本文主要以几个方面来讲解一下HashMap:
1、HashMap默认容量
2、HashMap如何扩容
3、HashMap的数组大小为什么一定要是2的幂
4、HashMap为什么是线程不安全的
5、Java7到Java8做了哪些改进
1、HashMap的默认容量
从HashMap的构造函数说起。
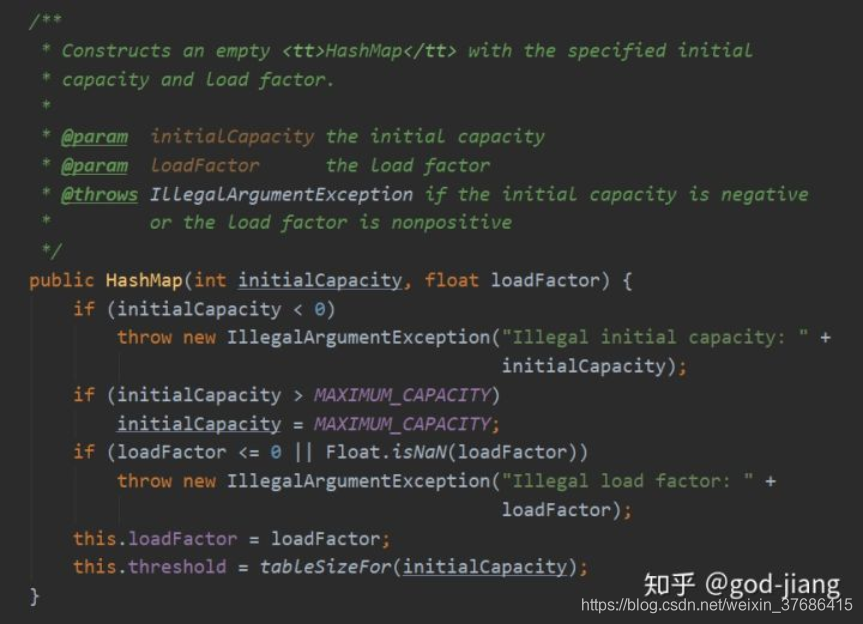
initialCapacity表示的是初始化的容量,默认是1<<4(也就是16);
loadFactor表示的是扩容因子,默认是0.75f(也就是面试常问的3/4)
为啥扩容因子默认是0.75f?(HashMap的源码翻译)

假如你创建HashMap的时候传入一个不是2的幂的初始值,HashMap会把它转换为离它最近的2的幂的值。假设你输入7,HashMap会默认把他转换为8;输入29,会默认帮你转换为32
2、HashMap如何扩容?
当put进去的容量大于初始容量*扩容因子时,进行resize操作,就是把初始容量<<1(就是乘以2)进行扩容。
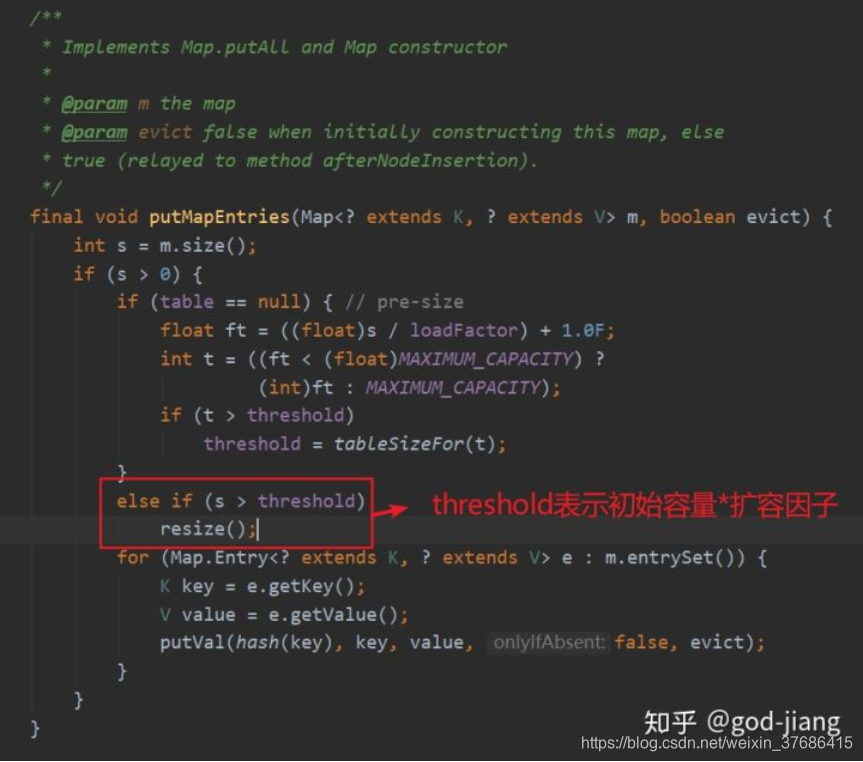
源码太长,只截图一部分。
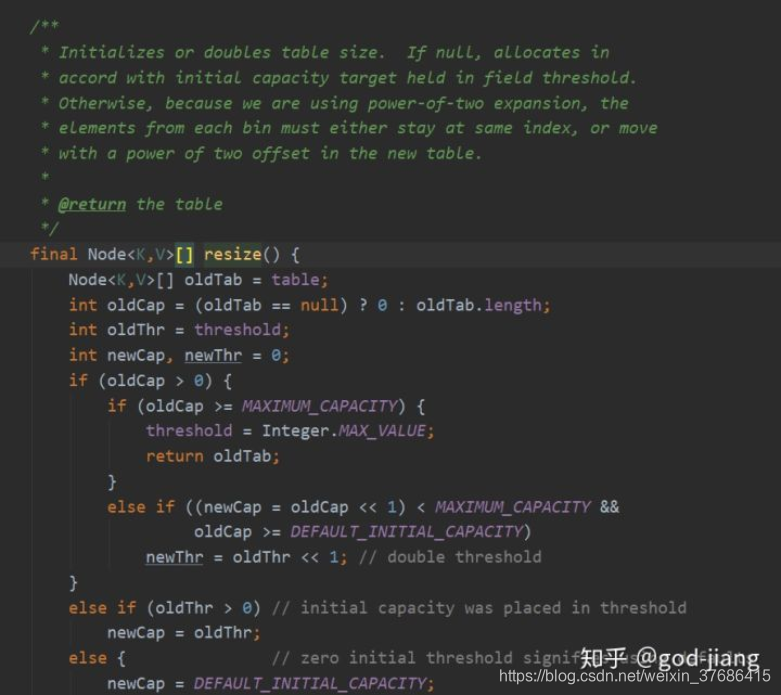
1.7的resize操作和transfer操作在1.8合并为resize操作。
3、HashMap的数组大小为什么一定要是2的幂?
首先先说明数组的大小开辟是在put操作而不是在构造函数阶段,这样为了防止创建HashMap的时候就开辟桶的空间,导致浪费,所以在进行put操作的时候才会开辟空间。
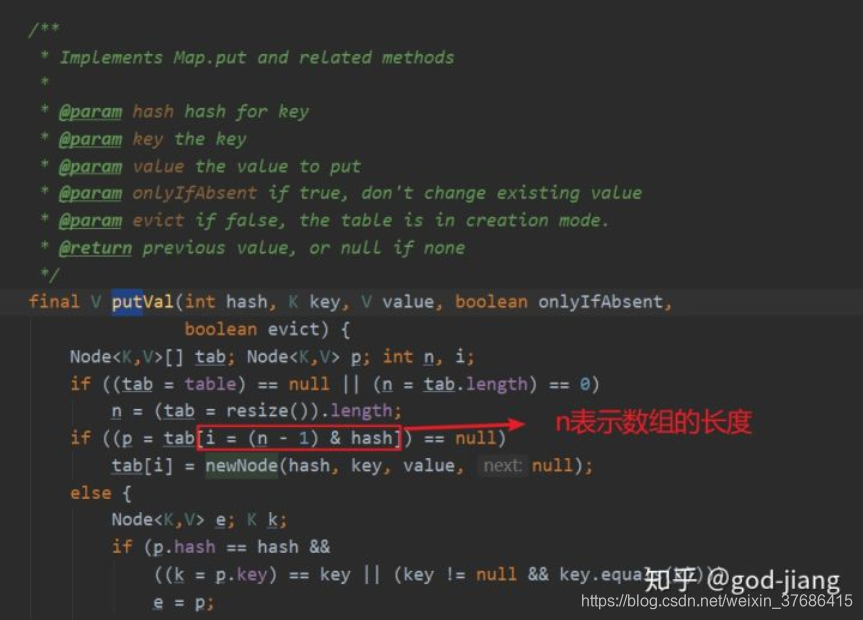
因为hashcode(key)运算完将近有42亿个值,需要均匀的分布在16个桶里面,所以采用的是与运算。
为啥不能用取余操作呢?
- 因为hash%n的话,假设hash算出来是负数,任何负数进行%运算都是负数
- 因为%运算的本质就是不停的使用除法,没有位运算(&)来的效率高
然后就是因为需要用到与运算,假如数组长度不是2的幂会导致与运算完的结果有一部分是0,导致HashMap的不均匀分布。所以数组大小一定要是2的幂。为了使HashMap均匀分布,同时还要提高计算机的运行效率,还要把hash%数组长度改为hash&(数组长度-1)。
4、HashMap为什么是线程不安全的?
HashMap的官方源码用加粗的标签表明了是该实现是不同步的,也就是线程不安全的。要是有大量并发还用HashMap的话,肯定由你们开发者自己背锅。

线程不安全的注释翻译如下:

5、Java7到Java8做了哪些改进?
1、hash算法的计算方式不同。
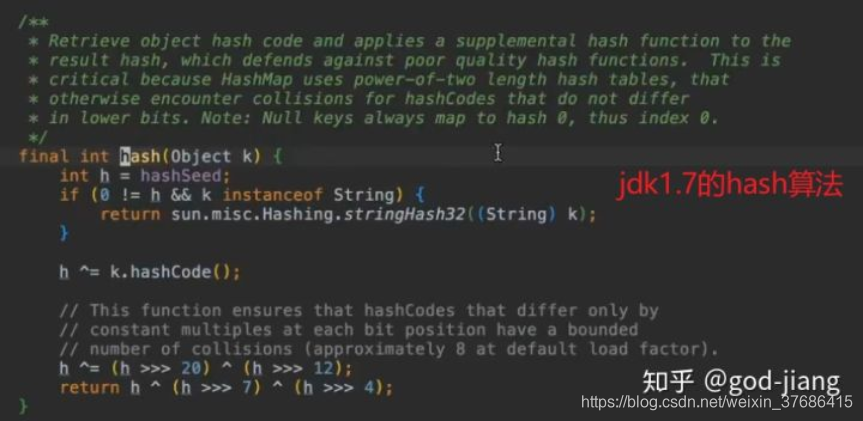
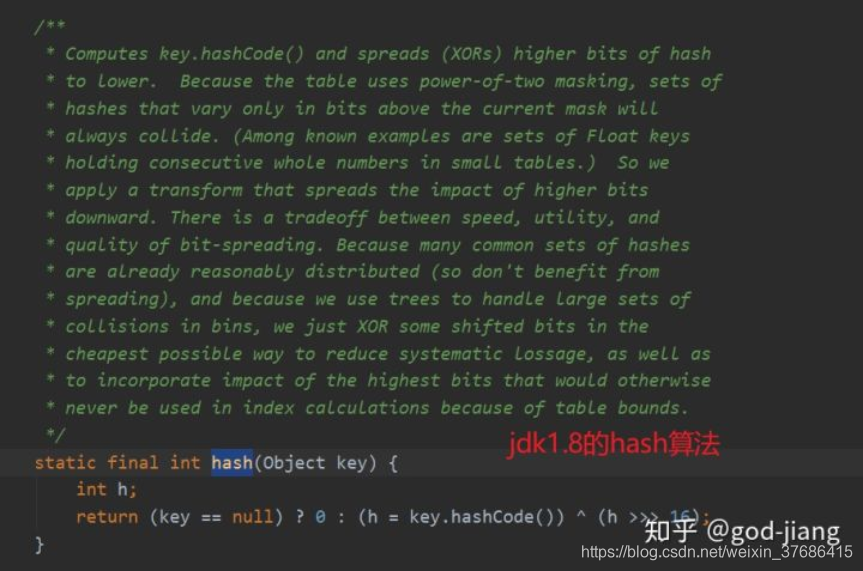
2、jdk1.7的扩容操作在并发场景下会发送死锁现象,在jdk1.8就改进了。对于怎样产生死锁感兴趣的可以去搜“codeshell hashmap”(需要翻墙然后在google上搜索)。其实就rehash的重新插入直接把按照链表的顺序拿下来插入新的链表中。感兴趣的可以google。
3、jdk1.7经典的数组+链表变成了jdk1.8的数组+链表+红黑树
链表的长度阈值到达8就会转换成红黑树。为啥阈值是8?官方给出的源码翻译如下:
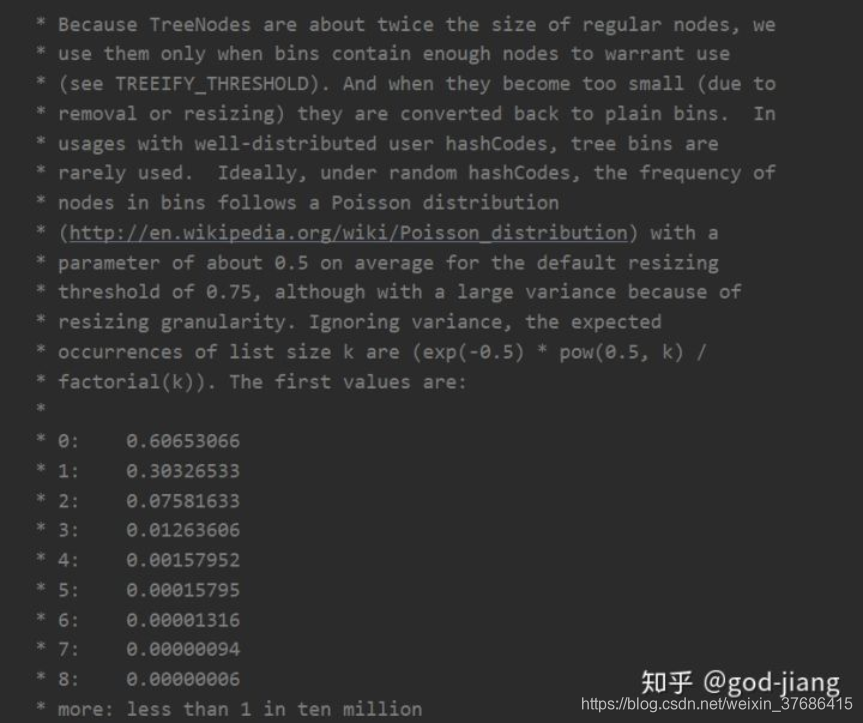

就是到达8的几率已经非常非常接近0了,所以认为几乎不可能达到9,所以阈值设置为8。
PS:以上就是我对HashMap1.7和1.8源码解读所得出来的结论。假如有哪里写得不对的可以指出批评和修改,也可以一起探讨HashMap的学习。
