服务器规划
192.168.30.24 k8s-master1
192.168.30.25 k8s-master2
192.168.30.26 k8s-node1
192.168.30.30 k8s-node2
192.168.30.31 k8s-node3
192.168.30.32 k8s-slb1
192.168.30.33 k8s-slb2生产环境高可用集群
规格:配置3/5/7个master, 3/5/7etcd集群,3/5/7个nginx对api做负载均衡,1个slb充当HA来访问k8s的API
参考阿里云配置:
节点规模 Master规格
1-5个节点 4C8G(不建议2C4G)
6-20个节点 4C16G
21-100个节点 8C32G
100-200个节点 16C64G具体部署步骤
一、系统初始化
二、颁发ETCD证书
三、部署ETCD集群
四、颁发K8S相关证书
五、部署Master组件
六、部署Node组件
七、部署CNI插件(Calico插件)
八、部署Coredns插件
九、扩容Node节点
十、缩容Node节点
十一、部署高可用HA一、系统初始化
关闭防火墙:
# systemctl stop firewalld
# systemctl disable firewalld
关闭selinux:
# setenforce 0 # 临时
# sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
关闭swap:
# swapoff -a # 临时
# vim /etc/fstab # 永久
同步系统时间:
# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
添加hosts:
# vim /etc/hosts
192.168.30.24 k8s-master1
192.168.30.25 k8s-master2
192.168.30.26 k8s-node1
192.168.30.30 k8s-node2
修改主机名:
hostnamectl set-hostname k8s-master1二、Etcd证书颁发
在k8s中有两套证书,一套是k8s的一套是etcd的
证书的颁发有两种,一种证书可以是自签的,另外就是通过权威机构进行颁发的
自签:
权威机构: 像赛门铁克 给域名颁发差不多3000左右 另外就是泛域名证书 * .zhaocheng.com,这种的一般价格在几万到几十万左右
不管怎么颁发,都有一个根证书,根据这个根证书去效验,只要是这个证书颁发的就是受信任的,如果不是这个颁发的就是不可受信任的
对于我们网站去用的,都会使用买的,通过机构进行颁发,证书会颁发两个,一个是crt,一个是key,crt是数字证书,一个是私钥,而自签证书也会颁发这两个,也就是通过CA这个机构去进行颁发
所有部署安装包以及yaml文件都放在云盘
链接:https://pan.baidu.com/s/1dbgUyudy_6yhSI6jlcaEZQ
提取码评论区要
2.1 生成etcd证书
[root@k8s-master1 ~]# ls
TLS.tar.gz
[root@k8s-master1 ~]# tar xf TLS.tar.gz
[root@k8s-master1 ~]# cd TLS/这里有两个目录,一个是etcd 一个是k8s,也就是为etcd和k8s都去颁发这么一个证书
[root@k8s-master1 TLS]# ls
cfssl cfssl-certinfo cfssljson cfssl.sh etcd k8s颁发证书的时候会用到cfssl,这个工具,或者还有openssl,这个主要用来自签证书的
执行cfssl.sh
这里把下载的方式直接写入这个脚本中了
[root@k8s-master1 TLS]# more cfssl.sh
#curl -L https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -o /usr/local/bin/cfssl
#curl -L https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -o /usr/local/bin/cfssljson
#curl -L https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -o /usr/local/bin/cfssl-certinfo
cp -rf cfssl cfssl-certinfo cfssljson /usr/local/bin
chmod +x /usr/local/bin/cfssl*
[root@k8s-master1 TLS]# bash cfssl.sh 放到这个/usr/local/bin 下,现在就可以使这个工具来签发证书
[root@k8s-master1 TLS]# ls /usr/local/bin/
cfssl cfssl-certinfo cfssljson自建CA,通过这个CA机构来颁发证书
[root@k8s-master1 TLS]# cd etcd/
[root@k8s-master1 etcd]# ls
ca-config.json ca-csr.json generate_etcd_cert.sh server-csr.json
[root@k8s-master1 etcd]# more generate_etcd_cert.sh
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
[root@k8s-master1 etcd]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
[root@k8s-master1 etcd]# ls
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem generate_etcd_cert.sh server-csr.json创建完之后会看到关于ca.pem,以后就可以拿这些去颁发证书
颁发的话需要让颁发者写一个文件,就是要哪个域名或者哪个服务来颁发这个证书
现在我们要为etcd去颁发一个证书,也就是server-csr.json这个文件,这个服务器生产中如果机器富裕的话可以使用单独的机器去部署
[root@k8s-master1 etcd]# more server-csr.json
{
"CN": "etcd",
"hosts": [
"192.168.30.24",
"192.168.30.26",
"192.168.30.30"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}现在我们拿这个文件去像CA机构去请求证书
这里会生成server开头的pem和key[root@k8s-master1 etcd]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
我们会用到.pem的证书,这就是为etcd颁发的
[root@k8s-master1 etcd]# ls .pem
ca-key.pem ca.pem server-key.pem server.pem
三、Etcd集群的部署
官方地址:https://etcd.io/
etcd是coreos开源的key-value系统,主要用于服务注册和服务发现和共享配置,让其他的去读取随着ETCD和K8S项目的发展,现在etcd也作为k8s的存储了,etcd是由多个节点相互通信来进行提供对外服务的,每个节点都有存储的数据,而节点之间又是通过RAFT的协议来保证每个节点的一致性,而ETCD官方推荐3个或者5个节点来组成一个集群,奇数来组件一个集群,3个节点冗余1个节点出现故障,5个节点冗余2个节点故障,7个节点冗余3个节点故障,一般3个节点就够,如果读写量很大的话那么就部署5个节点,那么他们节点之间会有一个主节点leader,它主要处理的是写的操作,比如etcd1来选举的为主,其他的为从,其他的为写,都会往这个主里面去发送,然后写完之后会同步到从里面,当主挂了之后会重新选举,如果打不了奇数的话,它是无法进行选举的,也就是为什么它使用奇数的方式去部署集群,当一个主节点挂了,会选举一个节点出来提供写的服务。
3.1、部署etcd集群
这里有两个文件,一个是etcd.service,主要用来通过systemctl来管理etcd的服务的,主要用来启动etcd的,因为使用的是Centos7的系统,一个是etcd的工作目录
[root@k8s-master1 ~]# ls
etcd.tar.gz TLS TLS.tar.gz
[root@k8s-master1 ~]# tar xf etcd.tar.gz
[root@k8s-master1 ~]# ls
etcd etcd.service etcd.tar.gz TLS TLS.tar.gz这里已经是下载好了,在官方可以下载其他的版本,如果想换其他的版本,可以直接将两个进行替换掉
[root@k8s-master1 ~]# cd etcd/
[root@k8s-master1 etcd]# ls
bin cfg ssl
[root@k8s-master1 etcd]# cd bin/
[root@k8s-master1 bin]# ls
etcd etcdctl另外需要将之前的证书删除掉,这是之前的,需要替换成刚才我们生成的etcd的证书文件
[root@k8s-master1 ssl]# ls
ca.pem server-key.pem server.pem
[root@k8s-master1 ssl]# rm -rf *还有一个就是etcd的etcd.conf文件
etcd有两个重要的端口
ETCD_LISTEN_PEER_URLS="https://192.168.31.61:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.31.61:2379"第一个是用于etcd集群之间内部通信的地址和端口,也就是节点之间互相的一个通信,走的是https进行通信的,这一块也是需要我们去配置上证书的
第二个是客户端监听的地址,就是让别的程序通过这个地址和端口来连接数据的操作,当然这一块也需要这么一个证书,客户端连接的时候需要证书来认证
现在去修改我们的etcd.conf监听的地址
[root@k8s-master1 etcd]# more cfg/etcd.conf
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.30.24:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.30.24:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.30.24:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.30.24:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.30.24:2380,etcd-2=https://192.168.30.26:2380,etcd-3=https://192.168.30.30:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"现在将证书拿到我们的目录节点下
[root@k8s-master1 etcd]# cp /root/TLS/etcd/{ca,server,server-key}.pem ssl/
[root@k8s-master1 etcd]# ls
bin cfg ssl
[root@k8s-master1 etcd]# cd ssl/
[root@k8s-master1 ssl]# ls
ca.pem server-key.pem server.pem将我们刚才配置修改好的etcd目录及启动system文件分发到我们其他的etcd节点服务器中
[root@k8s-master1 ~]# scp -r etcd 192.168.30.24:/opt
[root@k8s-master1 ~]# scp -r etcd 192.168.30.26:/opt
[root@k8s-master1 ~]# scp -r etcd 192.168.30.30:/opt
再将启动的system启动文件也分发到我们的指定目录中
[root@k8s-master1 ~]# scp -r etcd.service 192.168.30.24:/usr/lib/systemd/system
[root@k8s-master1 ~]# scp -r etcd.service 192.168.30.26:/usr/lib/systemd/system
[root@k8s-master1 ~]# scp -r etcd.service 192.168.30.30:/usr/lib/systemd/system修改我们的其他的节点的服务端地址
修改的时候要修改集群编号,以及监听本地的地址
[root@k8s-node1 ~]# more /opt/etcd/cfg/etcd.conf
#[Member]
ETCD_NAME="etcd-2"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.30.26:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.30.26:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.30.26:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.30.26:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.30.24:2380,etcd-2=https://192.168.30.26:2380,etcd-3=https://192.168.30.30:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"修改集群编号和监听本地的地址
[root@k8s-node2 ~]# more /opt/etcd/cfg/etcd.conf
#[Member]
ETCD_NAME="etcd-3"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.30.30:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.30.30:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.30.30:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.30.30:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.30.24:2380,etcd-2=https://192.168.30.26:2380,etcd-3=https://192.168.30.30:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new
"每个节点都去启动etcd集群
[root@k8s-master1 ~]# systemctl daemon-reload
[root@k8s-master1 ~]# systemctl start etcd
[root@k8s-node1 ~]# systemctl daemon-reload
[root@k8s-node1 ~]# systemctl start etcd
[root@k8s-node2 ~]# systemctl daemon-reload
[root@k8s-node2 ~]# systemctl start etcd每个节点都设置开机启动
[root@k8s-master1 ~]# systemctl enable etcd
Created symlink from /etc/systemd/system/multi-user.target.wants/etcd.service to /usr/lib/systemd/system/etcd.service.查看etcd的日志,通过journalctl,这里可以直接看到etcd的版本以及集群的每个监听的地址
[root@k8s-master1 ~]# journalctl -u etcd
Mar 29 20:58:20 k8s-master1 etcd[52701]: etcd Version: 3.3.13
Mar 29 20:58:20 k8s-master1 etcd[52701]: Git SHA: 98d3084
Mar 29 20:58:20 k8s-master1 etcd[52701]: Go Version: go1.10.8
Mar 29 20:58:20 k8s-master1 etcd[52701]: Go OS/Arch: linux/amd64
Mar 29 20:58:20 k8s-master1 etcd[52701]: added member 7d0b0924d5dc6c42 [https://192.168.30.24:2380] to cluster 5463d984b27d1295
Mar 29 20:58:20 k8s-master1 etcd[52701]: added member 976cfd3f7cca5aa2 [https://192.168.30.30:2380] to cluster 5463d984b27d1295
Mar 29 20:58:20 k8s-master1 etcd[52701]: added member f2f52c31a7a3af4c [https://192.168.30.26:2380] to cluster 5463d984b27d1295查看etcd集群健康状态
[root@k8s-master1 ~]# /opt/etcd/bin/etcdctl --ca-file=/opt/etcd/ssl/ca.pem --cert-file=/opt/etcd/ssl/server.pem --key-file=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.30.24:2379,https://192.168.30.26:2379,https://192.168.30.30:2379" cluster-health
member 7d0b0924d5dc6c42 is healthy: got healthy result from https://192.168.30.24:2379
member 976cfd3f7cca5aa2 is healthy: got healthy result from https://192.168.30.30:2379
member f2f52c31a7a3af4c is healthy: got healthy result from https://192.168.30.26:2379
cluster is healthy四、颁发K8S相关证书
4.1 、首先先去部署Apiserver,因为它是集群的访问入口,另外就是K8s也是使用证书进行通信的,现在我们需要为K8s也进行颁发证书
这里也有一套CA,这个CA是不能和ETCD用的,他们都是独立的一套,这里还有两个请求颁发的文件,一个是kube-proxy-csr,json,这个是工作节点Node节点所准备的证书,也是由apiserver这个颁发出来的,server-csr.json,这个是apiserver颁发的证书,为了启动https的证书
[root@k8s-master1 TLS]# cd k8s/
[root@k8s-master1 k8s]# ls
ca-config.json ca-csr.json generate_k8s_cert.sh kube-proxy-csr.json server-csr.json也就是应用程序会通过服务器的IP----》https API(自签的证书)
而进行交互的证书的服务器会有我们的VIP地址,也就是keepalived的地址,还有master的地址,还有就是SLB负载均衡的地址,都会进行交互,所以都要写进hosts,一般要多写几个进行预留
修改可信任的IP
[root@k8s-master1 k8s]# more server-csr.json
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1",
"127.0.0.1",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local",
"192.168.30.20",
"192.168.30.24",
"192.168.30.25",
"192.168.30.32",
"192.168.30.33",
"192.168.30.34" 最后一个没有逗号生成关于这些K8s相关的证书
[root@k8s-master1 k8s]# more generate_k8s_cert.sh
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
[root@k8s-master1 k8s]# bash generate_k8s_cert.sh 这里会有ca机构的证书,还有为kube-proxy和APIserver用到的证书
[root@k8s-master1 k8s]# ls *pem
ca-key.pem ca.pem kube-proxy-key.pem kube-proxy.pem server-key.pem server.pem五、部署Master组件
5.1 部署apiserver,controller-manager和scheduler
这里放在文件中,如果是下载的新版,需要将kube-apiserver kube-controller-
manager kubectl kube-scheduler放到kubernetes/bin目录下
[root@k8s-master1 ~]# tar xf k8s-master.tar.gz
[root@k8s-master1 ~]# ls
etcd etcd.tar.gz kube-apiserver.service kubernetes TLS
etcd.service k8s-master.tar.gz kube-controller-manager.service kube-scheduler.service TLS.tar.gz
[root@k8s-master1 ~]# cd kubernetes/
[root@k8s-master1 kubernetes]# ls
bin cfg logs ssl
[root@k8s-master1 kubernetes]# cd bin/
[root@k8s-master1 bin]# ls
kube-apiserver kube-controller-manager kubectl kube-scheduler这个目录时这样的,bin目录下都是可执行文件,cfg都是启动这个组件的配置,logs放日志的,ssl是放证书的
[root@k8s-master1 kubernetes]# tree
.
├── bin
│ ├── kube-apiserver
│ ├── kube-controller-manager
│ ├── kubectl
│ └── kube-scheduler
├── cfg
│ ├── kube-apiserver.conf
│ ├── kube-controller-manager.conf
│ ├── kube-scheduler.conf
│ └── token.csv
├── logs
└── ssl
4 directories, 8 files将我们的证书文件将拷贝到我们的目录当中来
[root@k8s-master1 kubernetes]# cp /root/TLS/k8s/*.pem ssl/
[root@k8s-master1 kubernetes]# ls ssl/
ca-key.pem ca.pem kube-proxy-key.pem kube-proxy.pem server-key.pem server.pem删除不用的证书
[root@k8s-master1 ssl]# rm -rf kube-proxy-key.pem kube-proxy.pem
[root@k8s-master1 ssl]# ls
ca-key.pem ca.pem server-key.pem server.pem进入到cfg目录下修改连接地址
[root@k8s-master1 cfg]# ls
kube-apiserver.conf kube-controller-manager.conf kube-scheduler.conf token.csv
修改etcd的连接地址和apiserver的地址
[root@k8s-master1 cfg]# vim kube-apiserver.conf
--etcd-servers=https://192.168.30.24:2379,https://192.168.30.26:2379,https://192.168.30.30:2379 \
--bind-address=192.168.30.24 \
--secure-port=6443 \
--advertise-address=192.168.30.24 \再将我们的配置文件放到我们的工作目录/opt下
[root@k8s-master1 ~]# mv kubernetes/ /opt/
[root@k8s-master1 ~]# ls
etcd etcd.tar.gz kube-apiserver.service kube-scheduler.service TLS.tar.gz
etcd.service k8s-master.tar.gz kube-controller-manager.service TLS
[root@k8s-master1 ~]# mv kube-apiserver.service kube-scheduler.service kube-controller-manager.service /usr/lib/systemd/system启动kube-apiserver
[root@k8s-master1 ~]# systemctl start kube-apiserver.service
[root@k8s-master1 ~]# ps -ef |grep kube
root 53921 1 99 22:24 ? 00:00:06 /opt/kubernetes/bin/kube-apiserver --logtostderr=false --v=2 --log-dir=/opt/kubernetes/logs --etcd-servers=https://192.168.30.24:2379,https://192.168.30.26:2379,https://192.168.30.30:2379 --bind-address=192.168.30.24 --secure-port=6443 --advertise-address=192.168.30.24 --allow-privileged=true --service-cluster-ip-range=10.0.0.0/24 --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction --authorization-mode=RBAC,Node --enable-bootstrap-token-auth=true --token-auth-file=/opt/kubernetes/cfg/token.csv --service-node-port-range=30000-32767 --kubelet-client-certificate=/opt/kubernetes/ssl/server.pem --kubelet-client-key=/opt/kubernetes/ssl/server-key.pem --tls-cert-file=/opt/kubernetes/ssl/server.pem --tls-private-key-file=/opt/kubernetes/ssl/server-key.pem --client-ca-file=/opt/kubernetes/ssl/ca.pem --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem --etcd-cafile=/opt/etcd/ssl/ca.pem --etcd-certfile=/opt/etcd/ssl/server.pem --etcd-keyfile=/opt/etcd/ssl/server-key.pem --audit-log-maxage=30 --audit-log-maxbackup=3 --audit-log-maxsize=100 --audit-log-path=/opt/kubernetes/logs/k8s-audit.log
root 53937 50851 0 22:24 pts/1 00:00:00 grep --color=auto kube日志文件地址
ERROR错误日志
INFO日志
WARNING警告日志
[root@k8s-master1 ~]# ls /opt/kubernetes/logs/
kube-apiserver.ERROR kube-apiserver.k8s-master1.root.log.INFO.20200329-222418.53921
kube-apiserver.INFO kube-apiserver.k8s-master1.root.log.WARNING.20200329-222420.53921
kube-apiserver.k8s-master1.root.log.ERROR.20200329-222424.53921 kube-apiserver.WARNING启动其他两个组件,日志也都会落到logs目录里面
[root@k8s-master1 ~]# systemctl start kube-controller-manager.service
[root@k8s-master1 ~]# systemctl start kube-scheduler.service 设置开机启动[root@k8s-master1 ~]# for i in $(ls /opt/kubernetes/bin/); do systemctl enable $i;done
将kubectl命令放到我们的系统变量里面
[root@k8s-master1 ~]# mv /opt/kubernetes/bin/kubectl /usr/local/bin/
[root@k8s-master1 ~]# kubectl get node
No resources found in default namespace.查看集群状态
[root@k8s-master1 ~]# kubectl get cs
NAME AGE
scheduler <unknown>
controller-manager <unknown>
etcd-0 <unknown>
etcd-2 <unknown>
etcd-1 <unknown>5.2 启动TLS Bootstrapping
为kubelet自动颁发证书
格式:token,用户,uid,用户组
[root@k8s-master1 ~]# cat /opt/kubernetes/cfg/token.csv
c47ffb939f5ca36231d9e3121a252940,kubelet-bootstrap,10001,"system:node-bootstrapper"给kubelet-bootstrap授权,将用户绑定到角色里面
[root@k8s-master1 ~]# kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap六、部署Node组件
1、docker容器引擎
2、kubelet
3、kube-proxy
启动流程---》配置文件---》systemd管理组件--》启动
6.1、现在去node节点去操作
1、二进制安装docker
二进制包下载地址:https://download.docker.com/linux/static/stable/x86_64/
解压压缩包,解压docker安装包
[root@k8s-node1 ~]# tar xf k8s-node.tar.gz
[root@k8s-node1 ~]# tar xf docker-18.09.6.tgz 将所有docker下的文件都放在系统变量里面,这样就可以使用docker命令
[root@k8s-node1 ~]# mv docker/* /usr/bin
[root@k8s-node1 ~]# docker
docker dockerd docker-init docker-proxy
[root@k8s-node1 ~]# mv docker.service /usr/lib/systemd/system
[root@k8s-node1 ~]# mkdir /etc/docker将docker加速这块附加进去
[root@k8s-node1 ~]# mv daemon.json /etc/docker/
[root@k8s-node1 ~]# systemctl start docker.service
[root@k8s-node1 ~]# systemctl enable docker.service查看docker版本以及详细信息docker info
2、安装kubelet
[root@k8s-node1 kubernetes]# tree
.
├── bin
│ ├── kubelet
│ └── kube-proxy
├── cfg
│ ├── bootstrap.kubeconfig
│ ├── kubelet.conf
│ ├── kubelet-config.yml
│ ├── kube-proxy.conf
│ ├── kube-proxy-config.yml
│ └── kube-proxy.kubeconfig
├── logs
└── ssl
4 directories, 8 files这个token我们需要在与node上的bootstrap的时候需要指定一致
在master上将这个token替换成一个新的,因为为了集群安全,我们重新生成一个
[root@k8s-master1 cfg]# head -c 16 /dev/urandom | od -An -t x | tr -d ' '
cac60aa54b4f2582023b99e819c033d2
[root@k8s-master1 cfg]# vim token.csv
[root@k8s-master1 cfg]# cat token.csv
cac60aa54b4f2582023b99e819c033d2,kubelet-bootstrap,10001,"system:node-bootstrapper"将这个token放在node1节点的 bootstrap.kubeconfig中,另外就是修改为master的连接地址
[root@k8s-node1 cfg]# vim bootstrap.kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority: /opt/kubernetes/ssl/ca.pem
server: https://192.168.30.24:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubelet-bootstrap
name: default
current-context: default
kind: Config
preferences: {}
users:
- name: kubelet-bootstrap
user:
token: cac60aa54b4f2582023b99e819c033d2Node加入的流程
首先kubelet进行启动,首先是要bootstrap像api-server进行发送请求,而api会效验这个token是不是可用的,它会去验证这个token,进行一个判断,通过之后它才会为这个kubelet颁发证书,这个kubelet才能启动成功
如果kubelet启动不成功,一般就是token写的不对,或者使用的证书不一致,或者bootstrap不对,才会启动失败
修改kube-proxy.kubeconfig文件连接api的地址
[root@k8s-node1 cfg]# more kube-proxy.kubeconfig
apiVersion: v1
clusters:
- cluster:
certificate-authority: /opt/kubernetes/ssl/ca.pem
server: https://192.168.30.24:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kube-proxy
name: default
current-context: default
kind: Config
preferences: {}
users:
- name: kube-proxy
user:
client-certificate: /opt/kubernetes/ssl/kube-proxy.pem
client-key: /opt/kubernetes/ssl/kube-proxy-key.pem将我们的kubelet配置修改完之后放到我们的工作目录中,启动kubelet
[root@k8s-node1 ~]# mv kubernetes/ /opt
[root@k8s-node1 ~]# ls
cni-plugins-linux-amd64-v0.8.2.tgz docker docker-18.09.6.tgz k8s-node.tar.gz kubelet.service kube-proxy.service
[root@k8s-node1 ~]# mv *service /usr/lib/systemd/system到master节点将证书放到node的工作目录中[root@k8s-master1 ~]# scp /root/TLS/k8s/{ca,kube-proxy-key,kube-proxy}.pem 192.168.30.26:/opt/kubernetes/ssl/
因为这里新换的token,需要重新启动kube-apiserver
[root@k8s-master1 ~]# systemctl restart kube-apiserver
[root@k8s-node1 ~]# systemctl start kubelet
[root@k8s-node1 ~]# systemctl enable kubelet另外就是启动kubelet的时候会自动颁发证书
[root@k8s-node1 ssl]# ls
ca.pem kubelet-client-2020-03-30-00-22-59.pem kubelet-client-current.pem kubelet.crt kubelet.key kube-proxy-key.pem kube-proxy.pem查看日志有没有报错
一般如果我们去替换这个新的token的时候,需要重新启动一个kube-apiserver,这个token会验证node节点上的token
[root@k8s-node1 cfg]# tail /opt/kubernetes/logs/kubelet.INFO
I0330 00:16:28.853703 63824 feature_gate.go:216] feature gates: &{map[]}
I0330 00:16:28.853767 63824 plugins.go:100] No cloud provider specified.
I0330 00:16:28.853777 63824 server.go:526] No cloud provider specified: "" from the config file: ""
I0330 00:16:28.853798 63824 bootstrap.go:119] Using bootstrap kubeconfig to generate TLS client cert, key and kubeconfig file
I0330 00:16:28.855492 63824 bootstrap.go:150] No valid private key and/or certificate found, reusing existing private key or creating a new one
I0330 00:16:28.879242 63824 csr.go:69] csr for this node already exists, reusing
I0330 00:16:28.881728 63824 csr.go:77] csr for this node is still valid查看csr的请求加入
[root@k8s-master1 cfg]# kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-ltMSc51cdCz2-pZlVbe1FX4MUsZ8pr84KKJG_ttajoI 2m20s kubelet-bootstrap Pending
[root@k8s-master1 cfg]# kubectl certificate approve node-csr-ltMSc51cdCz2-pZlVbe1FX4MUsZ8pr84KKJG_ttajoI
certificatesigningrequest.certificates.k8s.io/node-csr-ltMSc51cdCz2-pZlVbe1FX4MUsZ8pr84KKJG_ttajoI approved
[root@k8s-master1 cfg]# kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-ltMSc51cdCz2-pZlVbe1FX4MUsZ8pr84KKJG_ttajoI 7m57s kubelet-bootstrap Approved,Issued已经加入到node节点
[root@k8s-master1 cfg]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 NotReady <none> 40s v1.16.0然后部署另外一个node
将包拉进Node2中
安装docker
[root@k8s-node2 ~]# ls
k8s-node.zip
[root@k8s-node2 ~]# unzip k8s-node.zip
[root@k8s-node2 ~]# cd k8s-node/
[root@k8s-node2 k8s-node]# mv *.service /usr/lib/systemd/system
[root@k8s-node2 k8s-node]# tar xf docker-18.09.6.tgz
[root@k8s-node2 k8s-node]# mv docker/* /usr/bin/
[root@k8s-node2 k8s-node]# mkdir /etc/docker
[root@k8s-node2 k8s-node]# mv daemon.json /etc/docker/
[root@k8s-node2 k8s-node]# systemctl start docker.service
[root@k8s-node2 k8s-node]# systemctl enable docker.servicek8s会调用docker的API 也就是ls /var/run/docker.sock
修改kubelet和kube-proxy的节点的监听地址还有token,以及主机名称把k8s-node1改成k8s-node2
[root@localhost ]# cp -r kubernetes/ /opt
[root@k8s-node2 opt]# vim kubernetes/cfg/bootstrap.kubeconfig
[root@k8s-node2 opt]# vim kubernetes/cfg/kube-proxy.kubeconfig
[root@k8s-node2 opt]# vim kubernetes/cfg/kubelet.conf
[root@k8s-node2 opt]# vim kubernetes/cfg/kube-proxy-config.yml
[root@k8s-node2 opt]# grep 192 kubernetes/cfg/*
kubernetes/cfg/bootstrap.kubeconfig: server: https://192.168.30.24:6443
kubernetes/cfg/kube-proxy.kubeconfig: server: https://192.168.30.24:6443将证书也拷贝到node2节点上[root@k8s-master1 ~]# scp /root/TLS/k8s/{ca,kube-proxy-key,kube-proxy}.pem 192.168.30.30:/opt/kubernetes/ssl/
现在就可以启动kubelet和kube-proxy
[root@k8s-node2 opt]# systemctl restart kubelet
[root@k8s-node2 opt]# systemctl restart kube-proxymaster节点收到请求加入的认证并通过
[root@k8s-master1 ~]# kubectl certificate approve node-csr-s4JhRFW5ncRhGL3jaO5btQLaYI89eUhJAy6P8FA6d18
certificatesigningrequest.certificates.k8s.io/node-csr-s4JhRFW5ncRhGL3jaO5btQLaYI89eUhJAy6P8FA6d18 approved
[root@k8s-master1 ~]# kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-ltMSc51cdCz2-pZlVbe1FX4MUsZ8pr84KKJG_ttajoI 31m kubelet-bootstrap Approved,Issued
node-csr-s4JhRFW5ncRhGL3jaO5btQLaYI89eUhJAy6P8FA6d18 23s kubelet-bootstrap Approved,Issued
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 NotReady <none> 24m v1.16.0
k8s-node2 NotReady <none> 53s v1.16.0查看报错信息这个开源看到CNI的插件没有准备就绪,因为它会/etc/cni/net.d这个目录下读取cni的插件子网信息
[root@k8s-node2 ~]# tail /opt/kubernetes/logs/kubelet.INFO
E0330 00:49:09.558366 64374 kubelet.go:2187] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
W0330 00:49:13.935566 64374 cni.go:237] Unable to update cni config: no networks found in /etc/cni/net.d七、部署CNI网络插件(Calico)

二进制包下载地址:https://github.com/containernetworking/plugins/releases
这里是放在压缩包里面的,直接解压
[root@k8s-node1 ~]# tar xf cni-plugins-linux-amd64-v0.8.2.tgz
[root@k8s-node1 ~]# mkdir /opt/cni/bin /etc/cni/net.d -p
[root@k8s-node1 ~]# tar xf cni-plugins-linux-amd64-v0.8.2.tgz -C /opt/cni/bin/将这个也放在node2上一份
[root@k8s-node1 ~]# scp -r /opt/cni/ 192.168.30.30:/opt
[root@k8s-node2 ~]# mkdir /etc/cni/net.d -p现在已经都在每台node上启动了cni的接口,主要用来接第三方的网络
确保每台Node都启动cni的功能
[root@k8s-node2 ~]# more /opt/kubernetes/cfg/kubelet.conf
KUBELET_OPTS="--logtostderr=false \
--v=2 \
--log-dir=/opt/kubernetes/logs \
--hostname-override=k8s-node2 \
--network-plugin=cni \
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \
--config=/opt/kubernetes/cfg/kubelet-config.yml \
--cert-dir=/opt/kubernetes/ssl \
--pod-infra-container-image=zhaocheng172/pause-amd64:3.0"部署Calico网络
7.1、Calico 部署git clone [email protected]:zhaocheng172/calico.git
这里需要将你的公钥给我,才能拉下来,不然没有权限
下载完后还需要修改里面配置项:
因为Calico使用的etcd一些策略一些网络配置信息的,还有一些calico的属性信息都是保存在etcd中的,而etcd也在k8s集群中部署,所以我们之间使用现有的k8s的etcd就可以了,如果使用https还要配置一下证书,然后选择一些pod的网络,还有工作模式
具体步骤如下:
配置连接etcd地址,如果使用https,还需要配置证书。
(ConfigMap,Secret)
根据实际网络规划修改Pod CIDR(CALICO_IPV4POOL_CIDR)
选择工作模式(CALICO_IPV4POOL_IPIP),支持BGP,IPIPcalico也是使用configmap保存配置文件的,secret是存储etcd它的https的证书的,分为3项
etcd-key: null
etcd-cert: null
etcd-ca: null指定etcd连接的地址: etcd_endpoints: "http://<ETCD_IP>:<ETCD_PORT>;"
当启动secret挂载到容器中时,它的文件是挂载哪个文件下,在这里指定好
etcd_ca: "" # "/calico-secrets/etcd-ca"
etcd_cert: "" # "/calico-secrets/etcd-cert"
etcd_key: "" # "/calico-secrets/etcd-key"现在进行一下切换网络到calico
一、所以修改etcd一共修改3个位置
1、etcd的证书
我放证书的位置是在/opt/etcd/ssl下,但是我们需要放到secret里面,需要要转换成base64编码才能去存储,而这样执行也是由换行的,必须将它拼接成一个整体的字符串[root@k8s-master1 ~]# cat /opt/etcd/ssl/ca.pem |base64 -w 0
将对应的都添进去,将注释去掉
# etcd-key: null 将对应ssl下的证书转换成base64编码放进来,并去掉注释
# etcd-cert: null
# etcd-ca: null2、要读取secret落地到容器中位置,直接将注释去掉就可以了
etcd_ca: "/calico-secrets/etcd-ca"
etcd_cert: "/calico-secrets/etcd-cert"
etcd_key: "/calico-secrets/etcd-key"3、连接etcd的字符串,这与k8s连接API的字符串是一样的
这个是在[root@k8s-master1 ~]# cat /opt/kubernetes/cfg/kube-apiserver.conf 这个目录下,因为每个集群都是自己部署的,位置可能不一样etcd_endpoints: "https://192.168.30.24:2379,https://192.168.30.26:2379,https://192.168.30.30:2379"
将这个证书放进放进calico配置中
二、根据实际网络规划修改Pod CIDR
这个位置在这个是默认的,需要改成自己的
- name: CALICO_IPV4POOL_CIDR
value: "192.168.0.0/16"可以在控制器配置的默认的也就是这个10.244.0.0.16这个地址
[root@k8s-master1 ~]# cat /opt/kubernetes/cfg/kube-controller-manager.conf
--cluster-cidr=10.244.0.0/16 \
在配置中改成这个
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"三、选择工作模式
IPIP
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Never"这个变量问你要不要开启IPIP,因为有两种模式,第一种就是IPIP,第二种就是BGP
其实它应用最多就是BGP,将这个Always改成Never,就是将它关闭的意思
[root@k8s-master1 calico]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-77c84fb6b6-th2bk 1/1 Running 0 29s
kube-system calico-node-27g8b 1/1 Running 0 3m48s
kube-system calico-node-wnc5f 1/1 Running 0 3m48s
[root@k8s-master1 calico]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 75m v1.16.0
k8s-node2 Ready <none> 51m v1.16.07.2、Calico 管理工具
这里会用到calico的管理工具,用它管理一些calico的配置,比如切换成ipip模式
这里有两种方式去获取calico的网络,第一种就是通过calicoctl的长连接tcp的监听去获取
一种是通过etcd去获取我们的calico的子网信息
因为环境中没有在master中部署kubelet组件,所以,这个需要在node节点去安装
下载工具:https://github.com/projectcalico/calicoctl/releases
# wget -O /usr/local/bin/calicoctl https://github.com/projectcalico/calicoctl/releases/download/v3.9.1/calicoctl
# chmod +x /usr/local/bin/calicoctl安装好这个管理工具之后就可以查看当前节点BGP的节点状态
[root@localhost ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 192.168.30.30 | node-to-node mesh | up | 05:01:03 | Established |
+---------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.可以通过bird查看监听信息
[root@localhost ~]# netstat -anpt |grep bird
tcp 0 0 0.0.0.0:179 0.0.0.0:* LISTEN 74244/bird
tcp 0 0 192.168.30.26:179 192.168.30.30:50692 ESTABLISHED 74244/bird 查看Pod的logs日志,默认是需要经过授权才能查看,为提供安全性,kubelet禁止匿名访问,必须授权才可以。
[root@k8s-master1 calico]# kubectl logs calico-node-jq86m -n kube-system
Error from server (Forbidden): Forbidden (user=kubernetes, verb=get, resource=nodes, subresource=proxy) ( pods/log calico-node-jq86m)
[root@k8s-master1 ~]# kubectl apply -f apiserver-to-kubelet-rbac.yaml另外一种就是通过etcd去获取
[root@k8s-master1 ]# # mkdir /etc/calico
# vim /etc/calico/calicoctl.cfg
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
datastoreType: "etcdv3"
etcdEndpoints: "https://192.168.30.24:2379,https://192.168.30.26:2379,https://192.168.30.30:2379"
etcdKeyFile: "/opt/etcd/ssl/server-key.pem"
etcdCertFile: "/opt/etcd/ssl/server.pem"
etcdCACertFile: "/opt/etcd/ssl/ca.pem"使用calicocatl get node了,这样的话就是在etcd中去拿的数据了
[root@k8s-master ~]# calicoctl get node
NAME
k8s-node1
k8s-node2 查看 IPAM的IP地址池:
[root@k8s-master ~]# calicoctl get ippool -o wide
NAME CIDR NAT IPIPMODE VXLANMODE DISABLED SELECTOR
default-ipv4-ippool 10.244.0.0/16 true Never Never false all()八、部署Coredns
部署coredns[root@k8s-master1 calico]# kubectl apply -f coredns.yaml
测试解析dns解析与跨主机网络容器通信
[root@localhost ~]# more busybox.yaml
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- name: busybox
image: busybox:1.28.4
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always测试是否可以正常解析
[root@localhost ~]# kubectl exec -it busybox sh
/ # nslookup kubernetes
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
/ # nslookup nginx
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: nginx
Address 1: 10.0.0.96 nginx.default.svc.cluster.local
/ # ping 192.168.30.24测试跨主机容器网络直接的通信
[root@localhost ~]# kubectl exec -it busybox sh
/ # ping 10.244.36.64
PING 10.244.36.64 (10.244.36.64): 56 data bytes
64 bytes from 10.244.36.64: seq=0 ttl=62 time=0.712 ms
64 bytes from 10.244.36.64: seq=1 ttl=62 time=0.582 ms
^C
--- 10.244.36.64 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.582/0.647/0.712 ms
/ # ping 10.244.36.67
PING 10.244.36.67 (10.244.36.67): 56 data bytes
64 bytes from 10.244.36.67: seq=0 ttl=62 time=0.385 ms
64 bytes from 10.244.36.67: seq=1 ttl=62 time=0.424 ms
^C
--- 10.244.36.67 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.385/0.404/0.424 ms
/ # ping 10.244.169.130
PING 10.244.169.130 (10.244.169.130): 56 data bytes
64 bytes from 10.244.169.130: seq=0 ttl=63 time=0.118 ms
64 bytes from 10.244.169.130: seq=1 ttl=63 time=0.097 ms
^C
--- 10.244.169.130 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.097/0.107/0.118 ms
/ # exit测试部署pod是否可以正常工作
[root@k8s-master ~]# kubectl create deployment nginx --image=nginx
[root@k8s-master ~]# kubectl expose deployment nginx --port=80 --type=NodePort 访问测试
[root@k8s-master1 ~]# kubectl get pod,svc -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/busybox 1/1 Running 0 32m 10.244.169.132 k8s-node2 <none> <none>
pod/nginx-86c57db685-h4gwh 1/1 Running 0 65m 10.244.169.131 k8s-node2 <none> <none>
pod/nginx-86c57db685-jzcnn 1/1 Running 0 65m 10.244.36.66 k8s-node1 <none> <none>
pod/nginx-86c57db685-ms8g7 1/1 Running 0 74m 10.244.36.64 k8s-node1 <none> <none>
pod/nginx-86c57db685-nzzgh 1/1 Running 0 63m 10.244.36.67 k8s-node1 <none> <none>
pod/nginx-86c57db685-w89gq 1/1 Running 0 65m 10.244.169.130 k8s-node2 <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 143m <none>
service/nginx NodePort 10.0.0.96 <none> 80:30562/TCP 90m app=nginx访问node节点加端口
九、扩容Node节点
添加一台新机器,做好初始化
扩容node分为两步,第一步部署node相关组件,第二步打通容器网络之间的通信
将包拉进Node2中
1、部署node相关组件,安装docker
[root@k8s-node2 ~]# ls
k8s-node.zip
[root@k8s-node3 ~]# unzip k8s-node.zip
[root@k8s-node3 ~]# cd k8s-node/
[root@k8s-node3 k8s-node]# mv *.service /usr/lib/systemd/system
[root@k8s-node3 k8s-node]# tar xf docker-18.09.6.tgz
[root@k8s-node3 k8s-node]# mv docker/* /usr/bin/
[root@k8s-node3 k8s-node]# mkdir /etc/docker
[root@k8s-node3 k8s-node]# mv daemon.json /etc/docker/
[root@k8s-node3 k8s-node]# systemctl start docker.service
[root@k8s-node3 k8s-node]# systemctl enable docker.servicek8s会调用docker的API 也就是ls /var/run/docker.sock
修改kubelet和kube-proxy的节点的监听地址还有token,以及主机名称把k8s-node1改成k8s-node2
[root@k8s-node3 ]# cp -r kubernetes/ /opt
[root@k8s-node3 opt]# vim kubernetes/cfg/bootstrap.kubeconfig
[root@k8s-node3 opt]# vim kubernetes/cfg/kube-proxy.kubeconfig
[root@k8s-node3 opt]# vim kubernetes/cfg/kubelet.conf
[root@k8s-node3 opt]# vim kubernetes/cfg/kube-proxy-config.yml
[root@k8s-node3 opt]# grep 192 kubernetes/cfg/*
kubernetes/cfg/bootstrap.kubeconfig: server: https://192.168.30.24:6443
kubernetes/cfg/kube-proxy.kubeconfig: server: https://192.168.30.24:6443将证书也拷贝到node3节点上
[root@k8s-master1 ~]# scp /root/TLS/k8s/{ca,kube-proxy-key,kube-proxy}.pem 192.168.30.31:/opt/kubernetes/ssl/现在就可以启动kubelet和kube-proxy
[root@k8s-node3 opt]# systemctl restart kubelet
[root@k8s-node3 opt]# systemctl restart kube-proxymaster节点收到请求加入的认证并通过
[root@k8s-master1 ~]# kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-yMrN2KoD8sEi2rssHCWxyFUdqmngvXodCtnKXrfoIMU 15s kubelet-bootstrap Pending
[root@k8s-master1 ~]# kubectl certificate approve node-csr-yMrN2KoD8sEi2rssHCWxyFUdqmngvXodCtnKXrfoIMU
certificatesigningrequest.certificates.k8s.io/node-csr-yMrN2KoD8sEi2rssHCWxyFUdqmngvXodCtnKXrfoIMU approved
[root@k8s-master1 ~]# kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-yMrN2KoD8sEi2rssHCWxyFUdqmngvXodCtnKXrfoIMU 41s kubelet-bootstrap Approved,Issued
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 165m v1.16.0
k8s-node2 Ready <none> 153m v1.16.0
k8s-node3 NotReady <none> 5s v1.16.0
2、打通容器网络通信
由于我们使用的CNI插件,所以会自动将新加入的Node加入网络当中
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 168m v1.16.0
k8s-node2 Ready <none> 156m v1.16.0
k8s-node3 Ready <none> 3m43s v1.16.0[root@k8s-master1 ~]# kubectl get pod -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default busybox 1/1 Running 1 66m 10.244.169.132 k8s-node2 <none> <none>
default nginx-86c57db685-ms8g7 1/1 Running 0 109m 10.244.36.64 k8s-node1 <none> <none>
kube-system calico-kube-controllers-77c84fb6b6-nggl5 1/1 Running 0 121m 192.168.30.30 k8s-node2 <none> <none>
kube-system calico-node-4xx8g 1/1 Running 0 121m 192.168.30.30 k8s-node2 <none> <none>
kube-system calico-node-9bw46 1/1 Running 0 4m4s 192.168.30.31 k8s-node3 <none> <none>
kube-system calico-node-zfmtt 1/1 Running 0 121m 192.168.30.26 k8s-node1 <none> <none>
kube-system coredns-59fb8d54d6-pq2bt 1/1 Running 0 139m 10.244.169.128 k8s-node2 <none> 测试容器通信环境
[root@k8s-master1 ~]# kubectl exec -it busybox sh
/ # ping 10.244.107.192
PING 10.244.107.192 (10.244.107.192): 56 data bytes
64 bytes from 10.244.107.192: seq=0 ttl=62 time=1.023 ms
64 bytes from 10.244.107.192: seq=1 ttl=62 time=0.454 ms
^C
--- 10.244.107.192 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.454/0.738/1.023 ms
/ # ping 10.244.36.68
PING 10.244.36.68 (10.244.36.68): 56 data bytes
64 bytes from 10.244.36.68: seq=0 ttl=62 time=0.387 ms
64 bytes from 10.244.36.68: seq=1 ttl=62 time=0.350 ms
^C
--- 10.244.36.68 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.350/0.368/0.387 ms
/ # ping 192.168.30.26
PING 192.168.30.26 (192.168.30.26): 56 data bytes
64 bytes from 192.168.30.26: seq=0 ttl=63 time=0.359 ms
64 bytes from 192.168.30.26: seq=1 ttl=63 time=0.339 ms
^C
--- 192.168.30.26 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.339/0.349/0.359 ms
/ # ping 192.168.30.30
PING 192.168.30.30 (192.168.30.30): 56 data bytes
64 bytes from 192.168.30.30: seq=0 ttl=64 time=0.075 ms
^C
--- 192.168.30.30 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.075/0.075/0.075 ms
/ # ping 192.168.30.31
PING 192.168.30.31 (192.168.30.31): 56 data bytes
64 bytes from 192.168.30.31: seq=0 ttl=63 time=0.377 ms
64 bytes from 192.168.30.31: seq=1 ttl=63 time=0.358 ms十、缩容Node节点
如果想从kubernetes集群中删除节点,正确流程
1、 获取节点列表
Kubectl get node
2、 设置不可调度
Kubectl cordon $node_name
3、 驱逐节点上额pod
Kubectl drain $node_name –I gnore-daemonsets
4、 移除节点
该节点上已经没有任何资源了,可以直接移除节点:
Kubectl delete node $node_node
这样,我们平滑移除了一个k8s节点[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 179m v1.16.0
k8s-node2 Ready <none> 167m v1.16.0
k8s-node3 Ready <none> 14m v1.16.0
[root@k8s-master1 ~]# kubectl cordon k8s-node3
node/k8s-node3 cordoned
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 3h v1.16.0
k8s-node2 Ready <none> 167m v1.16.0
k8s-node3 Ready,SchedulingDisabled <none> 14m v1.16.0
[root@k8s-master1 ~]# kubectl drain k8s-node3
node/k8s-node3 already cordoned
error: unable to drain node "k8s-node3", aborting command...
There are pending nodes to be drained:
k8s-node3
error: cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): kube-system/calico-node-9bw46
[root@k8s-master1 ~]# kubectl drain k8s-node3 --ignore-daemonsets
node/k8s-node3 already cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/calico-node-9bw46
evicting pod "nginx-86c57db685-gjswt"
evicting pod "nginx-86c57db685-8cks8"
pod/nginx-86c57db685-gjswt evicted
pod/nginx-86c57db685-8cks8 evicted
node/k8s-node3 evicted
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 3h1m v1.16.0
k8s-node2 Ready <none> 169m v1.16.0
k8s-node3 Ready,SchedulingDisabled <none> 16m v1.16.0
[root@k8s-master1 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 1 79m 10.244.169.132 k8s-node2 <none> <none>
nginx-86c57db685-b6xjn 1/1 Running 0 9m23s 10.244.36.68 k8s-node1 <none> <none>
nginx-86c57db685-mrffs 1/1 Running 0 39s 10.244.36.69 k8s-node1 <none> <none>
nginx-86c57db685-ms8g7 1/1 Running 0 122m 10.244.36.64 k8s-node1 <none> <none>
nginx-86c57db685-qfl2f 1/1 Running 0 39s 10.244.169.134 k8s-node2 <none> <none>
nginx-86c57db685-xwxzv 1/1 Running 0 9m23s 10.244.169.133 k8s-node2 <none> <none>
[root@k8s-master1 ~]# kubectl delete node k8s-node3
node "k8s-node3" deleted
[root@k8s-master1 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 1 80m 10.244.169.132 k8s-node2 <none> <none>
nginx-86c57db685-b6xjn 1/1 Running 0 9m35s 10.244.36.68 k8s-node1 <none> <none>
nginx-86c57db685-mrffs 1/1 Running 0 51s 10.244.36.69 k8s-node1 <none> <none>
nginx-86c57db685-ms8g7 1/1 Running 0 122m 10.244.36.64 k8s-node1 <none> <none>
nginx-86c57db685-qfl2f 1/1 Running 0 51s 10.244.169.134 k8s-node2 <none> <none>
nginx-86c57db685-xwxzv 1/1 Running 0 9m35s 10.244.169.133 k8s-node2 <none> <none>
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 3h2m v1.16.0
k8s-node2 Ready <none> 170m v1.16.0十一、部署高可用集群
在k8s中,会针对master节点做高可用,如果是单点,一个master节点的话,当我们去调度任务,或者拉取镜像的镜像,调用控制器,一个也会影响我们的实际工作,所以会部署一个无单点的架构,会有多个Master,那么多个Master会涉及到node去连接一个api去工作,如果只部署一个nginx的话,也是可以实现这么一个负载均衡的,但是如果这个nginx挂了,那就无法正常提供工作了,所以就需要这么一个主备的,为这个nginx加一个备机器,这里选择一个四层做负载均衡,nginx支持四层和七层,七层主要代理http,四层主要代理TCP和UDP,四层不考虑是什么协议传过来的,只负责转发,所以性能会更好,而七层会分析应用层的协议,性能会差一点,但是也会满足数据分析的一些需求,比如针对域名的转发。
这里会用到一个高可用keepalived,这个keepalived主要要实现健康检查和故障转移,比如有两台机器,做热备的正常话就是用户先去访问A,当A挂了,用户会无感知的去访问B,才能正常去给用户提供服务,如果两个机器做双击热备的话,肯定需要从用户的角度去考虑,用户是从域名或者IP访问进来,一个域名来解析一个IP ,也就是Keepalived在每台机器都安装后,会相互的探测,如果A挂了的话,就接管这个IP,也就是这个虚拟IP,VIP的概念,这个IP不会实际在某个机器上,它是由keepaliced去管控的,它正常工作在其中一个机器上,而域名会解析到这个VIP,正常在Master,也就是在主上,另一个为Backup角色,所以用户访问时先通过VIP,当A机器挂的话,它会由B机器进行接管,它会拿到这个VIP到backup上,而用户还是访问的这个VIP,然后另外一个nginx去处理的请求,同时可以实现一个双击热备的实现,任何一个挂的话都不会影响
这样的话,每个Node都会连接这个VIP地址,由原来连接的master改为VIP地址,那么这么高可用架构就组建起来了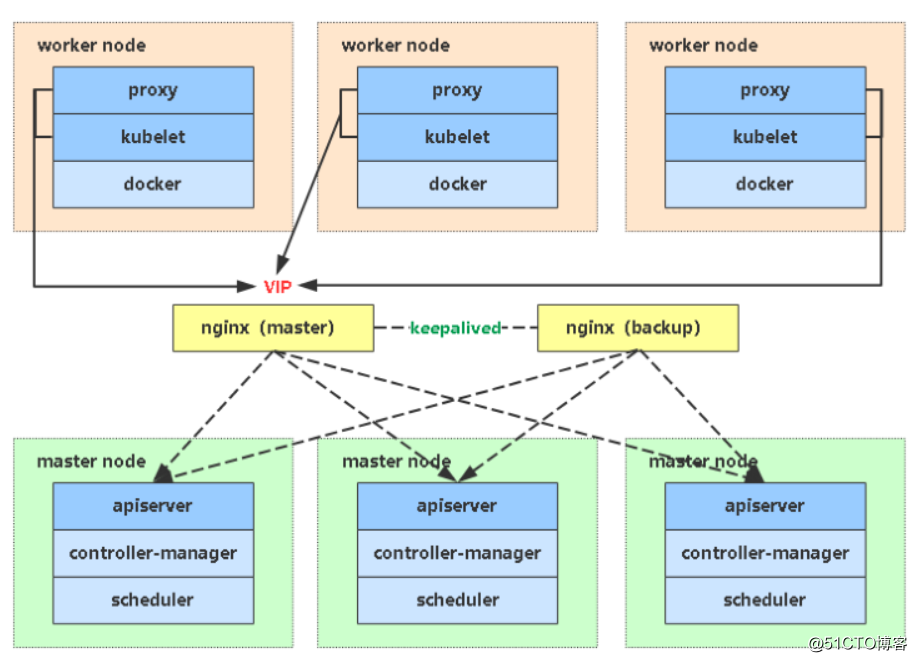
将master1上的文件拷贝到新的master2上面[root@k8s-master1 ~]# scp -r /opt/kubernetes/ 192.168.30.25:/opt
在master2创建
mkdir /opt/etcd/ -pv
[root@k8s-master1 ~]# scp -r /opt/etcd/ssl/ 192.168.30.25:/opt/etcd
[root@k8s-master1 ~]# scp /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service [email protected]:/usr/lib/systemd/system修改master2上api-server的监听地址
都换成监听的192.168.30.25
启动每个组件[root@k8s-master2 opt]# for i in $(ls /opt/kubernetes/bin/); do systemctl start $i; systemctl enable $i;done
确保每个组件都启动起来ps -ef |grep kube
将kubectl也拷贝到master2节点上
[root@k8s-master1 ~]# scp /usr/local/bin/kubectl 192.168.30.25:/usr/local/bin/
[email protected]'s password:
kubectl master2可以获取到状态
[root@k8s-master2 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 5h52m v1.16.0
k8s-node2 Ready <none> 5h39m v1.16.0每个节点都安装nginx负载均衡,配置都是一样的配置
nginx rpm包:http://nginx.org/packages/rhel/7/x86_64/RPMS/
[root@slb1 ~]# rpm -vih http://nginx.org/packages/rhel/7/x86_64/RPMS/nginx-1.16.0-1.el7.ngx.x86_64.rpm
[root@slb2 ~]# rpm -vih http://nginx.org/packages/rhel/7/x86_64/RPMS/nginx-1.16.0-1.el7.ngx.x86_64.rpm
这里如果是三个MASTER节点的话,直接在upstream加入第三个master,然后交给Nginx做负载均衡
[root@slb1 ~]# cat /etc/nginx/nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.30.24:6443;
server 192.168.30.25:6443;
}
server {
listen 6443;
proxy_pass k8s-apiserver;
}
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}启动Nginx并设置开机启动
[root@slb1 ~]# systemctl start nginx
[root@slb1 ~]# systemctl enable nginx
[root@slb2 ~]# systemctl start nginx
[root@slb2 ~]# systemctl enable nginx现在去做keepalived做主备
如果是使用的阿里云的云服务器,直接之间使用slb做Nginx的入口
[root@slb1 ~]# yum -y install keepalived
[root@slb2 ~]# yum -y install keepalived这里写好直接放进来
[root@slb1 ~]# rz -E
rz waiting to receive.
[root@slb1 ~]# unzip HA.zip
[root@slb1 ~]# cd HA/
[root@slb1 HA]# ls
check_nginx.sh keepalived-backup.conf keepalived-master.conf nginx.conf
[root@slb1 HA]# mv keepalived-master.conf keepalived.conf
[root@slb1 HA]# mv keepalived.conf /etc/keepalived/
修改VIP的地址,另外根据自己的网卡写相应的网卡设备名称,主这边设置的是100优先级,backup设置的90
[root@slb1 HA]# vim /etc/keepalived/keepalived.conf 配置文件这个配置主要声明用于Nginx健康状态检查,用来判断Nginx是否正常工作,如果是正常工作就不会实现故障转移,要是故障的话,备的机器会收到接管VIP同时提供VIP的服务
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"将检查脚本放到指定目录
这各脚本主要对keepalive的返回码进行判断,如果返回码是1,这个检查时失败的,就是挂掉了,那就触发故障转移的动作,如果返回0就是正常的,也就是非0的状态下认为nginx挂了,所以通过状态码的情况去判断是否正常
[root@slb1 HA]# ls
check_nginx.sh keepalived-backup.conf nginx.conf
[root@slb1 HA]# mv check_nginx.sh /etc/keepalived/
[root@slb1 HA]# more /etc/keepalived/check_nginx.sh
#!/bin/bash
count=$(ps -ef |grep nginx |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi现在到备的服务器下,将我们的准备的包放在/etc/keepalived下,并修改VIP地址为192.168.30.20
[root@slb1 HA]# ls
keepalived-backup.conf nginx.conf
[root@slb1 HA]# scp keepalived-backup.conf 192.168.30.33:/etc/keepalived/
[root@slb1 HA]# scp /etc/keepalived/check_nginx.sh 192.168.30.33:/etc/keepalived/
[root@slb2 keepalived]# vim keepalived.conf 两个配置都设置完成之后,将脚本加执行权限,进行启动
[root@slb1 keepalived]# chmod +x check_nginx.sh
[root@slb2 keepalived]# chmod +x check_nginx.sh
[root@slb1 keepalived]# systemctl start keepalived.service
[root@slb1 keepalived]# systemctl enable keepalived.service
[root@slb1 keepalived]# ps -ef |grep keepalived
root 60856 1 0 18:41 ? 00:00:00 /usr/sbin/keepalived -D
root 60857 60856 0 18:41 ? 00:00:00 /usr/sbin/keepalived -D
root 60858 60856 0 18:41 ? 00:00:00 /usr/sbin/keepalived -D
root 61792 12407 0 18:43 pts/1 00:00:00 grep --color=auto keepalived
[root@slb2 keepalived]# ps -ef |grep keepalived
root 60816 1 0 18:43 ? 00:00:00 /usr/sbin/keepalived -D
root 60817 60816 0 18:43 ? 00:00:00 /usr/sbin/keepalived -D
root 60820 60816 0 18:43 ? 00:00:00 /usr/sbin/keepalived -D
root 60892 12595 0 18:43 pts/1 00:00:00 grep --color=auto keepalived在主的master上可以看到vip地址
[root@slb1 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:b9:6f:9d brd ff:ff:ff:ff:ff:ff
inet 192.168.30.32/24 brd 192.168.30.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.30.20/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::921:4cfb:400e:c875/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:bf:3f:61 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN group default qlen 1000
link/ether 52:54:00:bf:3f:61 brd ff:ff:ff:ff:ff:ff判断是否可以飘移
停掉这个slb1的Nginx[root@slb1 ~]# systemctl stop nginx
发现VIP地址已经在slb上的,其实这个slb去访问这个Nginx的时候,通过这个VIP也是可以访问到的,大概切换的过程中有2秒的切换的时间,
[root@slb2 keepalived]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:e9:ce:b8 brd ff:ff:ff:ff:ff:ff
inet 192.168.30.33/24 brd 192.168.30.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.30.20/24 scope global secondary ens33现在VIP已经配置好的,现在只需要将node的连接地址换成VIP地址
[root@k8s-node1 ~]# cd /opt/kubernetes/cfg/
[root@k8s-node1 cfg]# sed -i 's#192.168.30.24#192.168.30.20#g' *
[root@k8s-node1 cfg]# grep 192 *
bootstrap.kubeconfig: server: https://192.168.30.20:6443
kubelet.kubeconfig: server: https://192.168.30.20:6443
kube-proxy.kubeconfig: server: https://192.168.30.20:6443
[root@k8s-node2 cfg]# sed -i 's#192.168.30.24#192.168.30.20#g' *
[root@k8s-node2 cfg]# grep 192 *
bootstrap.kubeconfig: server: https://192.168.30.20:6443
kubelet.kubeconfig: server: https://192.168.30.20:6443
kube-proxy.kubeconfig: server: https://192.168.30.20:6443现在让slb的VIP地址开启日志的实时输出,当我们启动kubelet的时候,日志就会正常输出
[root@slb1 ~]# tail /var/log/nginx/k8s-access.log -f
192.168.30.26 192.168.30.24:6443 - [30/Mar/2020:19:10:51 +0800] 200 1160
192.168.30.26 192.168.30.25:6443 - [30/Mar/2020:19:10:51 +0800] 200 1159
192.168.30.30 192.168.30.25:6443 - [30/Mar/2020:19:11:09 +0800] 200 1160
192.168.30.30 192.168.30.24:6443 - [30/Mar/2020:19:11:09 +0800] 200 1160重启kubelet和kube-proxy,会发现日志输出
[root@k8s-node1 ~]# systemctl restart kubelet
[root@k8s-node1 ~]# systemctl restart kube-proxy
[root@k8s-node2 cfg]# systemctl restart kubelet
[root@k8s-node2 cfg]# systemctl restart kube-proxy集群现在也是稳定运行
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-node1 Ready <none> 7h v1.16.0
k8s-node2 Ready <none> 6h48m v1.16.0
[root@k8s-master1 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default busybox 1/1 Running 5 5h18m
default nginx-86c57db685-b6xjn 1/1 Running 0 4h7m
default nginx-86c57db685-mrffs 1/1 Running 0 3h59m
default nginx-86c57db685-ms8g7 1/1 Running 0 6h
default nginx-86c57db685-qfl2f 1/1 Running 0 3h59m
default nginx-86c57db685-xwxzv 1/1 Running 0 4h7m
kube-system calico-kube-controllers-77c84fb6b6-nggl5 1/1 Running 0 6h12m
kube-system calico-node-4xx8g 1/1 Running 0 6h12m
kube-system calico-node-zfmtt 1/1 Running 0 6h12m
kube-system coredns-59fb8d54d6-pq2bt 1/1 Running 0 6h30m测试验证 现在去访问这个VIP,也就是间接到访问到k8s的api,这个token也就是bootstrap的token
[root@k8s-node1 ~]# curl -k --header "Authorization: Bearer 79ed30201a4d72d11ce020c2efbd721e" https://192.168.30.20:6443/version
{
"major": "1",
"minor": "16",
"gitVersion": "v1.16.0",
"gitCommit": "2bd9643cee5b3b3a5ecbd3af49d09018f0773c77",
"gitTreeState": "clean",
"buildDate": "2019-09-18T14:27:17Z",
"goVersion": "go1.12.9",
"compiler": "gc",
"platform": "linux/amd64"