异常值分析方法
什么叫异常值?
异常值是由于系统误差、人为误差或者固有数据的变异使得他们与总体的行为特征、结构或相关性等不一样,这部分数据称为异常值。
为什么要关注异常值?
异常值检测在数据挖掘中有着重要的意义,比如如果异常值是由于数据本身的变异造成的,那么对他们进行分析,就可以发现隐藏的更深层次的,潜在的,有价值的信息。
如何检测异常值?
异常值检测的方法:
1. 统计学方法对异常值的检测
(1)3σ准则(又叫拉依达准则)
在整理试验数据时,往往会遇到这样的情况,即在一组试验数据里,发现少数几个偏差特别大的可疑数据,这类数据称为Outlier或Exceptional Data,他们往往是由于过失误差引起。对于可疑数据的取舍要慎重。在试验进行中时,若发现异常数据,应立即停止试验,分析原因并及时纠正错误;当为试验结束后时,应先找原因,在对数据进行取舍。这类数据的不能清楚地判定原因时,可以借助一些统计方法进行验证处理。3σ准则就是其中的一种方法。
先假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有该误差的数据应予以剔除就得出3σ。
在正态分布中σ代表标准差,μ代表均值。x=μ即为图像的对称轴。
3σ:数值分布在(μ-σ,μ+σ)中的概率为0.6826;
数值分布在(μ-2σ,μ+2σ)中的概率为0.9544;
数值分布在(μ-3σ,μ+3σ)中的概率为0.9974;
可以认为,Y 的取值几乎全部集中在(μ-3σ,μ+3σ)]区间内,超出这个范围的可能性仅占不到0.3%。

3σ准则是最常用也是最简单的粗大误差判别准则,它一般应用于测量次数充分多( n ≥30)或当 n>10做判别时的情况。
一般是把超过三个离散值的数据称之为异常值。这个方法在实际应用中很方便的使用,但是他只有在单个属性的情况下才适用。
3σ准则的思想其实就是来源于切比雪夫不等式(Chebyshev's inequality)。

当ε=2σ\varepsilon=2\sigmaε=2σ时:所有数据中,至少有3/4(或75%)的数据位于平均数2个标准差范围内。
当ε=3σ\varepsilon=3\sigmaε=3σ时:所有数据中,至少有8/9(或88.9%)的数据位于平均数3个标准差范围内。
当ε=5σ\varepsilon=5\sigmaε=5σ时:所有数据中,至少有24/25(或96%)的数据位于平均数5个标准差范围内。
相对于高斯分布来说,
1σ1\sigma1σ原则:数值分布在(μ—σ,μ+σ)(μ—σ, μ+σ)(μ—σ,μ+σ)中的概率为0.6826
2σ2\sigma2σ原则:数值分布在(μ—2σ,μ+2σ)(μ—2σ, μ+2σ)(μ—2σ,μ+2σ)中的概率为0.9544
3σ3\sigma3σ原则:数值分布在(μ—3σ,μ+3σ)(μ—3σ, μ+3σ)(μ—3σ,μ+3σ)中的概率为0.9974
即:
落入μ±σ\mu\pm\sigmaμ±σ 的概率大约为68.26%
落入μ±2σ\mu\pm2\sigmaμ±2σ 的概率大约为95.44%
落入μ±3σ\mu\pm3\sigmaμ±3σ 的概率高达99.74%
对比正态分布(高斯分布)
3σ准则建立在正态分布的等精度重复测量基础上,造成异常值的干扰或噪声难以满足正态分布。如果一组测量数据中某个测量值的残余误差的绝对值 νi>3σ,则该测量值为坏值,应剔除。
通常把等于 ±3σ的误差作为极限误差,对于正态分布的随机误差,落在 ±3σ以外的概率只有 0。
正态分布图一般是这个样子的:
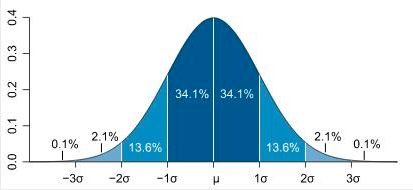

图形特征
集中性:正态曲线的高峰位于正中央,即均数所在的位置。
对称性:正态曲线以均数为中心,左右对称,曲线两端永远不与横轴相交。
均匀变动性:正态曲线由均数所在处开始,分别向左右两侧逐渐均匀下降。
曲线与横轴间的面积总等于1,相当于概率密度函数的函数从正无穷到负无穷积分的概率为1。即频率的总和为100%。
(2)散点图
散点图通常用于比较跨类别的聚合数据。当要在不考虑时间的情况下比较大量数据点时,请使用散点图。散点图中包含的数据越多,比较的效果就越好。
(3)四分位点
四分位数(Quartile)也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。多应用于统计学中的箱线图绘制。它是一组数据排序后处于25%和75%位置上的值。四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据。很显然,中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值(称为下四分位数)和处在75%位置上的数值(称为上四分位数)。与中位数的计算方法类似,根据未分组数据计算四分位数时,首先对数据进行排序,然后确定四分位数所在的位置,该位置上的数值就是四分位数。与中位数不同的是,四分位数位置的确定方法有几种,每种方法得到的结果会有一定差异,但差异不会很大。
四分位数有三个,第一个四分位数就是通常所说的四分位数,称为下四分位数,第二个四分位数就是中位数,第三个四分位数称为上四分位数,分别用Q1、Q2、Q3表示 [2] 。
第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
第三四分位数与第一四分位数的差距又称四分位距(InterQuartile Range,IQR)。
优点:与方差和极差相比,更加不如意受极端值的影响,且处理大规模数据效果很好。
缺点:小规模处理略显粗糙。而且只适合单个属性的检测。
(4)基于分布的异常值检测
本方法是根据统计模型或者数据分布特征,然后根据模型对样本集中的每个点进行不一致检验的方法。
2. 基于距离的异常值检测
3. 基于偏离的异常值检测
假设N的数据集,建立数据子集。求出子集间得相异度,然后确定异常值。
较为复杂,计算量大。不建议使用.
4. 基于分类模型的异常值检测
根据已有的数据,然后建立模型,得到正常的模型的特征库,然后对新来的数据点进行判断。从而认定其是否与整体偏离,如果偏离,那么这个就是异常值。
