1. 前言
对于从事大数据开发,数据挖掘或者机器学习领域的同学来说,当面对陌生的海量数据时,往往最先做的不是急着去开发功能,而是去认识数据和清洗数据。这有可能会占据着整个开发流程40%左右的精力和时间。
2.数据认识和清洗的总体要求
- 理解问题 :我们将分析每一个变量,然后较全面地理解它的含义,以及对我们问题的重要性。
- 单变量研究:我们将重点关注因变量(SalePrice),并且对这个变量做一些了解。
- 多变量研究:我们尝试理解因变量和自变量之间的关系。
- 基础清洗: 我们将清洗数据并且处理缺失值,离群点数据和分类型变量。
- 测试验证: 我们将通过多变量技术来检测数据是否符合目标需求。
3. 具体过程
这里以kaggle的预测房价比赛为例:
相关链接:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
导入相应的python包
#invite people for the Kaggle party
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy.stats import norm
from sklearn.preprocessing import StandardScaler
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline加载数据到内存
df_train = pd.read_csv('./data/train.csv')
df_test = pd.read_csv('./data/test.csv')我们期望从数据里分析出什么
为了理解我们的数据,我们可以去看每一个变量,并且理解他们的含义以及和与问题的相关性。我知道这一步将耗费大量的时间,但是将会给我们的数据集很大的支持。
为了在分析过程中有一些规范,我们可以创建一个excel文件,并且有如下列:
1. 变量:变量名字
2. 类型:变量的类型,在这里有两种主要的变量类型:数值型和分类型。数值型是指变量的值是数值。分类型是指变量类型是类型。
3. 片段:是变量的段。我们定义了三种可能的段:建筑,空间和位置。但我们说“建筑”,意思是说变量和建筑的物理特性有关系(比如:OverallQual);当我们说“空间”,意思是说和建筑的空间属性有关系(比如:TotalBsmtSF);当我们说“位置”,意思和建筑的地理位置有关系(你如:Neighborhood)。
4. 期望:我们的期望是变量对SalePrice的影响。我们可以用一个分类尺度来描述,分别是“High”,“Medium”和“Low”。
5. 结论:当对数据做了初步的分析之后,我们就可以对特征变量的重要性下一个结论。
备注:
“类型”和“片段”只是为了将来可能的参考,但是“期望”是非常重要的,因为它可以帮助我们建立第六感。为了完成这个表格,我们需要逐个逐个地去分析每一个特征,并且问自己:
你在买房子的时候 会考虑这个特征吗?
如果考虑,这个特征有多重要?
这个信息在其他特征那里有描述吗?例如:“LandContour”体现了物业的 平整度,那么我们真的需要知道”LandSlope”吗?
当以上这些工作做好了,我们就可以过滤表格,重点关注那些有高期望值的特征变量。然后我们就可以画出这些单个特征和SalePrice之间的关系图像。然后把结论填写上去作为对期望的补充更正。
我做完上述工作之后,发现以下几个特征比较重要:
1. OverallQual (这个特征我太喜欢,因为我不知道它是怎么计算得到的,一个有趣的事情是通过其他的特征来预测OverallQual的值)
2. YearBuilt
3. TotalBsmtSF
4. GrLivArea
就是最后我重点保留了两个“建筑”类特征(OveralQual和YearBuilt)和两个“空间”类特征(TotalBsmtSF和GrLivArea)。这可能有点出乎意料,因为它违背了房地产的咒语,所有重要的是“地点、地点和地点”。这种快速数据检查过程有可能对分类变量有点苛刻。例如,我预期“NigBuffID”变量更相关,但在数据检查之后,我最终排除了它。也许这与使用散点图而不是盒子图有关,这更适合于分类变量可视化。我们可视化数据的方式常常影响我们的结论。
然而,这次练习的要点是对我们的数据和预期行动进行一些思考,所以我认为我们实现了我们的目标.下面,就开始动手做起来把。
首要之事
“SalePrice”是我们追求的原因。这就像当我们要去参加一个晚会,我们总是有一个理由去那里。
df_train['SalePrice'].describe() count 1460.000000
mean 180921.195890
std 79442.502883
min 34900.000000
25% 129975.000000
50% 163000.000000
75% 214000.000000
max 755000.000000
Name: SalePrice, dtype: float64
结果非常好,最小的价格大于0,这非常好,你没有那种会破坏我模型的个人特质。
sns.distplot(df_train['SalePrice']);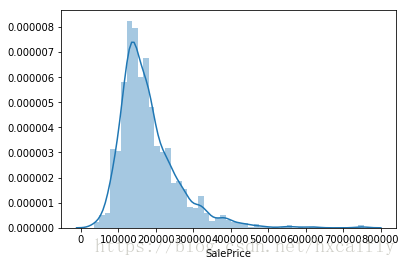
目标值呈现出:
1. 偏离正态分布
2. 有明显的正偏态
3. 表现出赤裸裸的样子
# 样本值的偏度(三阶矩)
print("Skewness: %f" % df_train['SalePrice'].skew())
# 样本值的峰度(四阶矩)
print("Kurtosis: %f" % df_train['SalePrice'].kurt()) Skewness: 1.882876
Kurtosis: 6.536282
SalePrice, 她的伙伴和她的兴趣
和数值型变量的关系
#散点图 grlivarea/saleprice
var = 'GrLivArea'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));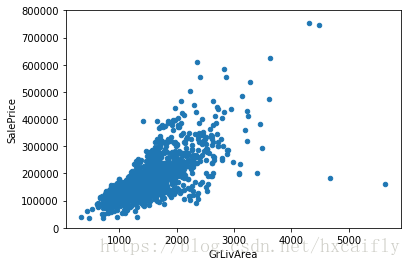
看得出“SalePrice”和“GrLiveArea”是老朋友。他们是一种线性关系。
#散点图 totalbsmtsf/saleprice
var = 'TotalBsmtSF'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));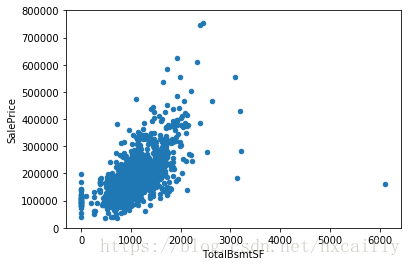
TotalBsmtSF也是SalePrice的老朋友。但这似乎是一种更情感的关系!一切都好,突然,在一个强大的线性(指数?)关系。此外,很明显,有时“TotalBsmtSF”本身关闭,并给予“SalePrice”零信用。
和分类变量的关系
#箱体图 OverallQual/SalePrice
var = 'OverallQual'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
f, ax = plt.subplots(figsize=(8, 6))
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000);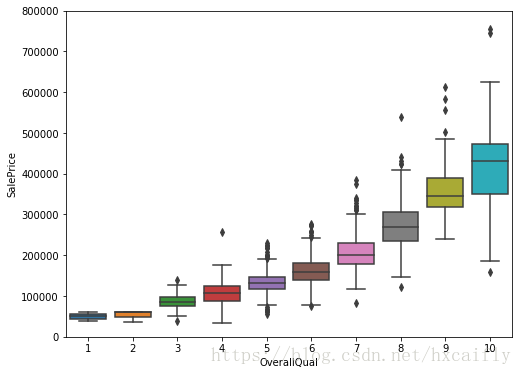
像喜欢漂亮的女孩一样,“SalePalk”喜欢“OverallQual”。
var = 'YearBuilt'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
f, ax = plt.subplots(figsize=(16, 8))
fig = sns.boxplot(x=var, y="SalePrice", data=data)
fig.axis(ymin=0, ymax=800000);
plt.xticks(rotation=90);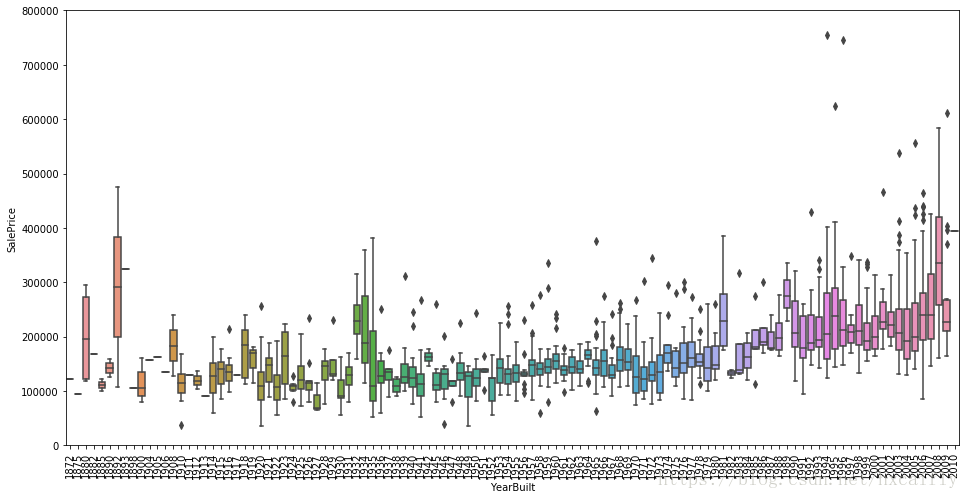
虽然这不是一个强烈的趋势,我会说“SalePrice”更倾向于花更多的钱在新的东西比旧的文物。
结论
我们可以总结出:
1. “GrLivArea”和“TotalBsmtSF”似乎和“SalePrice”呈线性关系。并且都是正相关关系。尤其是对于“TotalBsmtSF”,我们发现他和“SalePrice”的关系斜率要大。
2. “OverallQual”和“YearBuilt”和“SalePrice”也有关系。“OverallQual”和“SalePrice”的关系更加强烈点。
我们只是分析了四个变量,但是还有很多其他的我们应该分析。这里的诀窍似乎是选择正确的特征(特征选择),而不是它们之间复杂关系的定义(特征工程)。也就是说,我们把小麦和糠秕分开。
保持冷静,聪明地工作
直到现在,我们才跟随直觉,分析了我们认为重要的变量。尽管我们努力给我们的分析提供客观的特征,但是我们必须说我们的出发点是主观的。
作为一名工程师,我对这种方法感到不自在。我所有的教育都是培养一个有纪律的头脑,能够经受住主观性的风。这是有原因的。试着在结构工程中成为主观性,你会看到物理学使事情崩溃。会痛的。所以,让我们克服惯性,做一个客观的分析。从以下三个方面:
1. 关系矩阵
2. SalePrice 关系矩阵
3. 最相关特征之间的散点图。
关系矩阵
#correlation matrix
corrmat = df_train.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);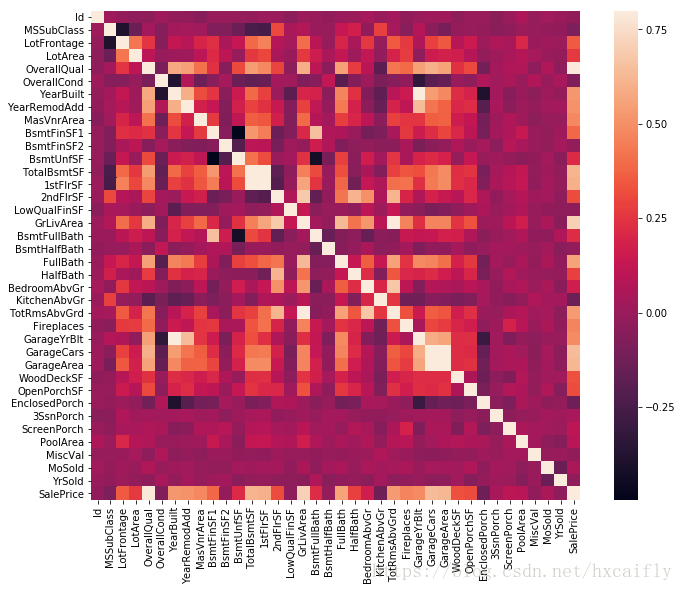
在我看来,这个热图是最好的方式来快速概述我们的“血浆汤”及其关系。
乍一看,有两个红色的方格吸引了我的注意力。第一个是“TotalBsmtSF”和“1stFlrSF”变量,第二个是“GarageX”变量。这两种情况都显示了这些变量之间的相关性是多么显著。实际上,这种相关性很强,可以指示多重共线性的情况。如果我们考虑这些变量,我们可以得出结论,它们给出几乎相同的信息,所以真的发生多重共线性。Heatmaps是很好的检测这种情况和在特征选择主导的问题,像我们一样,它们是一个必不可少的工具。
另一件引起我注意的是“SalePrice”的相关性。我们可以看到我们著名的“GrLivArea”,“TotalBsmtSF”和“OrthalQuall”,说“嗨!”但是我们也可以看到许多其他的变量。这就是我们接下来要做的。
‘SalePrice’关系矩阵
#saleprice correlation matrix
k = 10 #number of variables for heatmap
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(df_train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()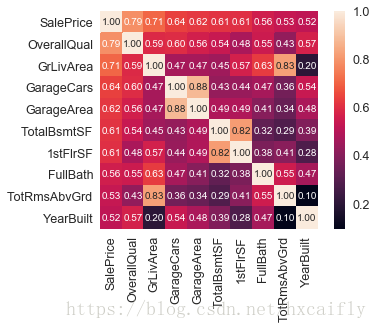
根据分析,我们可以知道如下几个特征是和SalePrice最相关的:
1. ‘OverallQual’,’GrLivArea’和‘TotalBsmtSF’与‘SalePrice’有强烈的关系。
2. ‘GarageCars’和‘GarageArea’与‘SalPrice’也有较强烈的关系。但是车库的面积是汽车进入车库的数量的直接决定因素。GarageCars和GarageArea就像孪生兄弟。你永远也分辨不出它们。因此,我们只需要分析这些变量中的一个。
3. ‘TotalBsmtSF’和‘1stFloor’也像是一对孪生兄弟,因此我们只保留“TotalBsmtSF”。
4. ‘TotRmsAbvGrd’ 和 ‘GrLivArea’也像是一对孪生兄弟。
5. 但是‘YearBuilt’看起来和‘SalePrice’的关系没有那么强烈,老实说,我很害怕想到“YearBuilt”,因为我开始觉得我们应该做一点时间序列分析来证明这是正确的。
SalePrice和相关变量之间的散点图
为你即将看到的东西做好准备。我必须承认,我第一次看到这些散布图时,我完全被风吹走了!这么短的空间里有这么多信息…真是太神奇了。再一次感谢seaborn。
#scatterplot
sns.set()
cols = ['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars', 'TotalBsmtSF', 'FullBath', 'YearBuilt']
sns.pairplot(df_train[cols], size = 2.5)
plt.show();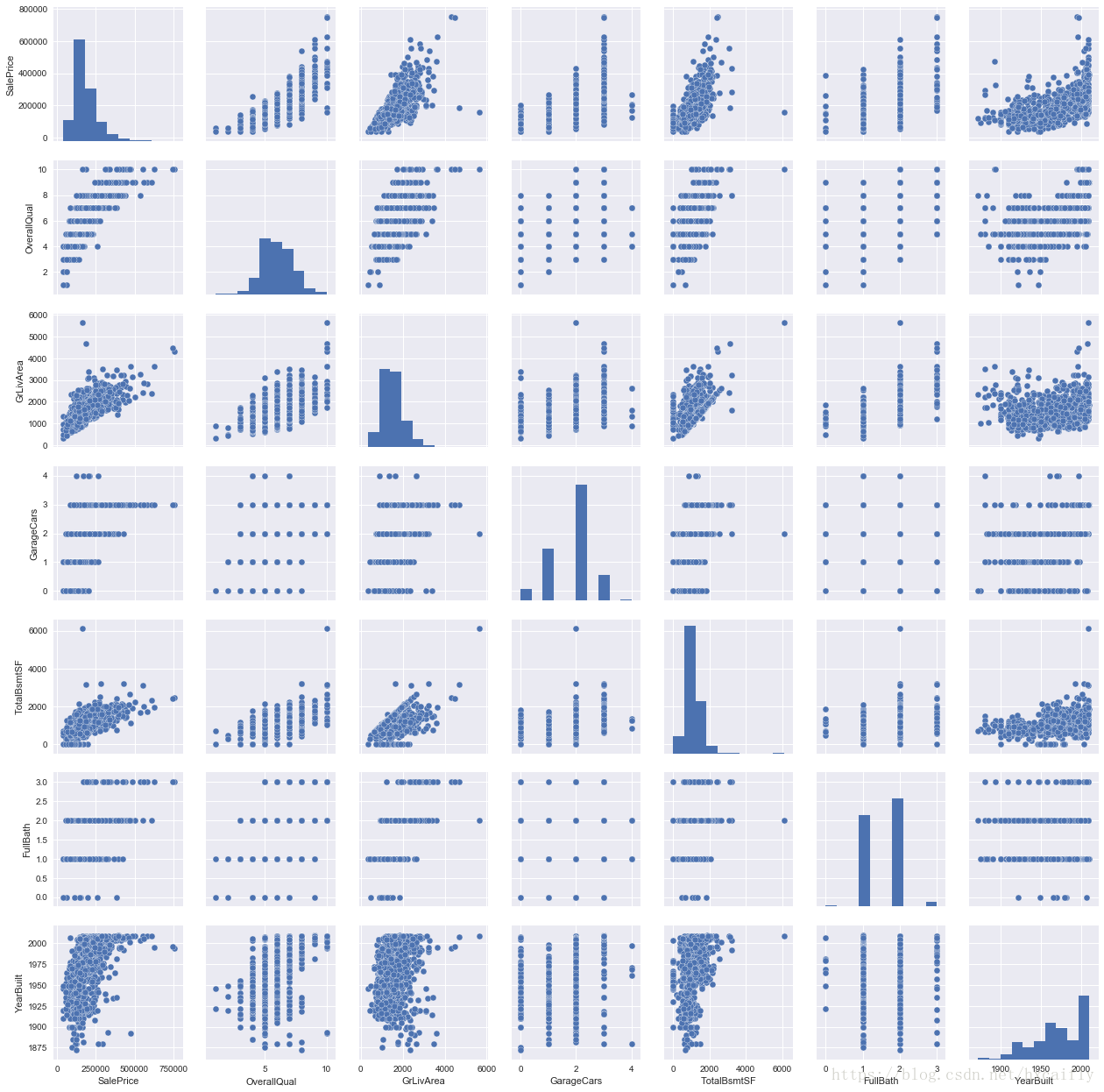
虽然我们已经知道了一些主要的数字,但是这个巨型散点图给我们一个关于变量关系的合理的想法。
我们可能发现的一个有趣的数字是“TotalBsmtSF”和“GrLiveArea”之间的一个数字。在这个图中,我们可以看到点画出一条直线,它几乎像一个边框。大多数的点保持在这条线以下是完全有意义的。地下室面积可以与地面以上的居住面积相等,但不能指望地下室面积大于地面以上的居住面积(除非你想买地堡)。
关于“SalePrice”和“YearBuilt”的情节也可以让我们思考。在“点云”的底部,我们看到了几乎是一个害羞的指数函数(有创意)。我们也可以在“点云”的上限看到同样的趋势(更具创造性)。另外,注意一下过去几年的点集如何保持在这个极限以上(我只是想说,现在价格上涨的速度更快).
缺失数据
在考虑数据缺失这个问题时,有两个问题需要注意:
1. 缺失数据有多普遍?
2. 数据丢失是随机的还是有模式的?
这些问题的答案是非常重要的实际原因,因为丢失的数据可以意味着减少样本量。这可以阻止我们继续进行分析。此外,从实质的角度来看,我们需要确保缺失的数据过程没有偏见和隐藏一个不方便的真相。
total = df_train.isnull().sum().sort_values(ascending=False)
percent = (df_train.isnull().sum()/df_train.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
missing_data.head(20) Total Percent
PoolQC 1453 0.995205
MiscFeature 1406 0.963014
Alley 1369 0.937671
Fence 1179 0.807534
FireplaceQu 690 0.472603
LotFrontage 259 0.177397
GarageCond 81 0.055479
GarageType 81 0.055479
GarageYrBlt 81 0.055479
GarageFinish 81 0.055479
GarageQual 81 0.055479
BsmtExposure 38 0.026027
BsmtFinType2 38 0.026027
BsmtFinType1 37 0.025342
BsmtCond 37 0.025342
BsmtQual 37 0.025342
MasVnrArea 8 0.005479
MasVnrType 8 0.005479
Electrical 1 0.000685
Utilities 0 0.000000
让我们分析这一点,了解如何处理丢失的数据。
我们认为,当超过15%的数据丢失时,我们应该删除相应的变量并假装它不存在,这意味着我们不会尝试任何伎俩来填补丢失的数据在这些情况下。这样子,这里有些特征可以直接删除了。重点是:我们会错过这些数据吗?我不这么认为。这些变量中没有一个看起来很重要,因为大部分都不是我们在买房时考虑的方面(也许这就是为什么数据丢失的原因?)此外,仔细观察变量,我们可以说,像“PoolQC”、“MiscFeature”和“FireplaceQu”这样的变量是异常值的有力候选,所以我们将很乐意删除它们。
在剩余的情况下,我们可以看到“GarageX”变量有相同数量的缺失数据。我打赌失踪数据指的是同一组观察(虽然我不会检查它,它只是5%,我们不应该花20in5个问题)。因为关于车库的最重要的信息是用“GarageCars”来表达的,考虑到我们只讨论了5%的缺失数据,我将删除所提到的“GarageX”变量。同样的逻辑适用于“BsmtX”变量。
至于‘MasVnrArea’和‘MasVnrType’,我们可以认为,这些变量是不必要的。另外,他们和我们已经考虑过得‘YearBuilt’和‘OverallQual’有强相关关系。 因为删除他们将不会有什么信息丢失。
最后,我们有一个缺失的观察“Electrical”。因为它只是一个观察,我们将删除这个观察并保持变量。
总之,为了处理丢失的数据,除了变量“Electrical”,我们将删除所有缺少数据的变量。在“Electrical”中,我们只需删除缺失数据的观测数据。
#dealing with missing data
df_train = df_train.drop((missing_data[missing_data['Total'] > 1]).index,1)
df_train = df_train.drop(df_train.loc[df_train['Electrical'].isnull()].index)
df_train.isnull().sum().max() #just checking that there's no missing data missing..单变量分析
离群点也是我们应该意识到的。为什么?因为离群值可以显著影响我们的模型,并且可以是一个有价值的信息源,提供我们对特定行为的洞察力。
离群点是一个复杂的问题,值得关注。这里,我们将通过“SalePrice”的标准偏差和一组散点图来快速分析。
这里主要关注的是建立一个阈值,将观测定义为离群点。要做到这一点,我们将标准化数据。在这种情况下,数据标准化意味着将数据值转换为平均值为0,标准偏差为1。
#standardizing data
saleprice_scaled = StandardScaler().fit_transform(df_train['SalePrice'][:,np.newaxis]);
low_range = saleprice_scaled[saleprice_scaled[:,0].argsort()][:10]
high_range= saleprice_scaled[saleprice_scaled[:,0].argsort()][-10:]
print('outer range (low) of the distribution:')
print(low_range)
print('\nouter range (high) of the distribution:')
print(high_range)outer range (low) of the distribution: [[-1.83820775] [-1.83303414] [-1.80044422] [-1.78282123] [-1.77400974] [-1.62295562] [-1.6166617 ] [-1.58519209] [-1.58519209] [-1.57269236]] outer range (high) of the distribution: [[3.82758058] [4.0395221 ] [4.49473628] [4.70872962] [4.728631 ] [5.06034585] [5.42191907] [5.58987866] [7.10041987] [7.22629831]]
‘SalePrice’看起来怎么样:
1. 低范围值相似且不太远离0。
2. 高范围的值远远大于0,甚至有些超过7。
现在,我们不认为这些值是离群值,但是我们应该小心这两个7.1值。
双变量分析
我们已经知道了下面的散点图。然而,当我们从新的角度看待事物时,总会有一些东西可以发现。正如Alan Kay所说,“视角的改变值80个智商点”。
#bivariate analysis saleprice/grlivarea
var = 'GrLivArea'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));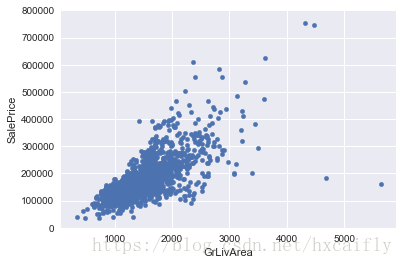
上图揭示了:
1. 有两个GrLivArea比较大的值看起来很奇怪,它们似乎疏远了群体。我们可以推测为什么会发生这种情况。也许他们指的是农业区,这可以解释低价。我不确定这一点,但我很自信这两个点并不代表典型的情况。因此,我们将它们定义为离群值并删除它们。
2. 图中的两个观测结果是我们所说的那些我们应该小心的观测结果。他们看起来像两个特殊的情况,但是他们似乎正在跟随这一趋势。因为这个原因,我们会保留它们。
#删除异常点
df_train.sort_values(by = 'GrLivArea', ascending = False)[:2]
df_train = df_train.drop(df_train[df_train['Id'] == 1299].index)
df_train = df_train.drop(df_train[df_train['Id'] == 524].index)#bivariate analysis saleprice/grlivarea
var = 'TotalBsmtSF'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));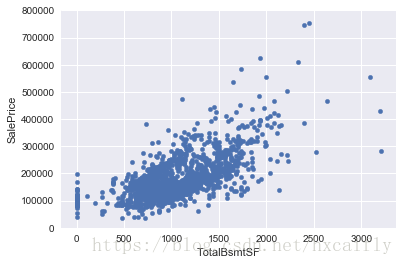
我们可以感觉到想要消除一些观察(例如TotalBsmtSF>3000),但我认为这不值得。我们可以生活在一起,所以我们什么也不会做。
获得硬核
在Ayn Rand的小说《Atlas Shrugged》中,有一个经常重复的问题:John Galt是谁?这本书的很大一部分是关于寻找这个问题答案的探索。
我也是有点徘徊,SalePrice是谁?
这个问题的答案在于检验多元分析统计基础的假设。我们已经做了一些数据清理,发现了很多关于“SalePrice”的信息。现在是深入了解SalePrice如何符合统计假设的时候了,这使得我们能够运用多元技术。
4个假设需要去验证:
1. 正态:当我们谈论正态时,我们的意思是数据应该看起来像正态分布。这是重要的,因为一些统计测试依赖于此(例如T统计量)。在这个练习中,我们只检查“SalePrice”(这是一个有限的方法)的单变量正态性。请记住,单变量常态不能确保多元正态性(这正是我们所希望的),但它有帮助。另一个要考虑的细节是,在大样本(>200个观测值)中,正态性不是这样的问题。然而,如果我们解决常态,我们避免了很多其他问题(例如异方差),所以这就是我们做这个分析的主要原因。
2. 同方差性: 我只是希望我写对了。同方差是指假设变量在预测变量的范围内表现出相等的方差水平。方差齐性是可取的,因为我们想要的误差项在独立变量的所有值是相同的。
3. 线性度:评估线性的最常用方法是检查散点图和搜索线性模式。如果模式不是线性的,那么探索数据转换是值得的。然而,我们不会进入这一点,因为我们所看到的大多数散布图似乎具有线性关系。
4. 相关误差的缺失:相关错误,如定义所示,发生在一个错误与另一个错误相关时。例如,如果一个正误差系统地产生一个负误差,则意味着这些变量之间存在一个关系。这经常发生在时间序列中,其中一些模式是与时间相关的。我们也不会参与进来。但是,如果你发现了什么,试着添加一个变量来解释你得到的效果。这是相关错误最常见的解决方案。
寻找正态
这里的重点是以一种非常精益的方式来测试“SalePrice”。我们重点关注:
1. 直方图-峰度和偏度。
2. 正态概率图-数据分布应该紧跟代表正态分布的对角线。
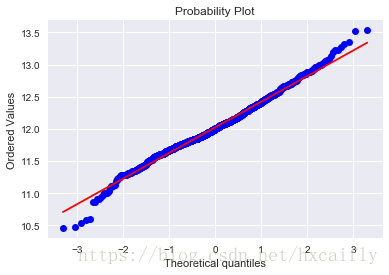
#histogram and normal probability plot
sns.distplot(df_train['SalePrice'], fit=norm);
fig = plt.figure()
res = stats.probplot(df_train['SalePrice'], plot=plt)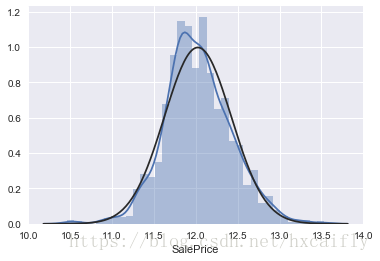
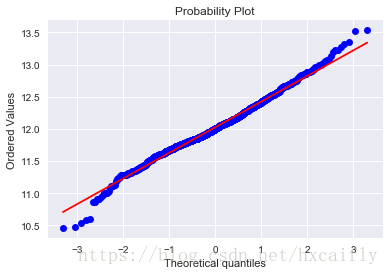
好吧,“SalePrice”不是正态的。它表现出“尖峰”,正偏斜,不遵循对角线。
但一切都没有失去。一个简单的数据转换可以解决这个问题。这是你在统计书籍中可以学到的一件令人敬畏的事情:在正偏斜的情况下,对数转换通常效果良好。当我发现这一点时,我感觉就像霍格沃茨的学生发现了一个新的酷咒语。
#applying log transformation
df_train['SalePrice'] = np.log(df_train['SalePrice'])#transformed histogram and normal probability plot
sns.distplot(df_train['SalePrice'], fit=norm);
fig = plt.figure()
res = stats.probplot(df_train['SalePrice'], plot=plt)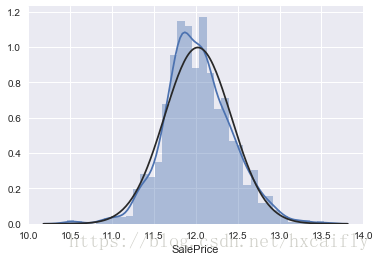
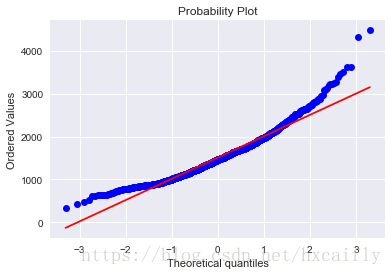
让我们继续分析GrLivArea。
#histogram and normal probability plot
sns.distplot(df_train['GrLivArea'], fit=norm);
fig = plt.figure()
res = stats.probplot(df_train['GrLivArea'], plot=plt)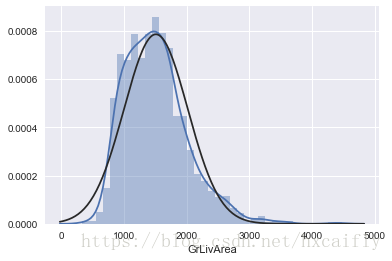
#data transformation
df_train['GrLivArea'] = np.log(df_train['GrLivArea'])#transformed histogram and normal probability plot
sns.distplot(df_train['GrLivArea'], fit=norm);
fig = plt.figure()
res = stats.probplot(df_train['GrLivArea'], plot=plt)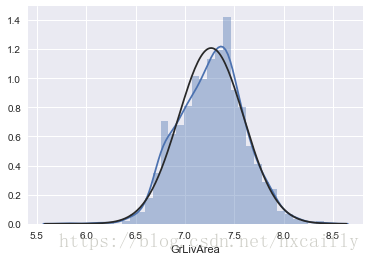
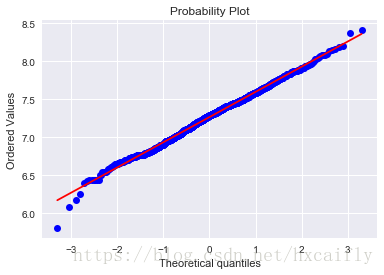
好,继续下一个
#histogram and normal probability plot
sns.distplot(df_train['TotalBsmtSF'], fit=norm);
fig = plt.figure()
res = stats.probplot(df_train['TotalBsmtSF'], plot=plt)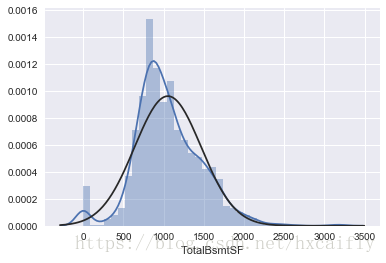

好吧,现在我们正在和大老板打交道。我们这儿有什么?
1. 一般来说,呈现偏斜。
2. 相当数量的观测值为零(没有地下室的房屋)。
3. 一个很大的问题,因为值零不允许我们做对数转换。
为了在这里应用对数转换,我们将创建一个变量,该变量可以得到具有或不具有地下室(二进制变量)的效果。然后,我们将对所有非零观测值进行对数变换,忽略那些值为0的观测值。这样我们就可以在不丢失地下室的情况下转换数据。
我不确定这种方法是否正确。这对我来说似乎是对的。这就是我所说的“高风险工程”。
#create column for new variable (one is enough because it's a binary categorical feature)
#if area>0 it gets 1, for area==0 it gets 0
df_train['HasBsmt'] = pd.Series(len(df_train['TotalBsmtSF']), index=df_train.index)
df_train['HasBsmt'] = 0
df_train.loc[df_train['TotalBsmtSF']>0,'HasBsmt'] = 1#transform data
df_train.loc[df_train['HasBsmt']==1,'TotalBsmtSF'] = np.log(df_train['TotalBsmtSF'])#histogram and normal probability plot
sns.distplot(df_train[df_train['TotalBsmtSF']>0]['TotalBsmtSF'], fit=norm);
fig = plt.figure()
res = stats.probplot(df_train[df_train['TotalBsmtSF']>0]['TotalBsmtSF'], plot=plt)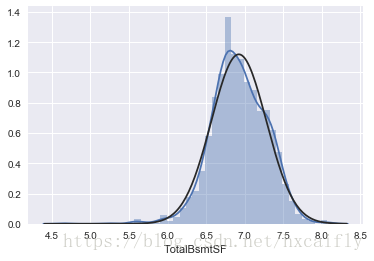
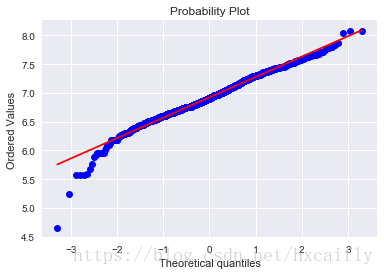
在第一次尝试中寻找“同方差”
两个度量变量的同方差检验的最佳方法是图形化的。等距分布的偏离由圆锥(如图的一侧的少点、对侧的多点)或菱形(分布中心处多点)等形状来表示。
#scatter plot
plt.scatter(df_train['GrLivArea'], df_train['SalePrice']);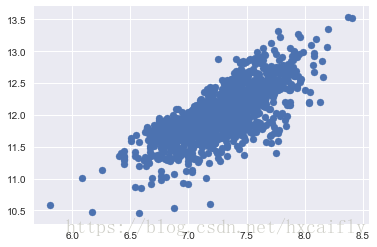
在做对数处理之前的老版本散点图是锥型。正如你所看到的,当前的散点图不再有圆锥曲线。这就是正态的力量!通过确保某些变量的正态性,我们解决了同方差问题。
现在让我们看下’SalePrice’和’TotalBsmtSF’。
#scatter plot
plt.scatter(df_train[df_train['TotalBsmtSF']>0]['TotalBsmtSF'], df_train[df_train['TotalBsmtSF']>0]['SalePrice']);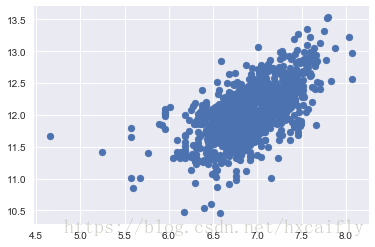
我们可以说,一般来说,“SalePrice”在“TotalBsmtSF”的范围内表现出相等的方差水平。酷!
最后但并非最不重要的是,哑变量
df_train = pd.get_dummies(df_train)结论
这才刚刚开始,下一步就要开始预测了SalePrice的行为了。其实我们会发现,认识数据和清洗数据,其实是紧紧围绕这业务来展开的,你能想到什么,基本上决定了你会做出什么样的分析。