一、什么是推荐系统
1、长尾理论+推荐系统
- 长尾理论对于电商来说,核心关注点是商品,而非用户(但是会同时对用户产生影响)
- 理论解释:以正态分布为例,卖的比较好的爆款,在正态分布的曲线中,是处于突起的位置,而其他一些商品,则处在曲线两侧比较平缓的位置,当商品的数量足够多,那较为平缓的两侧曲线就会很长,这一段长而平缓的曲线,就是需要挖掘价值的位置所在。
- 推荐的作用就是将长尾的价值尽可能的挖掘出来。
- 长尾理论+推荐系统 挑战了传统的二八原则。
2、推荐系统实验方法
(1、离线实验
-通过日志获得数据集
- 整理数据集;
- 在训练集上训练用户兴趣模型,在测试集上进行预测;
- 通过事先定义的离线指标评测算法在测试集上的预测结果
这个是主要是策略的实现,想怎么推荐,用什么策略,在这一步跟算法工程师一起搞定。在离线证明算法的有良心这块,暂时
存疑,不懂怎么实现。
(2、线上测试
- 将线上的部分流量切给已经实现的策略,对比分析,评测实验结果。
- 评测的指标主要是推荐和排序对转化率的转化率影响
二、利用用户行为数据
1、用户行为
(1、显性反馈
- 类似于评分这种,用户能直接表达喜好的反馈。
- 有正负反馈
(2、隐性反馈
- 通常是用户浏览、停留、跳转等数据,不太能明确的表达出用户的喜好。
- 只有正反馈,没有负反馈
- 数据量较大
2、用户行为分析算法
基于用户行为的推荐算法一般称为协同过滤算法,粗浅理解,就是用户本身、其他用户、网站主体,几个角色一起参与,综合测算你需要什么。
(1、协同过滤算法业界用的最广泛的:基于邻域的算法,包含下面两种类型
- 基于用户的协同过滤算法: 给用户推荐和他兴趣相似的其他用户喜欢的物品。(更社会化,小型群体)
- 基于物品的协同过滤算法: 给用户推荐和他之前喜欢的物品相似的物品。(更个性化,继承用户的历史兴趣)这种算法需要引入内容,才能提高推荐准确率。
在电商方面,个人觉得基于语义的算法如果技术很成熟的话,是可以作为一个推荐的标签依据的,评论更能表达用户喜好,这是用户说;现在基本拿来做人货匹配的商品的标签,都是商家说。
三、推荐系统冷启动问题
1、冷启动问题主要分三类
- 用户冷启动
主要是在新用户的推荐上,系统没有用户行为信息,无法做出推荐
- 物品冷启动
物品冷启动主要解决如何将新的物品推荐给可能对它感兴趣的用户这一问题。
- 系统冷启动
系统冷启动主要解决如何在一个新开发的网站上(还没有用户,也没有用户行为,只有一些物品的信息)设计个性化推荐系统,从而在网站刚发布时就让用户体验到个性化推荐服务这一问题。
2、冷启动大致解决方案
在系统冷启动的时候,大多数只能提供非个性化推荐,或者依据尽可能可以拿到的用户信息来做决策,并提供可以挖掘用户偏好的手段。
- 提供非个性化推荐:在没有个性化数据依托的情况下,给新用户展示热度最高的商品。
- 如有注册信息,可利用用户的注册信息做粗粒度的推荐
- 如有社交账号联登,可以获得其社交信息,从而推荐好友喜欢的相似物品。
- 在用户注册时,对一些物品进行反馈(soul、知乎、青芒杂志等用注册反馈收集了比较多的信息,电商只能简单收集,不宜太多),从而初始化一些简单的推荐
ps:电商还有一个情况是用户未登陆,一是直接做一些非个性化的热榜,二是可以根据设备号、cookie信心做一些简单的根据历史浏览的推荐。
(1、利用用户注册信息的冷启动方案
- 人口统计学内容:包括用户的年龄,性别、居住地等,这些信息可以拿来做一些粗粒度的推荐,过滤不符合用户的商品。书中做了根据人口统计学内容的粗推荐和完全随机推荐的对照实验,不过随机推荐完全随机,没有考虑到任何因素,效率和影响肯定是最低的,两者的对比并不能说明什么。如果想要新用户立即转化,在最开始的推荐中,可以考虑加入热度因子,并考虑到多样性,这样能保证用户大概率会对网站感兴趣,至于推荐中的长尾经济,等到新用户转化成老用户,在进行冷门且合适的物品推荐,可以提升长尾的转化,可以提升用户的忠诚度和保证网站的差异性。
- 这里有个比较聪明的点是,收集到的新用户的人口统计学内容,可能和部分老用户类似甚至是相同,这时候可以将其归为一类,给新用户推荐同类中老用户喜欢的商品,这样也能提升准确率,不过为了新用户能迅速转化,还是需要考虑热度和多样性因素,老用户则不必。
(2、选择合适的物品启动用户的兴趣
- 与知乎、soul提供各种测试题和选项一样,就是一个对平台进行反馈的机制,不是很适用与电商,影响用户体验,每多增加一步,就会增加流失的风险。
(3、利用物品的内容信息
- 物品冷启动需要解决的问题是如何将新加入的物品推荐给对它感兴趣的用户,主要是一些时效性比较高的物品,类似于新闻文章之类,在电商平台中,商品一般都有属性信息,只要采集到这些基础信息,再将商品归类,然后推荐,就没有什么大问题。
- 物品冷启动主要是用到itemCF算法,这个算法主要问题是计算周期长(发展了这么多年,应该有一些缩短了吧),电商领域itemCF的周期还算可以接受,但在新闻杂志这些行业,就不太能接受。
四、用户标签
标签最大的好处是无层次化结构,只是用来描述信息的关键词,用于表现物品的属性。
同过UGC,一方面,可以洞悉用户的兴趣喜好,一方面,可以反补物品描述维度的缺失。
1、想要了解标签,需要先提两个点
(1、一是基于已有的标签,怎么给用户推荐商品
(2、二是在用户打标签的时候,怎么推荐标签。电商里就更加隐晦了,不能让电影一样,让用户进行评分之类,只能
从用户的评论或者行为中提取标签
。
2、用户为什么进行标注(电商涉及比较少主动明显的来自于用户的手动标注)
(1、物品基本属性
- 可以把属性拆成标签,这个是本来固有的,像上传文章要选择分类一样,我司是自己有供应链,所以基础属性这块,问题应该不大,有完善的机制去规范属性获取和补充。
- 这个标注可以在商品端更好的管理商品
(2、给广大用户用的标签
- 这个标签主要致力于,用户能更加方便的找到商品,也为个性推荐做铺垫。
(3、传达信息类的标签
- 譬如地点、时间
3、基于标签的推荐系统
(1、用户、标签、物品
- 用户与物品之间,主要是通过标签来进行联系,思路为:用户对物品打上某个标签,其他用户对该物品也打上某个标签,通过计算两者的关系,算出用户的兴趣权重,再加上热度惩罚,保证推荐的新颖度,这样推荐出来的物品,准确率和召回率都比较高
2、标签的清理
- 把不合适作为推荐理由的标签清理掉,或者做正负划分(比较难实现,很难反应用户的负兴趣,即使能够反映,再加上负标签因素,会是整个推荐计算复杂度大大增加。)
- 主要的清理方法
a、去除词频很高的停止词
b、去除因词根不同造成的同义词
c、去除因分隔符造成的同义词
4、基于图的标签计算法
- 创建三个顶点,用户、标签、物品,用户对物品打标签的动作,可以抽象成三条边的连结。
- 用户和物品的线主要是增加权重,毕竟是直接联系的。
五、上下文(环境)信息
时间、地点、季候等,都属于上下文(环境)信息,一个人性化的足够全面男的推荐,应该考虑到这些方面。
1、时间效应
- 用户:在不同的年龄段不同的人生时期,需求是不一样的
- 物品:物品也有生命周期,盛衰跟大环境有关。
- 季节:不同的季节用户的需求不同。还可以加入节日效应因素。
尽量平衡考虑短期和长期,即要让推荐列表反应出用户近期行为所体现的兴趣变化,又不能让推荐列表完全受用户近期行为的影响,要有一种延续性性,大大拉长推荐功能生命周期。
2、时变个性化--基于图的推荐
- 主要是在原来的用户-物品二分图中,用户侧加入了用户&时间定点,物品侧增加物品&时间顶点
- 加入时间属性后,能反映出时间的作用。
- 拓展:在标签中,能否根据时间段的不同,应用不同的标签,譬如用户在上学,到高中时,标签为【高中】,到大学后,【高中】标签自动替换为【大学】。至于标签的替换,可以抓取隐形数据进行推测,譬如根据消费的增长计算,辅以时间计算校正。
3、地点上下文信息
考虑了地点的算法对出口电商很重要,尤其是站点遍布各大国家的电商公司,可以将推荐本地化,提升推荐结果的准确率。
(1、兴趣本地化
- 不同地方的用户兴趣存在着很大的差别。不同国家和地区用户的兴趣存在着一定的差异性。对于不同国家的同兴趣人群做聚类,比在全球范围内,对所有的用户做聚类要准确的多,颗粒度也更细。
(2、特质本地化
- 在全球范围内,可能一部分地区阴雨绵绵,一部分地区青光大日,另外一些区域冰雪笼罩,这样根据地域特征,也可以做出相对适宜的区分。
六、推荐系统实例
1、外围架构
结合书本和电商架构,外围的模型大概是这样,不过难点在于首页或一些有丰富资源位的页面,这些资源位的展示与否与展示顺序怎么确定,几种方案都觉得不能满足,
一是系统的作用可能导致真实看起来很怪异,算法考虑不到视觉的因素。
二是不满足运营需求,手动调控比较麻烦,因为会生成多套界面。预览和人工调控会比较麻烦。

2、推荐系统架构
主要是关于人和货物怎么联系起来的问题研究

根据上图,推荐系统被拆分为两个部分:
一是如何生成特征(人和物品)
这一块主要是用户画像和商品画像基础属性的完善和补充,并且有信息数据采集功能做支持,在用户不断操作的同时,对画像进行反补,不断完善。
二是如何对特征进行匹配
这一块主要涉及推荐的排序以及策略。
(1、用户的特征
前面也说过很多,这里总结一下
- 人口统计学特征
用户的个人信息,地址年龄等。
- 用户行为特征
用户的操作反馈给平台的数据,包括收藏、浏览、点击查看、不同时间线的行为偏好等。
- 用户的话题特征(电商可以说主题特征)
用户喜欢的专题、主题类型等。
(2、系统设计
- 如果要考虑比较多得因素。放在一个系统里面会比较复杂,耦合度会很高
- 因此可以设计成多个推荐引擎,每个推荐引擎负责一类特征和一种任务
- 可以方便得控制各推荐引擎,组合删除和实验等,都比较方便
- 多个推荐引擎还可以实现引擎级别的用户反馈,每一个引擎都可以有自己的推荐策略。
3、推荐引擎的架构(基于物品)
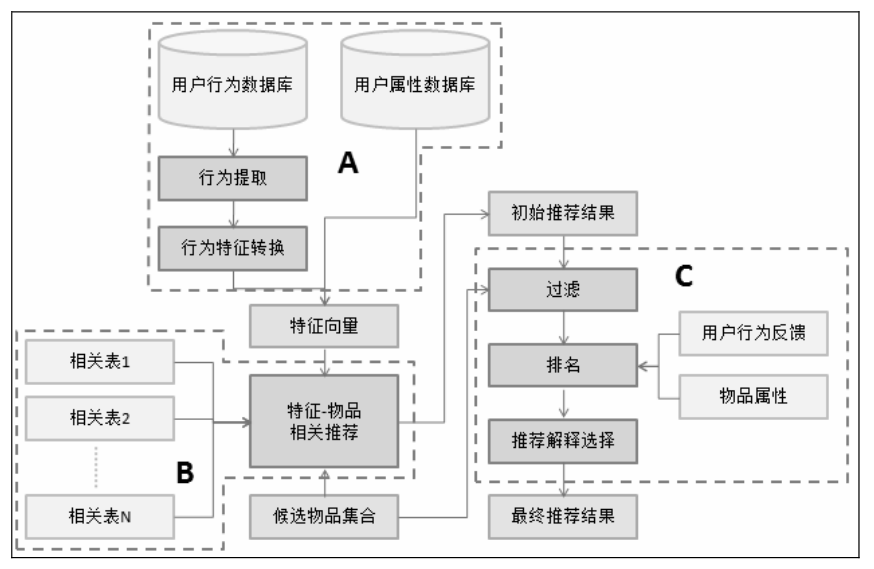
架构主要分为三部分:
一是拿数据并生成用户特征向量。
二是生成初始推荐。
三是细化和优化推荐,并生成最终推荐结果。
(1、用户特征向量
- 统计学特征:无需特别处理,一般拿来稍作处理就可以使用,属于比较确定的用户属性。
- 用户行为种类:包括收藏、评论、购买、分享、打标签、搜索关键词、加入购物车等,这个都是算法的依据,这些属性特征需要进行权重处理,反映出每一个操作对用户兴趣的意义。
- 用户行为时间:主要是用户操作的时间的远近对算法权重的影响,一般而言,越近的,影响越大,可以反应用户当下的兴趣。
- 系统时间&地域特征:这也是比较重要的,数据都是可以获取的(通过当地系统时间和统计学特征中的地域空间信息),主要用于物品季节性、地域性气候性的调整。
- 用户行为的次数:用户对同一个(或者种类)物品的同一种行为次数越多,也反应了用户对物品的兴趣权重大小。
- 物品的热门程度:如果一个物品很热门的话,并不能代表用户的真实个性的兴趣爱好,有时候需要算法中可以打压一下热门物品所占的权重,个性推荐主要关注长尾中的商品。如果某用户总是买热门商品的话,说明该用户比较喜欢当下的热门,这个时候就没有必要再进行打压了,以转化率为主要目标。
(2、特征-物品关联
- 对于每个特征,关联N个商品,并存储在表中。
- 还可以使用协同过滤法,一个用户加购了商品A、B,一个用户加购了商品A,这时就可以计算,A和B是否有相关性。
(3、过滤模块
- 过滤用户已经产生行为的物品,保证结果的新颖性,但是前提是用户有途径去找到之前自己看过的物品,比如足迹和收藏功能,购物车自不必说,用户可以在购物车找到加购的物品。对于用户无法找到的,时间比较久一点的物品,倒是也不妨推荐出来。
- 候选集意外的商品,这个一般都不会去考虑。
- 考虑到用户体验和转化率,对质量差或者不合时宜的物品,进行降权打压。
(4、排名模块
- 新颖性排名:
对热门物品进行降权,主要是尽量发掘长尾中物品的作用,降低爆款的作用,这些爆款可以用到其他的地方,比如专题之类的,但是在个性推荐中,尽量打压其权重。
- 多样性:
多样性也是推荐系统的重要指标,主要是发掘用户更多的兴趣偏好,如果某个用户在你的 平台上只买了一个洗衣液,那平台只是推洗衣液相关的产品,就会比较单调,如果这个用户不是很主动,那平台就是去了挖掘用户更大价值的机会。
第一种实现多样性的方法是将推荐的物品分多类,每类挑选权重最高的商品推送,这样做虽然解决了多样性问题,但是同样也带来了麻烦,分类可能不准确,挑选分类的标准也不好确定,每个分类的个数 也不能确定,不是最优解。
第二种提高推荐结果多样性的方法是控制不同推荐结果的推荐理由出现的次数,简单来讲,就是对搜索引擎组中的某个引擎进行次数降权,如果上一次已经用过了,那么接下来就要降权处理。
- 时间多样性:
解决用户在平台没有产生新行为时,每天推荐结果可能相同的处理。
解决方案就是暂时存储用户看过的商品,隔天推荐时,对已推荐的商品进行降权处理。
(5、用户反馈
- 一是可以对用户的特征进行修正
- 二是通过分析用户之前和推荐结果的交互日志,预测用户会对什么样的推荐结果比较感兴趣(此处疑惑)
七、评分预测问题(基于用户的协同)
1、评分预测算法
(1、平均值
- 这个比较简单,取该物品所有评分的平均分作为预测分,每个用户都一样。
(2、用户平均值
- 取该用户对所有物品的评分的平均值,这个只能反应该用户的打分习惯,并不能预测喜好,单独用肯定误差较大,比较鸡肋。
(3、物品评分的平均值
- 该物品所有评分的平均值,大体反应了一个电影的好坏,并不能作为用户喜好。
(4、用户对物品分类的平均值
- 取该用户对未看过的该物品分类的平均分,很大程度上反应了用户对该类物品的兴趣
将这几种平均值交叉综合考虑,能比较接近的预测用户的评分。
2、基于邻域的计算方法
基于用户的邻域算法和基于物品的邻域算法都适用
- 基于用户的邻域算法主要考虑到和这个用户兴趣相似的其他用户,对这个物品的评分,有两个点需要考虑,一个是怎么算用户间的相似度,这个要考虑到兴趣和分数两个维度。一个是怎么算评分,这个主要考虑到该用户和相似用户评分的分差。
- 基于物品的邻域算法着眼于物品的邻域,根据该用户对相似物品的评分,来预测该物品的评分,不过这种情况在用户没用看过相似物品的情况下,预测准确度肯定会大大下降,需要一些容错措施来弥补损差。