计划在国庆期间推出一些挖掘算法,是不是心血来潮?绝对不是。应一小粉丝私信提出小要求,推一些挖掘算法的文章。只是写博文真的巨费时间,所以我会按自己的理解把算法的框架推出来,其中的一些细节推导我会在后期抽时间补充。
1 知识框架
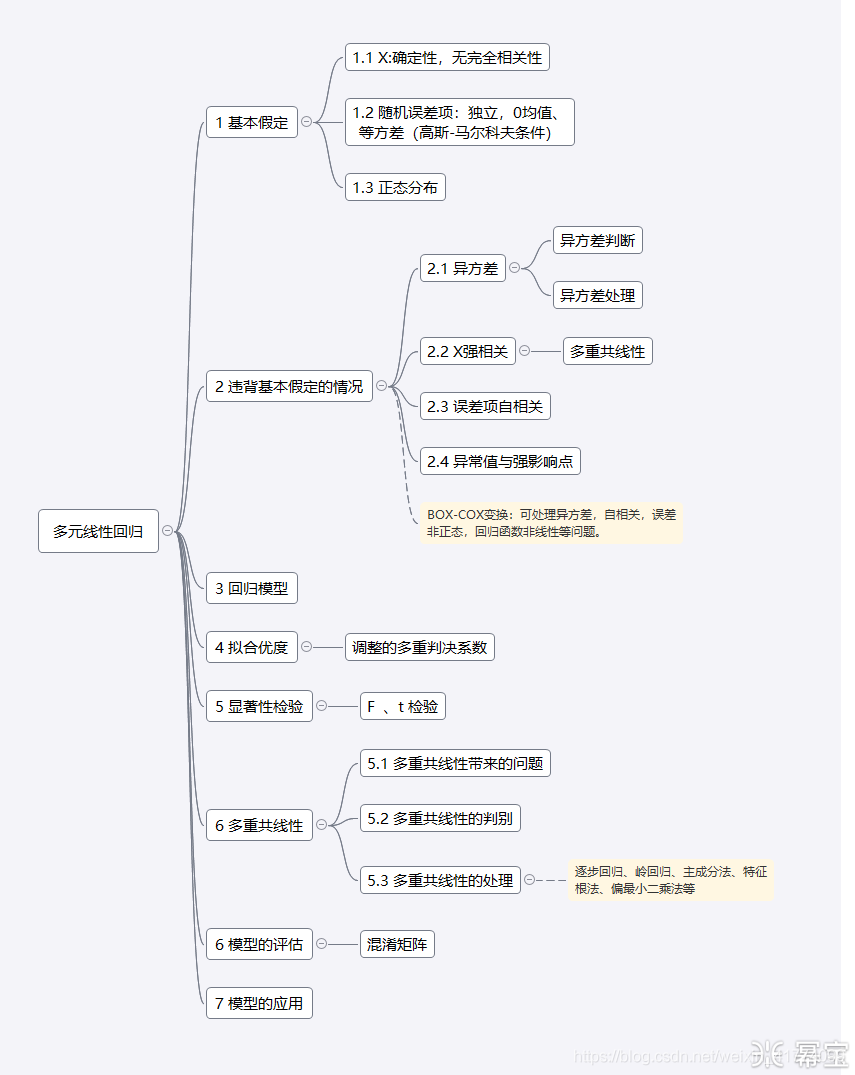
2 知识详解
2.1基本假定
多元线性回归算法在商业环境中比较吃香,就在于它的可解释性强。它的一般形式:
其中
是模型的参数,
是误差项。当然,可解释能力强,也使得该算法的假定条件较其他算法更苛刻:

2.2违背基本假定的情况
在处理实际的业务问题中,这些基本假定是很不友好的。需要数据分析师用特定的技术对实际业务数据进行转换,使得实际业务场景尽可能的逼近多元线性回归的基本假定。
2.2.1异方差
现实业务问题错综复杂,很多原因都会导致异方差,这是不可避免的。异方差会带来什么影响呢?怎样检查异方差呢?怎样解决异方差问题呢?
它会使得模型的最小二乘估计失效:(1)参数估计无偏,但不是最小线性无偏;(2)参数的显著性检验失效;(3)回归方差的泛化能力极差。
对异方差检验多用残差图分析法、等级相关系数法。回归模型满足基本假定时,残差图的分布是随机的、没有任何规律的,如果有异方差性,会出现一定的趋势或规律。等级相关系数法也叫斯皮尔曼(spearman)检验,它通常有三个步骤:

解决异方差问题的方法通常有加权最小二乘法、BOX-COX变换法、方差稳定性变换法。加权最小二乘法是常用的也最容易理解的方法之一。
2.2.2 X强相关
在多元线性回归中,对变量的理想关系是每个解释变量都与因变量相关且每个解释变量间无关。解释变量间的相关性问题也就是多重共线性问题,者是无可避免的,后文会专门解释。
2.2.3 误差项自相关
遗漏关键变量、滞后的经济变量、错误的回归函数形式、蛛网现象、数据加工等都会产生自相关问题。自相关问题使得:(1)参数估计值不再具有最小方差线性无偏;(2)均方误差(MSE)严重低估误差项误差;(3)得到错误的显著性检验结果;(4)
极其不稳定;(5)没处理此问题,最终的模型预测、结构会带来极大的误差和错误的解释。
自相关问题的检验通常有自相关图、自相关系数法、DW检验。处理该问题多有迭代法、差分法。
2.2.4 异常值与强影响点
判定是否为异常值,3倍标准差原则、删除学生化误差、杠杆值、库克距离等。库克距离公式:
其中,
为杠杆值,
认为是非异常值,
认为是异常值。产生异常值的原因不同,处理的方法也不同。

2.3回归模型
在使用多元线性回归进行建模时,主要有全变量建模、选变量建模。对解释变量的重要性不清楚的时候,一般会做全变量模型,再根据模型的评估结果对变量进行筛选,得到最优的选变量模型。
2.4 拟合优度
拟合优度用于反映模型对因变量的估计程度。指标有调整的多重判定系数:
实际意义表明,在因变量的变化中能被解释变量所解释的比例为
。选择
,是因为未调整的多重判定系数
会因为自变量的增加,使得预测误差变小,从而使得
偏大,得到错误的评估结果。
2.5显著性检验
总体显著性检验

回归系数著性检验

2.6多重共线性
解释变量间完全不相关的假设是非常少见的,尤其是在商业环境中。鉴于问题本身的复杂性,涉及的因素众多,在建立模型时很难找到一组互不相关的解释变量来解释因变量。就无法避免面临解释变量建度相关性影响,当解释变量间的相关性很高时,我们说这是多重共线性问题。
多重共线性的存在,使得模型对的结果混乱,信息高度重叠,不好解释,还会影响参数估计值的符号,会增加不必要的计算量等等。对多重共线性的检验方法 众多。当有下列几种情况时,会认为存在严重的多重共线性:
(1)模型的各对解释变量间显著相关;
(2)当模型的线性关系检验显著时<F检验>,几乎所有的回归系数t检验不通过;
(3)回归的±号与预期相反;
(4)容忍度
与方差膨胀因子
.
其中
,容忍度越小,方差膨胀因子越大(>10),认为存在严重多重共线性。
对于多重共线性的处理,方法有很多。多重共线性的源头在于解释变量间的强相关性,只要能解出变量间的强相关性,就算作时对多重共线性问题的处理。通常有保留强相关的几个变量中的一个、逐步回归、岭回归、主成分法、特征根法、偏最小二乘法等。
2.6模型的评估
多元线性回归的模型评估指标有均方误差( )、调整多重判别系数( ),当然也可以引入混淆矩阵。
2.6模型的应用
通过评估后的模型可以初步上线投入使用,将实际业务的数据加工成模型的可识别输入格式即可。在模型的具体应用中,可能会出现新的问题,这就要求数据分析师要定期对模型进行评估和重建、调休,保证模型功效。
3 在R|Python 中的实现
多元线性回归在R和Python 中都有专门的包来实现。R中的实现可以借鉴我之前的文章《【R】基于Logistic回归的初始信用评级》,该文的Logistic回归起源于多元线性回归。Python中的实现可通过下面链接查看。
| Python 线性回归 |
|---|
| https://nbviewer.jupyter.org/github/lda188/my-data/blob/master/%E7%BA%BF%E6%80%A7%E5%9B%9E%E5%BD%92%E4%B8%8A.ipynb |
