CVPR2020论文解析:实例分割算法
BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation
论文链接:https://arxiv.org/pdf/2001.00309.pdf

摘要
实例分割是基本的视觉任务之一。近年来,全卷积实例分割方法因其比Mask R-CNN等两阶段方法简单、高效而备受关注。迄今为止,当模型具有相似的计算复杂度时,几乎所有这些方法在掩模精度上都落后于两级掩模R-CNN方法,留下了很大的改进空间。在这项工作中,我们通过有效地将瞬时层信息与具有较低粒度的语义信息相结合来实现改进的掩模预测。本文主要贡献是一个混合模块,它从自上而下和自下而上的实例分割方法中汲取灵感。所提出的BlendMask算法能够有效地预测每像素位置敏感的密集实例特征,并且只需一个卷积层就可以学习到每个实例的注意图,因此推理速度快。BlendMask可以很容易地与最先进的一级检测框架结合起来,并且在相同的训练计划下比Mask R-CNN快20%。轻量级版本的BlendMask在单个1080Ti GPU卡上以25 FPS的速度实现34.2%的mAP。由于它的简单和有效性,我们希望BlendMask可以作为一个简单但强大的基线,用于广泛的实例预测任务。
引论
性能最好的对象检测器和分段器通常遵循两阶段范式。它们由一个完全卷积的网络,区域建议网络(RPN)组成,对最可能感兴趣的区域(roi)进行密集预测。一组轻量级网络,也称为磁头,被应用于重新校准roi的特征并生成预测[24]。掩模生成的质量和速度与头盔的结构有很大的关系。此外,独立的头很难与相关的任务(如语义分割)共享特征,这会给网络架构优化带来麻烦。
一级目标检测的最新进展证明,一级方法(如FCOS)在精度上优于两级方法[25]。使这种单阶段检测框架能够执行密集的实例分割是非常理想的,因为1)仅由常规操作组成的模型更简单,更易于跨平台部署;2)单一框架为多任务网络架构优化提供了方便和灵活性。
密集实例分段器可以追溯到DeepMask[23],这是一种自上而下的方法,通过滑动窗口生成密集实例掩码。掩模的表示在每个空间位置被编码成一维向量。虽然它结构简单,但在训练过程中有几个障碍使其无法获得优异的性能:1)特征与模板之间的局部一致性丢失;2)由于模板在每个前景特征处重复编码,因此特征表示是冗余的;3)
利用步进卷积进行下采样后,位置信息会退化。研究者们试图通过保留多个位置敏感地图来保持局部一致性。这一想法已被Chen等人
[7] ,为目标实例掩码的每个位置提出密集对齐表示。然而,这种方法以代表效率换取一致性,使得第二个问题难以解决。第三个问题是防止大量的降采样特性提供详细的实例信息。
认识到这些困难,一系列研究采取自下而上的策略[1,21,22]。这些方法生成密集的每像素嵌入特征,并使用一些技术对其进行分组。根据嵌入特征,分组策略从简单聚类[4]到基于图的算法[21]各不相同。通过执行逐像素预测,可以很好地保留本地一致性和位置信息。自底向上方法的缺点是:1)严重依赖密集的预测质量,导致性能低于par和分段/联合遮罩;2)对具有大量类的复杂场景的泛化能力有限;3)对复杂后处理技术的要求。
在这项工作中,本文考虑自上而下和自下而上的杂交方法。本文认识到两个重要的前辈,FCIS[18]和YOLACT[3]。它们分别使用裁剪(FCIS)和加权求和(YOLACT)来预测实例级信息,如边界框位置,并将其与逐像素预测相结合。我们认为,这些过于简单的组装设计可能无法很好地平衡顶层和底层功能的表示能力。
更高级别的特征对应于更大的接受域,可以更好地捕获有关姿势等实例的总体信息,而较低级别的特征保留更好的位置信息并可以提供更详细的信息。我们的工作重点之一是研究如何在完全卷积的实例分割中更好地合并这两者。更具体地说,我们通过丰富实例级信息和执行更多的位置敏感掩码预测来概括基于建议的掩码组合操作。我们进行广泛的消融研究,以发现最佳的尺寸、分辨率、对准方法和特征位置。具体来说,我们能够做到以下几点:
•本文设计了一种灵活的基于方案的实例掩码生成方法blender,它结合了丰富的实例级信息和精确的密集像素特征。在头对头比较中,混合器在COCO数据集上的mAP分别比YOLACT[3]和FCIS[18]中的合并技术高出1.9和1.3个点。
•本文提出了一个简单的架构BlendMask,它与最先进的一级目标检测器FCOS[25]紧密相连,在已经简单的框架上增加了最繁重的计算开销。
•BlendMask的一个明显优势是,它的推理时间不会像传统的两阶段方法那样随着预测次数的增加而增加,这使得它在实时场景中更加健壮。
•BlendMask的性能在COCO数据集上,ResNet-50[15]主干和ResNet-101分别达到37.0%和38.4%的mAP,在精度上优于Mask R-CNN[13],而速度快了约20%。本文为全卷积实例分割设置了新的记录,仅用半个训练迭代和1/5的推理时间就在mask映射中超过了TensorMask[7]1.1个点。BlendMask可能是第一个在掩码AP和推理效率方面都优于Mask R-CNN的算法。
•BlendMask可以自然地解决全景分割,而无需任何修改(参见第4.4节),因为底部模块fblendmask同时处理“thingsand stuff”。
•与掩模R-CNN的掩模头(通常为28×28分辨率)相比,BlendMask的底部模块能够输出分辨率更高的掩模,这是因为它的灵活性和底部模块与EFPN紧密相连。ThusBlendMask能够生成边缘更精确的掩模,如图4所示。对于图形等应用程序,这可能非常重要。 •提议的BlendMask一般和流动性。通过最小的修改,我们可以应用BlendMask解决其它实例级的识别任务,如关键点检测。
Related work
无锚对象检测对象检测的最新进展揭示了移除边界盒锚的可能性[25],大大简化了检测管道。这种简单得多的设计与基于锚的RetinaNet相比,盒子平均精度(APbb)提高了2.7%。改进的一个可能原因是,在不受预先确定的锚形状限制的情况下,目标可以根据其有效接收场自由地与预测特征相匹配。给我们的暗示是双重的。首先,用适当的金字塔级别绘制目标尺寸图以确定特征的有效接收区域是很重要的。其次,移除锚使我们能够在不引入整体计算开销的情况下,为顶级实例预测模块分配更重的任务。例如,在边界盒检测的同时推断形状和姿势信息,对于基于锚的框架,所需的计算量大约是我们的8倍。
这使得基于锚的检测器很难平衡顶部和底部的工作负载(即,学习实例awaremaps1 vs.base)。我们假设这可能是在考虑计算复杂性的情况下,给定一个实例,yolact只能为每个原型/基础学习一个标量系数的原因。只有在使用无锚边界盒检测器时,才能消除此限制。
主要的实例分割模式采用两阶段的方法,首先对目标进行检测,然后对每个方案的前景模板进行预测。该框架的成功部分归功于对齐操作roalign[13],它为所有一级自顶向下方法中缺失的第二级RoI头部提供了局部一致性。然而,两阶段框架存在两个问题。对于多实例的复杂场景,两阶段方法的推理时间与实例数成正比。此外,RoI特征和生成的遮罩的分辨率是有限的。本文在第4.3节中详细讨论了第二个问题。
这些问题可以通过用一个简单的裁剪和组装模块替换RoI头来部分解决。在FCIS中,Li等人。[18] 向检测网络中添加一个底部模块,用于预测所有实例共享的位置敏感分数图。这项技术最初用于R-FCN[9],后来在MaskLab[5]中得到改进。k2得分图的每个通道对应于提案的k×k等分网格块的一个裁剪。每个得分图表示像素属于某个对象并处于某个相对位置的可能性。当然,较高的crop定位分辨率会导致更精确的预测,但计算成本也会呈二次增长。此外,在一些特殊情况下,FCIS的代表性并不充分。当两个实例共享中心位置(或任何其他相对位置)时,该裁剪上的分数映射表示不明确,无法判断该裁剪描述的是哪个实例。
在YOLACT[3]中,使用了一种改进的方法。与使用位置控制的并行不同,一组掩模系数与盒子预测一起学习。然后,这组系数指导裁剪的底部掩模底座的线性组合以生成最终掩模。与FCIS相比,预测实例级信息的职责被分配到顶层。我们认为使用标量系数来编码实例信息是次优的。
为了突破这些限制,提出了一个新的基于方案的掩模生成框架BlendMask。顶层和底层表示工作负载由混合模块平衡。这两个级别都保证在其最佳能力范围内描述实例信息。如在第4节中的实验所示,混合模块在不增加计算复杂度的情况下,比YOLACT和FCIS大幅度提高了基础组合方法的性能。
重新定义具有较低级别功能的粗略掩码BlendMask将顶级粗略实例信息与较低级别的精细粒度合并。这个想法类似于MaskLab[5]和Instance Mask Projection(IMP)[10],后者将Mask预测与底层主干特征连接起来。分歧是显而易见的。初级的mask就像一张注意力地图。生成非常轻量级,不需要使用语义或位置监视,并且与对象生成紧密相关。如第3.4节所示,本文的低级功能具有明确的上下文含义,即使没有明确地由bins或作物引导。此外,我们的混合模块不需要像MaskLab[5]和IMP[10]那样的子网,这使得本文的方法更加高效。在这项工作的同时,最近两种单镜头实例分割方法显示出良好的性能[26,27]。
算法原理
Overall pipeline
BlendMask包含检测网络和mask分支,mask分支包含3个部分,bottom
module用于预测score maps,top layer用于预测实例的attentions,blender module用于整合分数以及attentions,整体的架构如图2所示
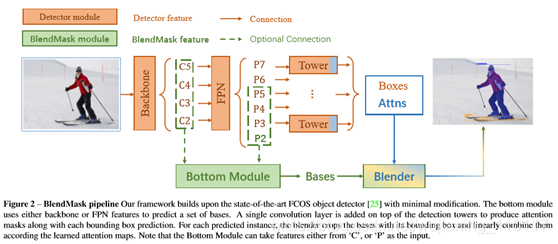
Bottom module
bottom
module预测的score maps在文中称为基底(base)B的大小为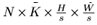 ,其中N为batch size,K为基底的数量,H×W是输入的大小,而s则是score maps的输出步长。
,其中N为batch size,K为基底的数量,H×W是输入的大小,而s则是score maps的输出步长。
论文采用DeepLab V3+的decoder,该decoder包含两个输入,一个低层特征和一个高层特征,对高层特征进行upsample后与低层特征融合输出。这里使用别的结构也是可以的,而bottom module的输入可以是backbone的feature,也可以是类似YOLACT或Panoptic FPN的特征金字塔
Top Layer
在每一个detection tower后接了一层卷积层用来预测top-level
attentionsA。 在YOLACT中,每一层金字塔 输出的A为
输出的A为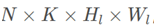 ,即对应基底每个channel的整体的权重值。而论文输出的A为
,即对应基底每个channel的整体的权重值。而论文输出的A为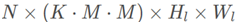 ,M×M是attention的分辨率,即对应基底每个channel的像素点的权重值,粒度更细,是element-wise的操作(后面会讲到)。
,M×M是attention的分辨率,即对应基底每个channel的像素点的权重值,粒度更细,是element-wise的操作(后面会讲到)。
由于attentions是3D结构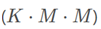 ,因此可以学习到一些实例级别的信息,例如对象大致的形状和姿态。M的值是比较小的,只做粗略的预测,一般最大为14,使用output channel为
,因此可以学习到一些实例级别的信息,例如对象大致的形状和姿态。M的值是比较小的,只做粗略的预测,一般最大为14,使用output channel为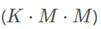 的卷积来实现。在送到一下个模块之前,先使用FCOS post-process方法来选择top D个bboxP=
的卷积来实现。在送到一下个模块之前,先使用FCOS post-process方法来选择top D个bboxP=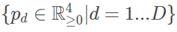 和对应的attentions A=
和对应的attentions A=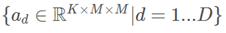 ,具体的选择方法是选择分类置信度≥阈值的top
,具体的选择方法是选择分类置信度≥阈值的top
D个bbox,阈值一般为0.05
Blender module
Blender module是BlendMask的关键部分,根据attentions对位置敏感的基底进行合并输出
Blender
module
blender模块的输入为bottom-level的基底B以及选择的top-level
attentionsA和bboxP
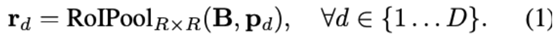
首先,使用Mask
R-CNN的ROIPooler来截取每个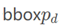 对应的基底区域,并resize成固定R大小的特征图
对应的基底区域,并resize成固定R大小的特征图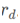 。具体地,使用sampleing
。具体地,使用sampleing
ratio=1的RoIAlign,每个bin只采样1个点,Mask R-CNN每个bin采样4个点。在训练的时候,直接使用gt bbox作为proposals,而在推理时,则直接用FCOS的检测结果
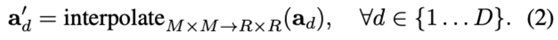
attention大M是比R小的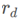 ,因此需要对 进行插值,从M×M变为R×R,R={
,因此需要对 进行插值,从M×M变为R×R,R={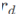 ∣d=1…D}
∣d=1…D}
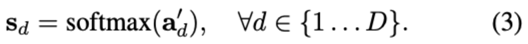
接着对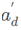 的K维attention分别进行softmax归一化,产生一组score map
的K维attention分别进行softmax归一化,产生一组score map
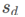
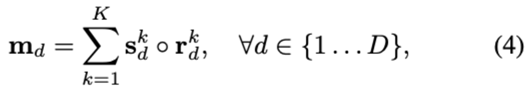
然后对每个regionR的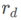 和对应的score mapS的
和对应的score mapS的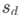 进行element-wise product,最后将K个结果进行相加得到
进行element-wise product,最后将K个结果进行相加得到
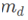
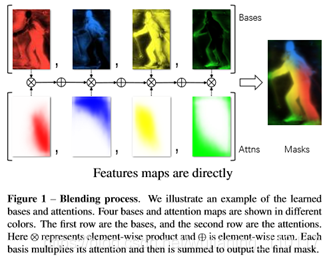
图1对blend module的操作进行了可视化,可以看到attenttions和基底的特征以及融合的过程,可以说十分生动形象了
Configurations
and baselines
BlendMask的超参数如下:
R,bottom-level
RoI的分辨率
M,top-level预测的分辨率
K,基底的数量(channel)
bottom模块的输入可以是骨干网络或FPN的feature
基底的采样方法可以是最近邻或双线性池化
top-level
attentions的插值方法可以是最近邻或双线性采样
论文用缩写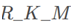 来表示模型,使用骨干特征C3和C5作为bottom模块的输入,top-level attention使用最近邻插值,bottom level使用双线性插值,与RoIAlign一致
来表示模型,使用骨干特征C3和C5作为bottom模块的输入,top-level attention使用最近邻插值,bottom level使用双线性插值,与RoIAlign一致
Semantics
encoded in learned bases and attentions

基底和attentions的可视化结果如图3所示,论文认为BlendMask能提取两种位置信息:
像素是否在对象上(semantic
masks)
像素是否在对象的具体部位上(position-sensitive
features),比如左上角,右下角
红蓝两个基底分别检测了目标的右上和左下部分点,黄色基底则检测了大概率在目标上的点(semantic mask),而绿色基底则激活了物体的边界,position-sensitive features有助于进行实例级别的分割,而semantic
mask则可以对postion-sensitive进行补充,让最后的结果更加顺滑。由于学习到了更多准确的特征,BlendMask使用了比YOLACT和FCIS少很多的基底纬度(4 vs. 32 vs. 49)
Experiment
消融实验
Merging
methods: Blender vs. YOLACT vs. FCIS
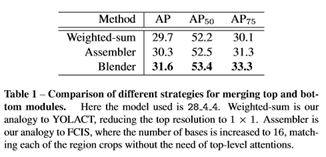
论文将blender改造成其它两个算法的merge模型进行实验,从Table1可以看出,Blender的merge方法要比其它两个算法效果好
Top and
bottom resolutions
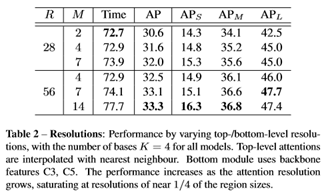
从Table2可以看出,随着resolution的增加,精度越来越高,为了保持性价比,R/M的比例保持大于4,总体而言,推理的时间是比较稳定的
Number of
bases
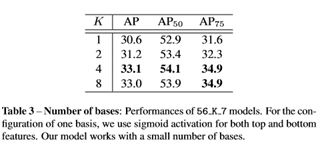
从Table3可以看出,K=4是最优
Bottom
feature locations: backbone vs. FPN
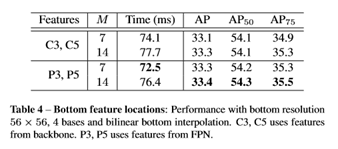
从图4可以看出,使用FPN特征作为bottom模块的输入,不仅效率提升了,推理时间也加快了。
Interpolation
method: nearest vs. bilinear
在对top-level
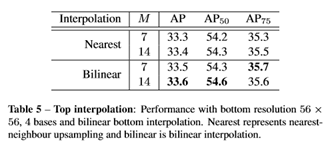
attentions进行插值时,双线性比最近邻高0.2AP
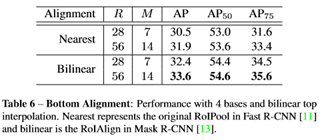
而对bottom-level score
maps进行插值时双线性比最近邻高2AP
Other
improvements

论文也尝试了其它提升网络效果的实验,虽然这些trick对网络有一定的提升,但是没有加入到最终的网络中
Main
result
Quantitative
results
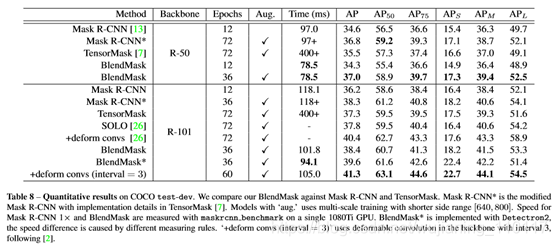
从结果来看,BlendMask在效果和速度上都优于目前的实例分割算法,但是有一点,在R-50不使用multi-scale的情况下,BlendMask的效果要比Mask R-CNN差
Real-time
setting
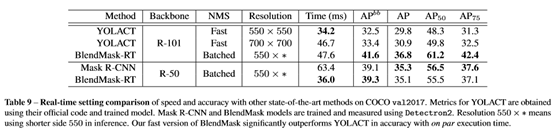
为了跟YOLACT对比,论文改造了一个紧凑版的BlendMask-RT: 1) 减少prediction head的卷积数 2) 合并classification tower和box tower 3) 使用Proto-FPN并去掉P7。从结果来看,BlendMask-RT比YOLACT快7ms且高3.3AP
Qualitative
results

图4展示了可视化的结果,可以看到BlendMask的效果比Mask R-CNN要好,因为BlendMask的mask分辨为56而Mask R-CNN的只有28,另外YOLACT是难以区分相邻实例的,而BlendMask则没有这个问题。
Discussions
Comparison
with Mask R-CNN
BlendMask的结构与Mask
R-CNN类似,通过去掉position-sensitive feature map以及重复的mask特征提取来进行加速,并通过attentions指导的blender来替换原来复杂的全局特征计算
BlendMask的另一个优点是产生了高质量的mask,而分辨率输出是不受top-level采样限制。对于Mask R-CNN增大分辨率,会增加head的计算时间,而且需要增加head的深度来提取准确的mask特征
。另外Mask R-CNN的推理时间会随着bbox的数量增加而增加,这对实时计算是不友好的
最后,blender模块是十分灵活的,因为top-level的实例attention预测只有一个卷积层,对于加到其它检测算法中几乎是无花费的
Panoptic
Segmentation
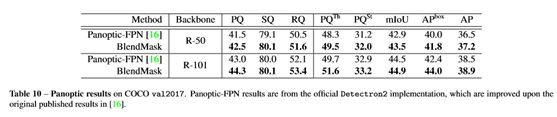
BlendMask可以通过使用Panoptic-FPN的语义分割分支来进行全景分割任务,从结果来看,BlendMask效果更好
总结
BlendMask通过更合理的blender模块融合top-level和low-level的语义信息来提取更准确的实例分割特征,该模型综合各种优秀算法的结构,例如YOLACT,FOCS,Mask R-CNN,比较tricky,但是很有参考的价值。BlendMask模型十分精简,效果达到state-of-the-art,推理速度也不慢,精度最高能到41.3AP,实时版本BlendMask-RT性能和速度分别为34.2mAP和25FPS,并且论文实验做得很充足,值得一读
