数据加载和数据预处理:
(1)利用Pandas库进行数据加载和预处理:处理问题数据,日期格式解析,NaN值的处理,分组和聚类,排序和索引,文本数据的编码,词频统计等;
(2)利用Numpy库进行数据处理:数组的创建,矩阵运算,数组切片,堆叠等。
数据分析:
(1)数据的探索性分析;
(2)高维数据的维数约减;
(3)异常数据的检测和处理;
(4)算法验证和参数优化及特征选择。
机器学习:
(1)基本的机器学习方法;
(2)机器学习方法的组合;
(3)大数据的处理和深度学习。
数据可视化:
(1)Matplotlib画图;
(2)交互式可视化;
(3)高级数据学习表示。
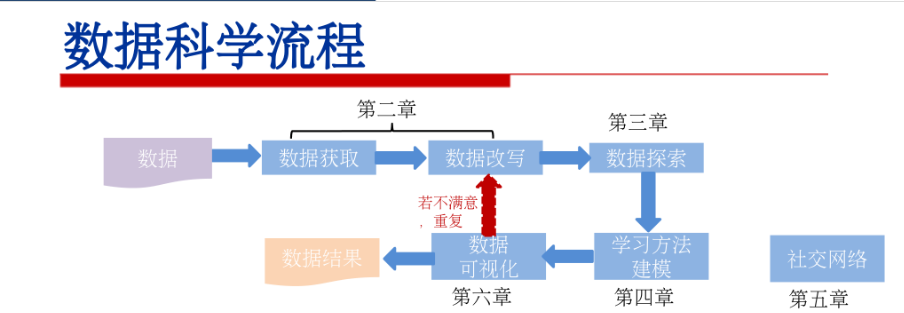
EDA简介
探索性数据分析(Exploratory Data Analysis)
EDA主要工作:对数据进行清洗,对数据进行描述(描述统计量,图表),查看数据的分布,比较数据之间的关系,培养对数据的直觉,对数据进行总结等。
“探索性”指分析者对待解问题的理解会随着研究的深入不断变化。
基本步骤:
- A. 检查数据
- B. 使用表述统计量和图表对数据进行描述
- C. 考察变量之间的关系
- D. 检验特征分布
- E. 其他
A 检查数据
-是否有缺失值?
-是否有异样值?
-是否有重复值?
-样本是否均衡?
-是否需要抽样?
-变量是否需要转换?
-是否需要增加系的特征?
例:
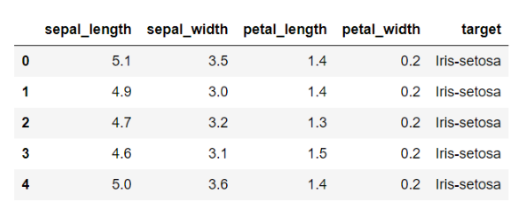
数据类型:数值型(包括整数,浮点数),类别型(字符串等),文本型,时间序列等。
注:主要考虑数值型(定量数据)和类别型(定性数据);数值型又可以分为连续型和离散型。
B 数据描述
describe() 生成描述性统计数据:总结数据分布的集中趋势,分散和形状,不包括NaN值。
help(pandas.DataFrame.describe) 查看关于Pandas数据框的describe()函数的使用说明。
例:
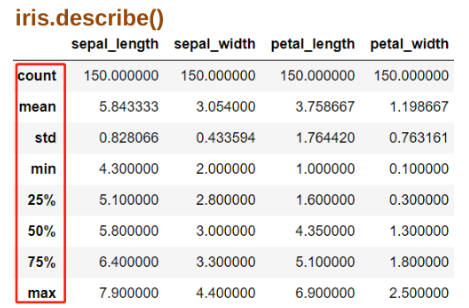
利用描述性统计得到一个频数分布表:.describe()
count 观测值的数量=shape[0]
mean 平均值
std 标准差
min 最小值
25% 1/4中位数
50% 1/2中位数
75% 3/4中位数
max 最大值
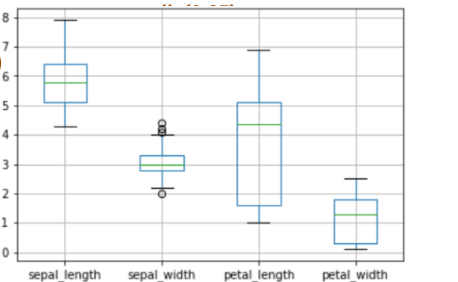
利用箱线图将频数分布表可视化:.boxplot()
boxes = iris.boxplot(return_type='axes')
特征去重复统计:.unique()
去除一维数组或列表中重复的元素,并按元素由大到小返回一个新的无元素重复的元组或者列表。
C 特征相关性
共生矩阵/交叉表 crosstab() :用于统计分组频率的特殊透视表。

发现:长度,宽度与特征值的比较几乎同时发生,即要么同时大于均值,要么同时小于均值。
假设特征petal_length,petal_width相关,对其进行图像化显示

说明:
kind 种类:scatter 散点图
x X轴:petal_width
y Y轴:petal_length
c 颜色:blue
edgecolors 边缘颜色:white
结果:

补充kind:str
'line' 折线图
'bar' 条形图
'barth' 横向条形图
'hist' 柱状图
'box' 箱线图
'kde' 对柱状图形添加Kernel概率密度线
'density' same as 'kde'
'area' 不了解此图
'pie' 饼图
'scatter' 散点图,需要传入columns方向的索引
'hexbin' 不了解此图
D 特征分布
使用直方图近似表示特征的概率分布:
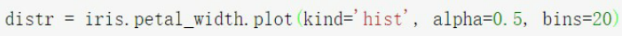
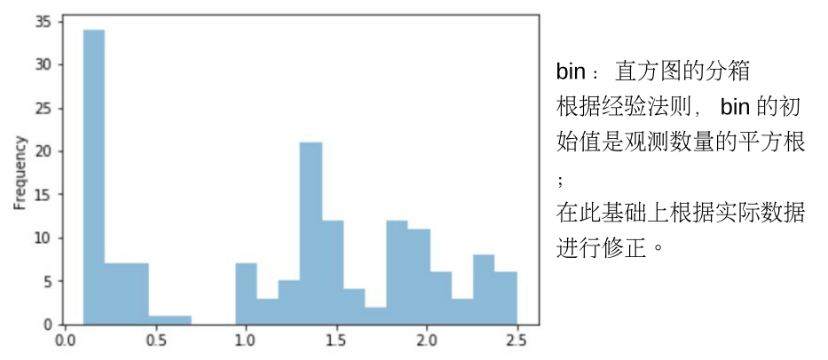
EDA总结:
- pandas读取数据集,显示前5行确认是否加载正确
必要时对列名重命名
- 查看数据整体情况
行列数 data.shape
数据类型 data.dtypes
同时查看这两项 data.info()
查看连续变量的描述统计量 data.describe()
- 处理缺失值,异常值,重复值问题
各列分别有多少个缺失值 data.apply(lambda x:sum(x.isnull()),axis=0)
各行分别有多少个缺失值 data.apply(lambda x:sum(x.isnull()),axis=1)
总共有多少行有缺失值 len(data.apply(lambda x:sum(x.isnull()),axis=1).nonzero()[0])
删除重复值 data.drop_duplicates(0
- 分析特征之间相关性
- 检验数据分布