今天跟大家介绍以下知识。怎么来实现文本中的人物关系可视化?
一、软件安装
安装的软件,点击此处,整个流程及安装过程见参考博客
提醒一下:
注意下载的文件一定要和自己的python版本和电脑位数对应;特别注意一下安装的版本,可能会出现不同版本的兼容问题。以下是我自己安装的,可以参考以下:
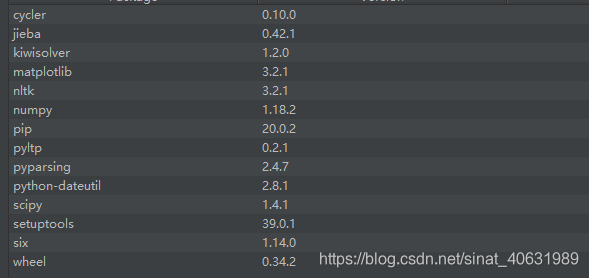
注意安装的顺序,一定是numpy-matplotlib-scipy.三者顺序不可以乱,因为后者的包对前者有依懒性。
此外,Wordcloud安装见此处 ,点击此处。
二、利用Wordcloud来生成人物关系
先给大家附上主要的两个python文件,如下:
# -*- coding: utf-8 -*-
from __future__ import print_function
import jieba
import codecs
from collections import defaultdict
TEXT_PATH = '../jsjs.txt' # 文本路径
DICT_PATH = 'person.txt' # 人物字典路径
SYNONYMOUS_DICT_PATH = 'synonymous_dict.txt' # 同义词路径
SAVE_NODE_PATH = 'node.csv'
SAVE_EDGE_PATH = 'edge.csv'
class RelationshipView:
def __init__(self, text_path, dict_path, synonymous_dict_path):
self._text_path = text_path
self._dict_path = dict_path
self._synonymous_dict_path = synonymous_dict_path
'''
person_counter是一个计数器,用来统计人物出现的次数。{'a':1,'b':2}
person_per_paragraph每段文字中出现的人物[['a','b'],[]]
relationships保存的是人物间的关系。key为人物A,value为字典,包含人物B和权值。
'''
self._person_counter = defaultdict(int)
self._person_per_paragraph = []
self._relationships = {}
self._synonymous_dict = {}
def generate(self):
self.count_person()
self.calc_relationship()
self.save_node_and_edge()
def synonymous_names(self):
'''
获取同义名字典
:return:
'''
with codecs.open(self._synonymous_dict_path, 'r', 'utf-8') as f:
lines = f.read().split('\r\n')
for l in lines:
self._synonymous_dict[l.split(' ')[0]] = l.split(' ')[1]
return self._synonymous_dict
def get_clean_paragraphs(self):
'''
以段为单位分割全文
:return:
'''
with codecs.open(self._text_path, 'r', 'utf-8') as f:
paragraphs = f.read().split('\r\n\r\n')
return paragraphs
def count_person(self):
'''
统计人物出场次数,添加每段的人物
:return:
'''
paragraphs = self.get_clean_paragraphs()
synonymous = self.synonymous_names()
print('start process node')
with codecs.open(self._dict_path, 'r', 'utf-8') as f:
name_list = f.read().split(' 10 nr\r\n') # 获取干净的name_list
for p in paragraphs:
jieba.load_userdict(self._dict_path)
# 分词,为每一段初始化新字典
poss = jieba.cut(p)
self._person_per_paragraph.append([])
for w in poss:
# 判断是否在姓名字典以及同义词区分
if w not in name_list:
continue
if synonymous.get(w):
w = synonymous[w]
# 往每段中添加人物
self._person_per_paragraph[-1].append(w)
# 初始化人物关系,计数
if self._person_counter.get(w) is None:
self._relationships[w] = {}
self._person_counter[w] += 1
return self._person_counter
def calc_relationship(self):
'''
统计人物关系权值
:return:
'''
print("start to process edge")
for p in self._person_per_paragraph:
for name1 in p:
for name2 in p:
if name1 == name2:
continue
if self._relationships[name1].get(name2) is None:
self._relationships[name1][name2] = 1
else:
self._relationships[name1][name2] += 1
return self._relationships
def save_node_and_edge(self):
'''
根据dephi格式保存为csv
:return:
'''
with codecs.open(SAVE_NODE_PATH, "a+", "utf-8") as f:
f.write("Id,Label,Weight\r\n")
for name, times in self._person_counter.items():
f.write(name + "," + name + "," + str(times) + "\r\n")
with codecs.open(SAVE_EDGE_PATH, "a+", "utf-8") as f:
f.write("Source,Target,Weight\r\n")
for name, edges in self._relationships.items():
for v, w in edges.items():
if w > 3:
f.write(name + "," + v + "," + str(w) + "\r\n")
print('save file successful!')
if __name__ == '__main__':
v = RelationshipView(TEXT_PATH, DICT_PATH, SYNONYMOUS_DICT_PATH)
v.generate()
# -*- coding: utf-8 -*-
from __future__ import print_function
import jieba.analyse
import matplotlib.pyplot as plt
from wordcloud import WordCloud
jieba.load_userdict("namedict.txt")
# 设置相关的文件路径
bg_image_path = "pic/image2.jpg"
text_path = '../jsjs.txt'
font_path = 'msyh.ttf'
stopwords_path = 'stopword.txt'
def clean_using_stopword(text):
"""
去除停顿词,利用常见停顿词表+自建词库
:param text:
:return:
"""
mywordlist = []
seg_list = jieba.cut(text, cut_all=False)
liststr = "/".join(seg_list)
with open(stopwords_path,encoding='UTF-8') as f_stop:
f_stop_text = f_stop.read()
f_stop_text = f_stop_text
f_stop_seg_list = f_stop_text.split('\n')
for myword in liststr.split('/'): # 去除停顿词,生成新文档
if not (myword.strip() in f_stop_seg_list) and len(myword.strip()) > 1:
mywordlist.append(myword)
return ''.join(mywordlist)
def preprocessing():
"""
文本预处理
:return:
"""
with open(text_path,encoding='UTF-8') as f:
content = f.read()
#conent = open('file_positions','open mould', encoding="utf-8")
return clean_using_stopword(content)
return content
def extract_keywords():
"""
利用jieba来进行中文分词。
analyse.extract_tags采用TF-IDF算法进行关键词的提取。
:return:
"""
# 抽取1000个关键词,带权重,后面需要根据权重来生成词云
allow_pos = ('nr',) # 词性
tags = jieba.analyse.extract_tags(preprocessing(), 1500, withWeight=True)
keywords = dict()
for i in tags:
print("%s---%f" % (i[0], i[1]))
keywords[i[0]] = i[1]
return keywords
def draw_wordcloud():
"""
生成词云。1.配置WordCloud。2.plt进行显示
:return:
"""
back_coloring = plt.imread(bg_image_path) # 设置背景图片
# 设置词云属性
wc = WordCloud(font_path=font_path, # 设置字体
background_color="white", # 背景颜色
max_words=2000, # 词云显示的最大词数
mask=back_coloring, # 设置背景图片
)
# 根据频率生成词云
wc.generate_from_frequencies(extract_keywords())
# 显示图片
plt.figure()
plt.imshow(wc)
plt.axis("off")
plt.show()
# 保存到本地
wc.to_file("wordcloud.jpg")
if __name__ == '__main__':
draw_wordcloud()
结果如下:
统计人物出现次数
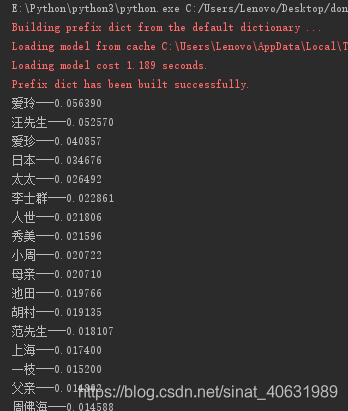
人物关系可视化结果:

整个代码在此下载:完整文件
注意更改一下两个python文件,以及文件路径。
具体是怎么实现的呢,待我一步步来跟大家介绍,见之后的博客。
参考博客:https://www.cnblogs.com/Sinte-Beuve/p/7617517.html
