此时发送“Yes”的参与者则会根据之前执行操作时的回滚日志对操作进行回滚,然后所有参与者会向协调者发送“HaveCommitted”消息;
协调者接收到“HaveCommitted”消息,就意味着整个事务结束了。
流程图:《从Paxos到ZooKeeper》
优点:简单
缺点:
1 同步阻塞:二阶段提交算法在执行过程中,所有参与节点都是事务阻塞型的;
也就是说,当本地资源管理器占有临界资源时,其他资源管理器如果要访问同一临界资源,会处于阻塞状态。
2 单点故障:事务管理器会有此问题
3 数据不一致:在提交阶段,当协调者向参与者发送 DoCommit 请求之后,如果发生了局部网络异常,或者在发送提交请求的过程中协调者发生了故障,就会导致只有一部分参与者接收到了提交请求并执行提交操作,但其他未接到提交请求的那部分参与者则无法执行事务提交,于是整个分布式系统便出现了数据不一致的问题。
4.2 三阶段提交协议方法3PC(强一致性)
为了解决2PC的单点故障、部分数据不一致问题,引入了超时机制和准备阶段,成为3PC
算法说明:
协调者和参与者都引入超时机制;
如果协调者或参与者在规定的时间内没有接收到来自其他节点的响应,就会根据当前的状态选择提交或者终止整个事务。在第一阶段和第二阶段中间引入了一个准备阶段,也就是在提交阶段之前,加入了一个预提交阶段;
在预提交阶段排除一些不一致的情况,保证在最后提交之前各参与节点的状态是一致的;
实现:把 2PC 的提交阶段一分为二,全部有CanCommit、PreCommit、DoCommit 三个阶段。第一阶段:CanCommit,与2PC的第一阶段类似
协调者向参与者发送请求操作(CanCommit请求),询问参与者是否可以执行事务提交操作,然后等待参与者的响应;
参与者收到CanCommit 请求之后,回复 Yes,表示可以顺利执行事务,否则回复 No。第二阶段:PreCommit
协调者根据参与者的回复情况,来决定是否可以进行 PreCommit 操作:
如果所有参与者回复的都是“Yes”,那么协调者就会执行事务的预执行:
1 发送预提交请求:协调者向参与者发送 PreCommit 请求,进入预提交阶段。
2 事务预提交:参与者接收到 PreCommit 请求后执行事务操作,并将 Undo 和 Redo信息记录到事务日志中。
3 响应反馈:如果参与者成功执行了事务操作,则返回 ACK 响应,同时开始等待最终指令。
如果任何一个参与者向协调者发送了“No”消息,或者等待超时之后,协调者都没有收到参与者的响应,就执行中断事务的操作:
1 发送中断请求:协调者向所有参与者发送“Abort”消息。
2 终断事务:参与者收到“Abort”消息之后,或超时后仍未收到协调者的消息,执行事务的终断操作。第三阶段:DoCommit
根据 PreCommit 阶段协调者发送的消息,进入执行提交阶段或事务中断阶段:
执行提交阶段:
1 发送提交请求:协调者接收到所有参与者发送的 Ack 响应,从预提交状态进入到提交状态,并向所有参与者发送 DoCommit 消息。
2 事务提交:参与者接收到 DoCommit 消息之后,正式提交事务。完成事务提交之后,释放所有锁住的资源。
3 响应反馈:参与者提交完事务之后,向协调者发送 Ack 响应。
4 完成事务:协调者接收到所有参与者的 Ack 响应之后,完成事务。
事务中断阶段:
1 发送中断请求:协调者向所有参与者发送 Abort 请求。
2 事务回滚:参与者接收到 Abort 消息之后,利用其在 PreCommit 阶段记录的 Undo信息执行事务的回滚操作,并释放所有锁住的资源。
3 反馈结果:参与者完成事务回滚之后,向协调者发送 Ack 响应。
4 终断事务:协调者接收到参与者反馈的 Ack 消息之后,执行事务的终断,并结束事务。
流程图:《从Paxos到ZooKeeper》
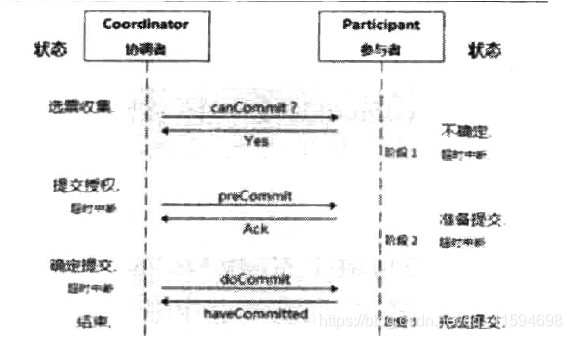
优点:无单点故障问题、无同步阻塞问题、强一致性、同步执行
缺点:
参与者接收到doCommit消息后,如果网络出现分区,此时协调者所在的节点和参与者无法进行通信,参与者依然会进行事务的提交,会出现数据的不一致性(在 DoCommit 阶段,当参与者向协调者发送 Ack 消息后,如果长时间没有得到协调者的响应,在默认情况下,参与者会自动将超时的事务进行提交,不会像两阶段提交那样被阻塞住。)
性能较低
系统吞吐量不高
4.3 基于消息的最终一致性方法(最终一致性)
2PC和3PC有两个共同的缺点:
1 需要锁定资源,降低系统性能
2 没有解决数据不一致的问题
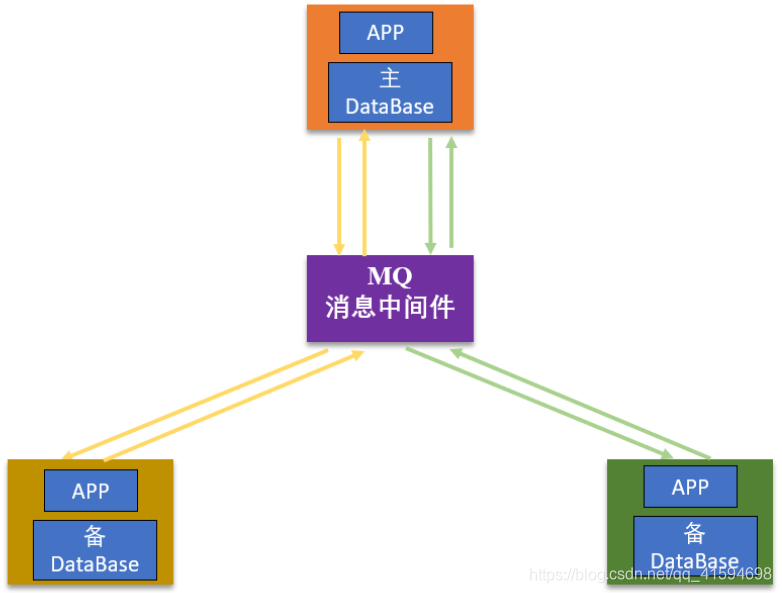
基于分布式消息的最终一致性方案:将需要分布式处理的事务通过消息或者日志的方式异步执行,消息或日志可以存到本地文件、数据库或消息队列中,再通过业务规则进行失败重试。
实现:引入MQ,用于在多个应用之间进行消息传递:
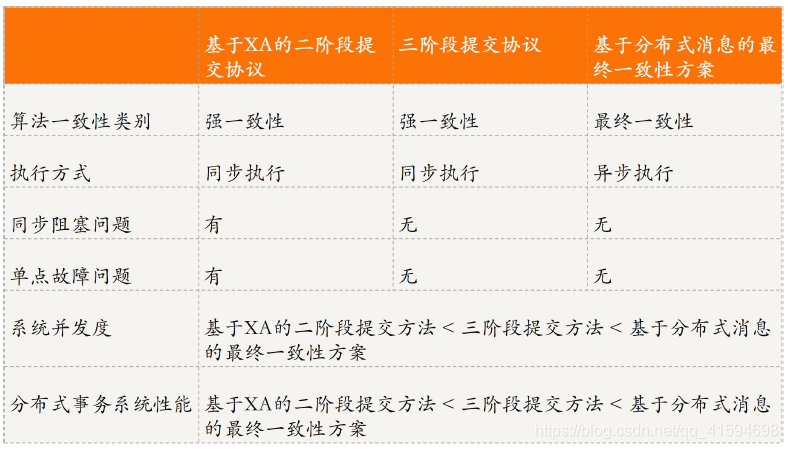
4.4 总结对比
- 刚性事务与柔性事务
刚性事务:遵循 ACID 原则,具有强一致性,比如数据库事务。(ACID)
柔性事务:根据不同的业务场景使用不同的方法实现最终一致性,也就是说我们可以根据业务的特性做部分取舍,容忍一定时间内的数据不一致。(BASE)
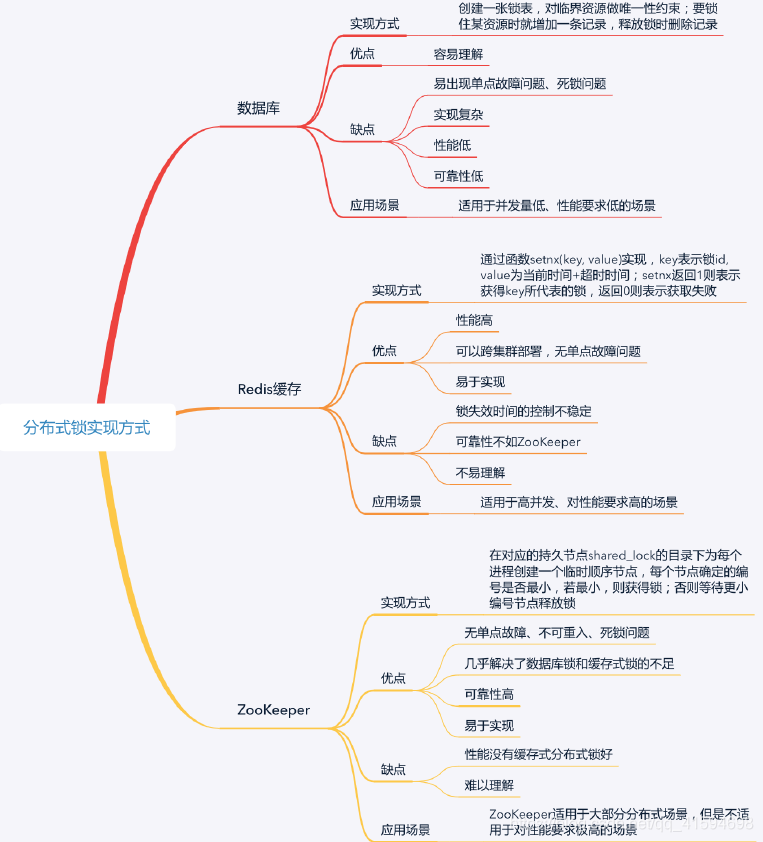
5 分布式锁
分布式互斥算法主要解决了“协调多个进程获取权限和根据权限有序访问共享资源”的问题,分布式锁则解决”这个权限是如何设置或产生的,以及设置或产生这个权限的工作原理是什么“的问题
具体实现的方式网上有很多文章,这里就不多说啦,放张图: