用最简单的python语法实现小网格环境下的迭代策略评估(Iterative Policy Evaluation in Small Gridworld)
一 、小网格环境下的迭代策略简介
哈哈,能看到这篇博客的应该都对这张两图再熟悉不过。
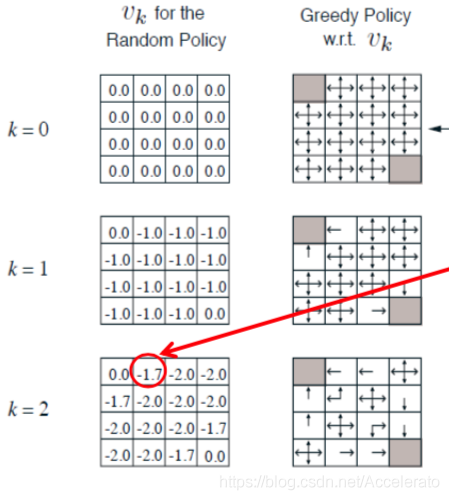
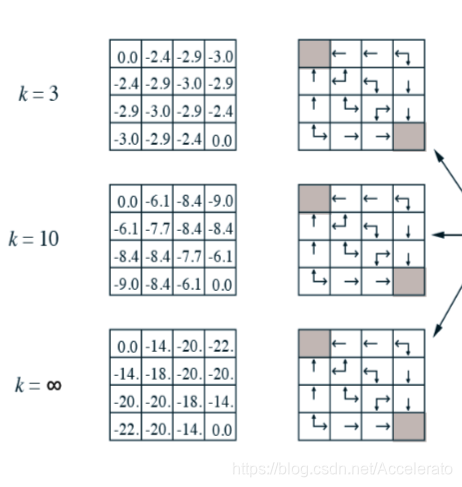
在阅读此篇博客之前,希望你已经对马尔可夫决策以及贝尔曼方程有初步的了解。
在此基础上,通过这篇博客,你可以学会以下几点。
- 那个-1.7究竟是怎么算的?(其实并不是-1.7)
- k取任意值时每个方格里面每个值是怎么算的?
- 如何用python计算任意次迭代次数(k取任意值)后这个网格中任意方格中的值?
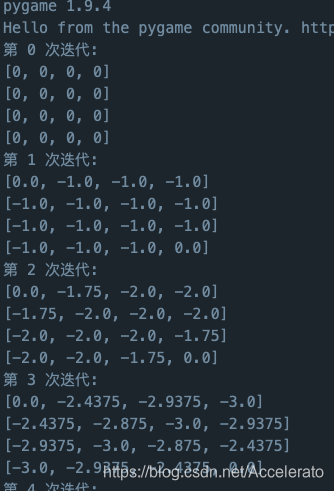
-
- 如何用python实现对于任意大小的网格,完成上步操作?
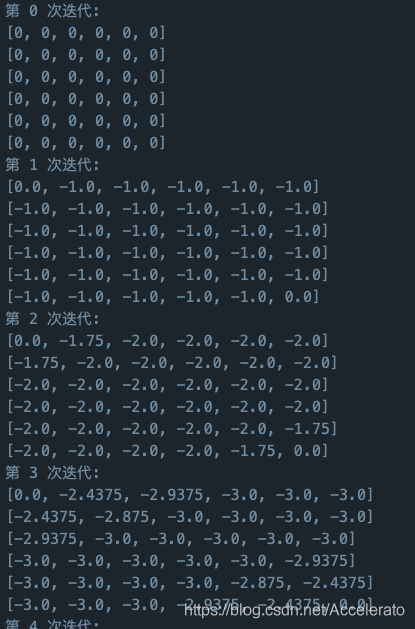
- 如何用python实现此游戏的的可视化?当然啦,网格的大小你可以自己调,同时除了马尔可夫决策外,我还准备了随机决策。通过可视化,你可以看到小方块在两种策略下具体是怎么移动的。



二、问题重述
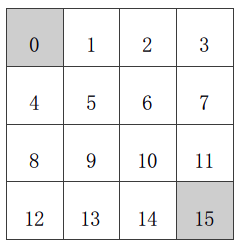
已知(如上图):
- 状态空间 S:S_1 - S_14为非终止状态;S_0,S_15 终止状态,图中灰色方格所示两个位置;
- 行为空间 A:{n, e, s, w} 对于任何非终止状态可以有向北、东、南、西移动四个行为;
- 转移概率 P:任何试图离开方格世界的动作其位置将不会发生改变,其余条件下将100%地转移到动作指向的位置;
- 即时奖励 R:任何在非终止状态间的转移得到的即时奖励均为-1,进入终止状态即时奖励为0;
- 衰减系数 γ:1;
- 当前策略π:个体采用随机行动策略,在任何一个非终止状态下有均等的几率往任意可能的方向移动,即π(n|•) = π(e|•) = π(s|•) = π(w|•) = 1/4。
- 问题:评估在这个方格世界里给定的策略。
- 该问题等同于:求解该方格世界在给定策略下的(状态)价值函数,也就是求解在给定策略下,该方格世界里每一个状态的价值。
三、如何计算每个方块的状态的价值?
给出通俗易懂的解释:
这个格子在k=n时的价值等于(它到周围格子的策略价值总和再加上及时奖励的价值总和)/4。特别的,它如果撞墙了,则回到自身,同样也有-1的及时奖励,而回到自身所产生的策略价值就是k=n-1时的这个各自的价值。
给出通俗易懂的公式:
用Pn(i,j)表示坐标为(i,j)的格子在k=n时的策略价值,则
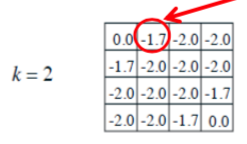
以下图红圈内的格子为例:
P=(0-1-1-1-4)/4=-1.75,所以这里的-1.7的确切值应该是-1.75
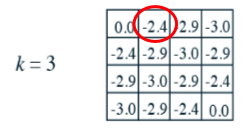
以下图红圈内的格子为例:
P=(0-1.75-2-2-4)/4=-2.4375,所以这里的-2.4的确切值应该是-2.4375
四、python求解任意棋盘大小任意k值任意网格的价值
定义一个评分函数,传入参数是棋盘的大小,题目中棋盘大小为4*4,所以chess_number为4。之后定义两个二维数组,用于存放每个格子的价值以及更新后的价值,均赋0备用。
def chess_score(chess_number):
global score
global newscore
for i in range(chess_number):
score.append([])
for j in range(chess_number):
score[i].append(0)
for i in range(chess_number):
newscore.append([])
for j in range(chess_number):
newscore[i].append(0)
设置迭代次数,因为有限过程的markov过程是收敛的,依据经验本约束条件下大约150次左右价值趋于稳定,所以这里我设置iteration为150.
之后遍历棋盘判断所有点的价值。
除了终点外,我将任意大小的棋盘分成九个区域,分别是右上角,中上,左上角,左中,右中,左下角,中下,右下角,以及通常。之后分类套公式,再将更新的价值存入newscore中。那么为什么不直接存入score中呢,因为如果立刻存入score,在一次迭代没有结束时,这个点的价值会影响后面未更新点的价值,导致结果出错。
for iteration in range(150):
print("第",iteration,"次迭代:")
for i in range(chess_number):
print(score[i])
for i in range(chess_number):
for j in range(chess_number):
if [i,j] in endpos1:#吸收态坐标
score[i][j]=0.0
else:
if(i==0 and j==0):#左上
newscore[i][j]=round((score[i][j]+score[i+1][j]+score[i][j+1]+score[i][j]-4)/4.0,5)
elif (i==0 and j!=0 and j!=chess_number-1):#中上
newscore[i][j]=round((score[i][j]+score[i+1][j]+score[i][j+1]+score[i][j-1]-4)/4.0,5)
elif (i==0 and j==chess_number-1 ):#右上
newscore[i][j]=round((score[i][j]+score[i+1][j]+score[i][j]+score[i][j-1]-4)/4.0,5)
elif (i!=0 and i!=chess_number-1 and j==0 ):#左中
newscore[i][j]=round((score[i-1][j]+score[i+1][j]+score[i][j+1]+score[i][j]-4)/4.0,5)
elif (i!=0 and i!=chess_number-1 and j!=0 and j!=chess_number-1):#normal
newscore[i][j]=round((score[i-1][j]+score[i+1][j]+score[i][j+1]+score[i][j-1]-4)/4.0,5)
elif (i!=0 and i!=chess_number-1 and j==chess_number-1):#右中
newscore[i][j]=round((score[i-1][j]+score[i+1][j]+score[i][j]+score[i][j-1]-4)/4.0,5)
elif (i==chess_number-1 and j==0):#左下
newscore[i][j]=round((score[i-1][j]+score[i][j]+score[i][j+1]+score[i][j]-4)/4.0,5)
elif (i==chess_number-1 and j!=0 and j!=chess_number-1):#中下
newscore[i][j]=round((score[i-1][j]+score[i][j]+score[i][j+1]+score[i][j-1]-4)/4.0,5)
elif (i==chess_number-1 and j==chess_number-1):#右下
newscore[i][j]=round((score[i-1][j]+score[i][j]+score[i][j]+score[i][j-1]-4)/4.0,5)
更新score的值,没啥好说的。
for i in range(chess_number):
for j in range(chess_number):
if newscore[i][j]!=0:
score[i][j]=newscore[i][j]
newscore[i][j]=0
五、python实现该游戏的可视化
首先说说可以实现哪些内容吧。
- 可以自己设置网格的大小。
- 实现随机决策下随机格子走到终点的动画
- 实现马尔可夫决策下随机格子走到终点的动画
准备工作
这里我是用pygame做的,所以要导入pygame哦,没装的同学要记得先装一下,网上教程很多,这里就不再赘述。
import pygame
import sys
import math
import random
# pygame 初始化
pygame.init()
# 设置棋盘大小
chess_number=6
# 设置是否使用马尔可夫决策
usemarkov=1#等于1使用,等于0不使用
BG=(144,136,145)#背景色
LINECOLOR=(112,73,46)#网格色
STEPCOLOR=(79,167,47)#随机格子的颜色
STARTCOLOR=(119,207,87)#你想实现格子轨迹的时候用介个颜色好看
ENDCOLOR=(34,60,36)#吸收态格子的颜色
WINCOLOR=(253,176,36)#随机格子落入吸收态的颜色
WALLCOLOR=(112,73,46)#墙壁的颜色,本来还想实现障碍物的,介个就交给你们啦
TEXTCOLOR=(200,98,96)#文本的颜色
#设置起始位置(左上角)
START_POS=(50,50)
START_POSX=50
START_POSY=50
CELL_LENGTH=100#每个格子的像素大小
LINE_WIDTH=4#线的宽度
# 设置背景框大小
size = width, height = 2*START_POSX+chess_number*CELL_LENGTH,2*START_POSY+chess_number*CELL_LENGTH
# 设置帧率,返回clock 类
clock = pygame.time.Clock()
screen = pygame.display.set_mode(size)
pygame.display.set_caption("Accelerator made")
# 设置起始位置
start_posx=random.randint(1,chess_number)
start_posy=random.randint(1,chess_number)
#设置位置
pos=[start_posx,start_posy]
endpos=[[1,1],[chess_number,chess_number]]#可视化用
endpos1=[[0,0],[chess_number-1,chess_number-1]]#价值计算用
#设置分数
score=[]
newscore=[]
#初始化步数
step=0
画图函数
画网格线啦,画各种格子啦,显示完成后的文字“COMPLETE!”啦
在一开始的时候step为0,画起点,之后通过判断usemarkov的值来确定决策种类。更新方块儿位置。
def draw():
global pos
global step
for i in range(chess_number+1):
pygame.draw.line(screen, LINECOLOR, (START_POSX,START_POSY+i*CELL_LENGTH), (START_POSX+chess_number*CELL_LENGTH,START_POSY+i*CELL_LENGTH), LINE_WIDTH)#横线
pygame.draw.line(screen, LINECOLOR, (START_POSX+i*CELL_LENGTH,START_POSY),(START_POSX+i*CELL_LENGTH,START_POSY+chess_number*CELL_LENGTH), LINE_WIDTH)#竖线#
drawcell(chess_number, chess_number, ENDCOLOR) #终点
drawcell(1, 1, ENDCOLOR)#终点
if step==0:
drawcell(pos[0],pos[1], STEPCOLOR)#起点
#drawcell(start_posx, start_posy, STARTCOLOR)#起点
else:
if (pos!=endpos[0] and pos!=endpos[1]):
print(pos)
if usemarkov==0:
pos=nologic(pos)#随机决策
else:
pos=markov(pos)#马尔可夫决策
else:
drawcell(pos[0], pos[1], WINCOLOR)#终点
my_font=pygame.font.Font('mufont.ttf',20*chess_number)
text=my_font.render("COMPLETE!",True,TEXTCOLOR)
screen.blit(text,(100,height/2-100))
step+=1
具体画格子的方法
在pygame中很简单,就是画一个矩形就行
def drawcell(i,j,cellkind):#行,列,方块种类
pygame.draw.rect(screen,cellkind,[START_POSX+CELL_LENGTH*(j-1)+(LINE_WIDTH-1),START_POSY+CELL_LENGTH*(i-1)+(LINE_WIDTH-1),CELL_LENGTH-LINE_WIDTH,CELL_LENGTH-LINE_WIDTH],0)#终点.
实现随机决策的方法
很简单,思想前面已经说过了,将棋盘分成九个区域,对于每个区域的格子判断可能的行走方向,再随机取一个就OK。
def nologic(pos):
i=pos[0]
j=pos[1]
#drawcell(i,j, STARTCOLOR)#下
if (i==1 and j==1):#左上
print("左上")
godnum=random.randint(1,2)
if godnum==1:
drawcell(i,j+1, STEPCOLOR)#下
pos=[i,j+1]
elif godnum==2:
drawcell(i,j+1, STEPCOLOR)#右
pos=[i,j+1]
elif (i==1 and j!=1 and j!=chess_number):#中上
print("中上")
godnum=random.randint(1,3)
if godnum==1:
drawcell(i,j+1, STEPCOLOR)#下
pos=[i,j+1]
elif godnum==2:
drawcell(i,j+1, STEPCOLOR)#右
pos=[i,j+1]
elif godnum==3:
drawcell(i,j-1, STEPCOLOR)#左
pos=[i,j-1]
elif (i==1 and j==chess_number ):#右上
print("右上")
godnum=random.randint(1,2)
if godnum==1:
drawcell(i+1,j, STEPCOLOR)#下
pos=[i+1,j]
elif godnum==2:
drawcell(i,j-1, STEPCOLOR)#左
pos=[i,j-1]
elif (i!=1 and i!=chess_number and j==1 ):#左中
print("左中")
godnum=random.randint(1,3)
if godnum==1:
drawcell(i+1,j, STEPCOLOR)#下
pos=[i+1,j]
elif godnum==2:
drawcell(i,j+1, STEPCOLOR)#右
pos=[i,j+1]
elif godnum==3:
drawcell(i-1,j, STEPCOLOR)#上
pos=[i-1,j]
elif (i!=1 and i!=chess_number and j!=1 and j!=chess_number):#normal
print("normal")
godnum=random.randint(1,4)
if godnum==1:
drawcell(i+1,j, STEPCOLOR)#下
pos=[i+1,j]
elif godnum==2:
drawcell(i,j+1, STEPCOLOR)#右
pos=[i,j+1]
elif godnum==3:
drawcell(i,j-1, STEPCOLOR)#左
pos=[i,j-1]
elif godnum==4:
drawcell(i-1,j, STEPCOLOR)#上
pos=[i-1,j]
elif (i!=1 and i!=chess_number and j==chess_number):#右中
print("右中")
godnum=random.randint(1,3)
if godnum==1:
drawcell(i+1,j, STEPCOLOR)#下
pos=[i+1,j]
elif godnum==2:
drawcell(i,j-1, STEPCOLOR)#左
pos=[i,j-1]
elif godnum==3:
drawcell(i-1,j, STEPCOLOR)#上
pos=[i-1,j]
elif (i==chess_number and j==1):#左下
print("左下")
godnum=random.randint(1,2)
if godnum==1:
drawcell(i,j+1, STEPCOLOR)#右
pos=[i,j+1]
print("往右边走")
elif godnum==2:
drawcell(i-1,j, STEPCOLOR)#上
pos=[i-1,j]
print("往上边走")
elif (i==chess_number and j!=1 and j!=chess_number):#中下
print("中下")
godnum=random.randint(1,3)
if godnum==1:
drawcell(i,j+1, STEPCOLOR)#右
pos=[i,j+1]
print("往右边走")
elif godnum==2:
drawcell(i,j-1, STEPCOLOR)#左
pos=[i,j-1]
print("往左边走")
elif godnum==3:
drawcell(i-1,j, STEPCOLOR)#上
pos=[i-1,j]
print("往上边走")
elif (i==chess_number and j==chess_number):#右下
print("右下")
godnum=random.randint(1,2)
if godnum==1:
drawcell(i,j-1, STEPCOLOR)#左
pos=[i,j-1]
print("往左边走")
elif godnum==2:
drawcell(i-1,j, STEPCOLOR)#上
pos=[i-1,j]
print("往上边走")
return pos
实现马尔可夫决策的方法
有了上面价值表作为基础,实现马尔可夫决策就更简单啦,只需要判断方块儿上下左右的价值是否比自己价值大,然后往价值大的地方走就OK啦。
def markov(pos):
i=pos[0]-1
j=pos[1]-1
print(pos)
print(score[i][j-1],score[i][j])
if score[i-1][j]>score[i][j] and i-1>=0:
drawcell(i,j+1, STEPCOLOR)
print("往上走")
pos=[i,j+1]
return pos
if i+1<chess_number and score[i+1][j]>score[i][j]:
drawcell(i+2,j+1, STEPCOLOR)
print("往下走")
pos=[i+2,j+1]
return pos
if score[i][j-1]>score[i][j]:
drawcell(i+1,j, STEPCOLOR)
print("往左走")
pos=[i+1,j]
return pos
if j+1<chess_number and score[i][j+1]>score[i][j]:
drawcell(i+1,j+2, STEPCOLOR)
print("往右走")
pos=[i+1,j+2]
return pos
好啦,到此为止,小网格环境下的迭代策略评估的价值计算以及python可视化的实现就算全部完成啦。如果有什么疏漏之处或者好的建议,也欢迎指正哦。
