垃圾收集算法
如何判断一个对象是不是垃圾
引用计数法
原理:在对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加一;当引用失效时,计数器值就减一;任何时刻计数器为零的对象就是不可能再被使用的。
缺点:很难解决对象之间相互循环引用的问题
package test33;
public class Person {
private Person person;
private int age;
public Person() {
}
public void setPerson(Person person) {
this.person = person;
}
@Override
public String toString() {
return "Person{" +
"person=" + person +
", age=" + age +
'}';
}
}
package test33;
public class Main {
public static void main(String[] args) {
Person pa = new Person();
Person pb = new Person();
pa.setPerson(pb);
pb.setPerson(pa);
pa = null;
pb = null;
System.gc();
System.out.println(pa);
System.out.println(pb);
}
}
该案例可证明hotspot虚拟机没有采用引用计数法判断对象是否是垃圾(可以被回收)
可达性分析算法
以被称为“GC Roots”的根对象作为起始节点集,从这些节点开始,根据引用关系向下搜索,搜索过程所走过的路径称为“引用链”(Reference Chain),如果某个对象到GCRoots间没有任何引用链相连,或者用图论的话来说就是从GC Roots到这个对象不可达时,则证明此对象是不可能再被使用的。
哪些对象可以作为GC Roots
在Java技术体系里面,固定可作为GC Roots的对象包括以下几种:
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,譬如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等。
- 在方法区中类静态属性引用的对象,譬如Java类的引用类型静态变量。
- 在方法区中常量引用的对象,譬如字符串常量池(String Table)里的引用。·
- 在本地方法栈中JNI(即通常所说的Native方法)引用的对象。
- Java虚拟机内部的引用,如基本数据类型对应的Class对象,一些常驻的异常对象(比如NullPointExcepiton、OutOfMemoryError)等,还有系统类加载器。
- 所有被同步锁(synchronized关键字)持有的对象。
- 反映Java虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
Java中的对象引用分类
无论是通过引用计数算法判断对象的引用数量,还是通过可达性分析算法判断对象是否引用链可达,判定**对象是否存活都和“引用”**离不开关系。
关于对象的引用有以下四种类型

判定对象是否可真正回收的细节
存在两次标记
第一次:该对象没有与GC Roots相连接的引用链,进行标记
第二次:执行该对象的finalize()方法时,该对象是否与引用链上的对象还存在联系。进行标记
,
案例如下:
package test34;
public class FinalizeEscapeGC {
public static FinalizeEscapeGC SAVE_HOOK = null;
public void isAlive(){
System.out.println("我还活着");
}
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize method executed!");
FinalizeEscapeGC.SAVE_HOOK = this;
}
}
package test34;
public class Main {
public static void main(String[] args) throws InterruptedException {
FinalizeEscapeGC.SAVE_HOOK = new FinalizeEscapeGC();
FinalizeEscapeGC.SAVE_HOOK = null;
System.gc();
//因为Finalizer方法优先级较低,暂停等待
Thread.sleep(500);
if(FinalizeEscapeGC.SAVE_HOOK!=null){
FinalizeEscapeGC.SAVE_HOOK.isAlive();
}else{
System.out.println("i am dead");
}
System.out.println("=============");
FinalizeEscapeGC.SAVE_HOOK = null;
System.gc();
Thread.sleep(500);
if(FinalizeEscapeGC.SAVE_HOOK!=null){
FinalizeEscapeGC.SAVE_HOOK.isAlive();
}else{
System.out.println("i am dead");
}
}
}
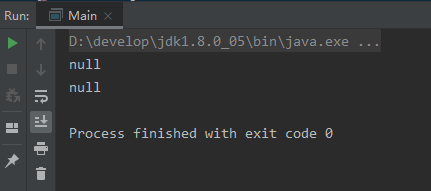
运行结果如下:

上图运行结果中说明了一个问题:任何一个对象的finalize()方法都只会被系统自动调用一次,如果对象面临下一次回收,它的finalize()方法不会被再次执行,因此第二段代码的自救行动失败了
垃圾收集算法
分代收集理论(重要)
收集器应该将Java堆划分出不同的区域,然后将回收对象依据其年龄(年龄即对象熬过垃圾收集过程的次数)分配到不同的区域之中存储。显而易见,如果一个区域中大多数对象都是朝生夕灭,难以熬过垃圾收集过程的话,那么把它们集中放在一起,每次回收时只关注如何保留少量存活而不是去标记那些大量将要被回收的对象,就能以较低代价回收到大量的空间;如果剩下的都是难以消亡的对象,那把它们集中放在一块,虚拟机便可以使用较低的频率来回收这个区域,这就同时兼顾了垃圾收集的时间开销和内存的空间有效利用。
基于分代收集理论,HotSpot虚拟机将java堆划分为新生代(Young Generation)和老年代(Old Generation)两个区域。由于对象可能会产生跨代引用的问题。解决办法是在新生代上建立一个全局的数据结构(该结构被称为“记忆集”,Remembered Set),这个结构把老年代划分成若干小块,标识出老年代的哪一块内存会存在跨代引用。此后当发生Minor GC时,只有包含了跨代引用的小块内存里的对象才会被加入到GC Roots进行扫描。虽然这种方法需要在对象改变引用关系(如将自己或者某个属性赋值)时维护记录数据的正确性,会增加一些运行时的开销,但比起收集时扫描整个老年代来说仍然是划算的。
基于分代收集理论,在Java堆划分出不同的区域之后,垃圾收集器才可以每次只回收其中某一个或者某些部分的区域——因而才有了“Minor GC”“Major GC”“Full GC”这样的回收类型的划分;也才能够针对不同的区域安排与里面存储对象存亡特征相匹配的垃圾收集算法——因而发展出了“标记-复制算法”“标记-清除算法”“标记-整理算法”等针对性的垃圾收集算法。
标记-清除算法
算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后,统一回收掉所有被标记的对象,也可以反过来,标记存活的对象,统一回收所有未被标记的对象。标记过程就是对象是否属于垃圾的判定过程。
缺点:
- 执行效率不稳定,如果Java堆中包含大量对象,而且其中大部分是需要被回收的,这时必须进行大量标记和清除的动作,导致标记和清除两个过程的执行效率都随对象数量增长而降低;
- 内存空间的碎片化问题,标记、清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致当以后在程序运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
标记-复制算法(复制算法,不适用老年代)
“半区复制”(Semispace Copying)的垃圾收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
优点:
算法需要复制的就是占少数的存活对象,而且每次都是针对整个半区进行内存回收,分配内存时也就不用考虑有空间碎片的复杂情况,只要移动堆顶指针,按顺序分配即可。这样实现简单,运行高效。
缺点:
1.将会产生大量的内存间复制的开销。
2.将可用内存缩小为了原来的一半,空间浪费比较严重。
优化的半区复制分代策略(Appel式回收)
把新生代分为一块较大的Eden空间和两块较小的Survivor空间,每次分配内存只使用Eden和其中一块Survivor。发生垃圾搜集时,将Eden和Survivor中仍然存活的对象一次性复制到另外一块Survivor空间上,然后直接清理掉Eden和已用过的那块Survivor空间。
HotSpot对Appel式回收的实现
HotSpot虚拟机默认Eden和Survivor的大小比例是8∶1,也即每次新生代中可用内存空间为整个新生代容量的90%(Eden的80%加上一个Survivor的10%),只有一个Survivor空间,即10%的新生代是会被“浪费”的。
如果每次回收有多于10%的对象存活,因此Appel式回收还有一个安全设计,当Survivor空间不足以容纳一次Minor GC之后存活的对象时,就需要依赖其他内存区域(实际上大多就是老年代)进行分配担保(Handle Promotion)。这个是此算法不适用老年代的原因。
标记-整理算法
其中的标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向内存空间一端移动,然后直接清理掉边界以外的内存
缺点:
1.如果移动存活对象,尤其是在老年代这种每次回收都有大量对象存活区域,移动存活对象并更新所有引用这些对象的地方将会是一种极为负重的操作,而且这种对象移动操作必须全程暂停用户应用程序才能进行。
吞吐量
吞吐量的实质是赋值器(Mutator,可以理解为使用垃圾收集的用户程序,用户程序或用户线程”代替)与收集器的效率总和。
移动则内存回收时会更复杂,不移动则内存分配时会更复杂。从垃圾收集的停顿时间来看,不移动对象停顿时间会更短,甚至可以不需要停顿,但是从整个程序的吞吐量来看,移动对象会更划算。
不移动对象会使得收集器的效率提升一些,但因内存分配和访问相比垃圾收集频率要高得多,这部分的耗时增加,总吞吐量仍然是下降的。HotSpot虚拟机里面关注吞吐量的Parallel Old收集器是基于标记-整理算法的,而关注延迟的CMS收集器则是基于标记-清除算法的。
