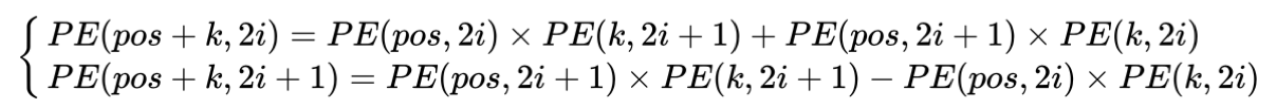目录
Attention机制的原理
- 关键的三个变量 Query, Key, Value,计算 Attention 的过程即使用一个 Query,对所有的 Key 计算相似度,然后根据相似度对 Value 进行加权求和
Attention机制的类别
-
Hard/Soft Attention:Soft Attention是利用注意力分数加权和的方法得到注意力表征,即传统的 Attention 计算。而 Hard Attention 则是一个随机过程,将将注意力分数当作采样概率,对 Value 进行采样,采样过程是无法求导的(即 Soft/Hard 的区别)
-
Local/Globel Attention:区别在于 Local Attention 需要定义一个窗口,最后只加权窗口之内的词信息,而 Globel Attention 则是关注整个上下文的信息。
-
一维匹配/二维匹配:一维匹配模型指的是 Query 直接表征为一个一维向量,注意力分数即为 Query 对 Key 中每个词的注意力分数,这个注意力关系是一个一维匹配的关系;而二维匹配模型则是可以看作有多个 Query 与多个 Key 计算相关分数,是一个 N2N 的二维匹配关系。
双向注意力
- 双向注意力模型即在求得二维匹配矩阵之后,在两个不同方向上的 Softmax 归一化即为两个不同方向上的注意力分数,再利用注意力分数对相应的注意力对象加权即可,得到 context-to-query attention 表征以及 query-to-context atteniton 表征,再通过拼接的方式将其整合为上下文的 query-aware 表征。
Self-Attention 与 Soft-Attention 的区别
- Soft-Attention 中的 Key 和 Query 为不同值,而 Self-Attention 中的 Key, Query 和 Value 为同一个值经过不同的线性变换的
Transformer

Multi-Head Attention 机制
- 多个 Self-Attention 并行堆叠在一起实现多头注意力模型。
- 并行堆叠的意义:通过初始化不同的线性映射矩阵,使得不同的 Self-Attention 能够聚焦在不同的位置,保证最后输出的多个表征具有多方面的自注意力信息。最后将多个 Self-Attention 的输出在词向量维度上拼接,通过一个线性映射将其压缩到原来的词表征维度。
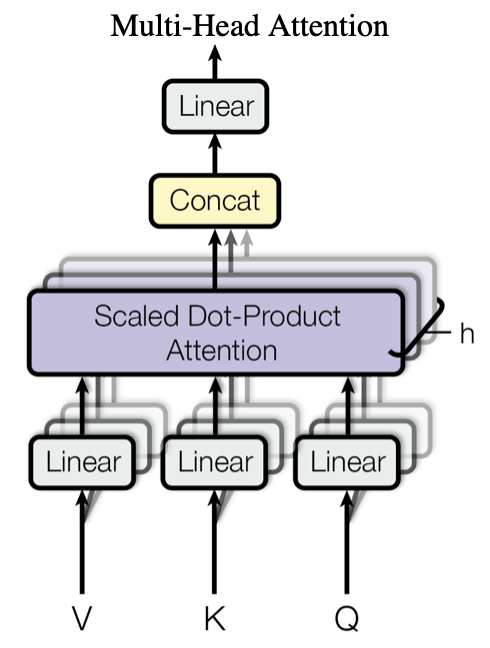
Self-Attention机制
- 输入的 Key、Query 和 Value 向量均为输入序列的线性映射,计算 Key 和 Query 的注意力分数再对 Value 进行注意力加权,实际上是一个对序列自身的注意力加权编码机制
\[Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V \]

Position-wise Feed-Forward Layer
- Feed-Forward Layer 的作用就是将 Multi-Head Attention 输出的向量再投影到一个更大的空间,最后再投影回token向量原来的空间,便于在高维空间中提取需要的信息,激活函数使用ReLU
使用残差连接的部分
- Multi-Head Attention 前后和 Fead Forward 前后
- 残差连接之后还需要进行 Layer Normalization 进行归一化
Transformer Decoder 与 Encoder 之间的区别
- Transformer Decoder Block的结构与Encode Block略有不同,就是在Multi-Head Attention 之前额外添加了一个Masked Multi-Head Attention。
- Masked Attention,就是为了在解码过程中防止句子看到当前解码对象之后的序列,仅须对二维匹配注意力分数矩阵乘上一个下三角矩阵 \(M\) 即可,表明每一个时刻仅能看到过去时刻的解码输出
\[Attention(Q, K, V) = softmax(\frac{QK^T\cdot M}{\sqrt{d_k}})V \]
位置编码
- 在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
- 这样的编码方式包含了相对位置信息,位置为pos+k的词可以由位置为pos和k的词来表示,且可以证明:间隔为k的任意两个位置编码的欧式空间距离是恒等的,只与k有关
\[\begin{cases} PE_{2i}(p)=sin(p/10000^{2i/d_{pos}}) \\ PE_{2i+1}(p)=cos(p/10000^{2i/d_{pos}}) \end{cases}\]
- 相对位置的表示主要与下面的正余弦公式有关
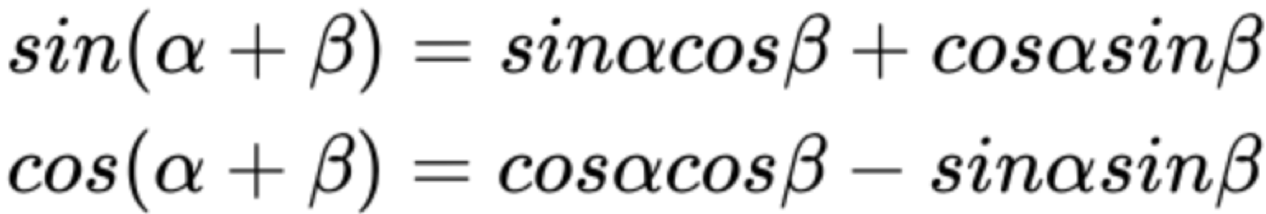
- 因此,可以将 \(PE_{pos}\) 和 \(PE_{pos+k}\) 的关系表示如下: