一、判断对象存活、GC Roots、引用
- 引用计数算法
- 可达性分析算法(从GC Roots出发,搜索关联结点,回收不可达对象)
GC Roots包含的对象
- 虚拟机栈的局部变量表中refenrence引用的对象
- 本地方法栈中JNI引用的对象
- 方法区中类变量引用的对象
- 方法区中常量引用的对象
Java中的引用类型
- 强引用:强引用引用的对象不可回收
- 软引用:软引用引用的对象在内存溢出发生之前被回收
- 弱引用:弱引用引用的对象只能存活到下一次GC发生之前
- 虚引用:只是在被垃圾回收时收到一个通知
二、垃圾回收算法
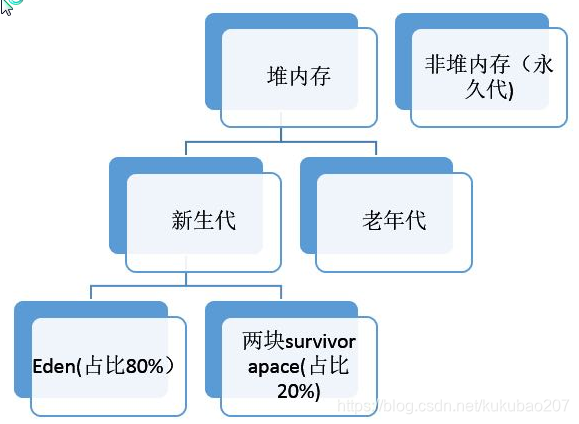
描述算法之前,先看一看堆内存的分代情况。
2.1 标记-清除算法
步骤
- 标记已经死亡的对象
- 清除这些对象的内存
缺点
- 效率不高
- 内存碎片
2.2 复制算法
步骤
- 把活着的对象复制到另一块内存上
- 把当前这块内存区域的对象全部清除。
缺点
- 需要另一块内存,“浪费”了一部分的内存资源
- 如果所有对象均存活,则To Survivor区域存不下,需要其他内存来担保。
一般是分成一块Eden区域,两块Survivor区域,Eden:80%,Survivor:10%,这个比例可以通过-XX:SurvivorRatio来进行调整。
3)-XX:SurvivorRatio
用于设置Eden和其中一个Survivor的比值,默认比例为8(Eden):1(一个survivor),这个值也比较重要。
例如:-XX:SurvivorRatio=4:两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6。
例如:-XX:SurvivorRatio=8,两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10。
垃圾回收时,把Eden区域和From Survivor区域中活着的对象转移到To Survivor上,然后清除Eden和From Survivor中的对象。
2.3 标记-整理算法
步骤
- 标记已经死亡的对象,让存活的对象向一端移动
- 直接清理掉端边界以外的内存。
2.4 分代算法
在新生代用复制算法,在老年代用标记-清除或标记-整理算法。
三、垃圾收集器
3.1 Serial收集器
特点
- 单线程收集器,使用一个CPU或者一条收集线程去GC
- 在GC时暂停其他所有工作线程(Stop The World)。
使用场景:Clien模式下的虚拟机
3.2 ParNew收集器
特点
- Serial收集器的多线程版本
- 同样需要Stop The World
- 除了Serial外能用CMS组合的唯一新生代垃圾收集器。
使用场景:Server模式下的虚拟机(目前只有它能与CMS收集器配合工作)、多CPU
3.3 Parallel Scavenge收集器
特点:
- 他不关注缩短用户线程的停顿时间,而是关注系统有一个更高的吞吐量(用户代码时间/(GC时间+用户代码时间)),也叫“吞吐量优先”收集器
- 具备自适应调节策略:通过设置MaxGCPauseMills或GCTimeRatio参数给虚拟机设立一个优化目标,平衡停顿时间和吞吐量。
使用场景:后台运算量高的,对CPU能有较好的利用率。不适合于用户交互的程序。
3.4 Serial Old收集器
特点:Serial收集器的老年代版本,使用“标记–整理”算法
使用场景:
- 主要是Client模式下的虚拟机使用
- 如果是Server模式下,可以与Parallel Scavenge搭配使用
- 如果是Server模式下,在CMS收集器并发收集发生Concurrent Mode Failure时使用
3.5 Parallel Old收集器
特点:Parallel Scavenge收集器的老年代版本,使用多线程和“标记–整理”算法。
使用场景:注重吞吐量以及CPU资源敏感的场合,用Parallel Scavenge + Parallel Old。
3.6 CMS收集器
步骤
- 初始标记(需要STW)
- 并发标记(不需要STW)
- 重新标记(需要STW)
- 并发清除(不需要STW)
特点
- 并发收集:并发标记和并发清除过程收集器线程都可以与用户线程一起工作
- 低停顿:服务器响应速度较快,系统停顿时间短,用户体验好。
- 使用标记–清除算法
缺点
- GC线程占用CPU时间片,应用程序变慢,总吞吐量降低。
- 无法处理浮动垃圾,由于并发清除阶段,用户线程还有垃圾产生,这部分标记后,无法在当次清除,只能下次GC清除。
- 需要预留内存供并发收集的程序运作使用
- 内存碎片较多,不利于大对象分配,容易导致Full GC。
使用场景
重视服务器响应速度、希望系统停顿时间短的需求。
3.7 G1收集器
过程
- 初始标记:标记一下GC Roots直接关联到的对象(需要STW)
- 并发标记:从GC Roots开始对堆做可达性分析,找出存活对象(不需要STW)
- 重新标记:修正并发阶段用户线程运作而导致标记变动的那部分标记。(需要STW)
- 筛选回收:根据回收的价值和成本(用户期望的时间)进行排序,制定策略。(需要STW)
特点
- 并发与并行,低停顿
- 分代收集(不需要其他收集器配合)
- 空间整合(标记–整理),无内存碎片
- 可预测的停顿,建立可预测的停顿时间模型
G1跟踪各个Region里面的垃圾堆积的价值大小,在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的Region,这是典型的贪心算法。
Region不是孤立的,一个Region中的对象可能引用其他Region中的对象,G1使用Remember Set来避免全堆扫描,每一个Region都有一个对应的Remember Set。