慢镜头变焦:视频超分辨率:CVPR2020论文解析
Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video
Super-Resolution

论文链接:https://arxiv.org/pdf/2002.11616.pdf
The source code is released in:https://github.com/Mukosame/ZoomingSlowMo-CVPR-2020
摘要
本文探讨了一种时空视频超分辨率解决方案,该方案旨在从低帧速率(LFR)、低分辨率(LR)视频中生成高分辨率(HR)慢动作视频。一个简单的解决方案是将其分为两个子任务:视频帧插值(VFI)和视频超分辨率(VSR)。然而,在这项任务中,时间插值和空间超分辨率是相互关联的。两阶段法不能充分利用自然属性。此外,目前最先进的VFI或VSR网络需要一个大的帧合成或重建模块来预测高质量的视频帧,这使得两阶段的方法具有较大的模型尺寸,因而非常耗时。为了克服这些问题,我们提出了一种单级时空视频超分辨率框架,它直接从LFR、LRvideo合成HR慢动作视频。而不是合成丢失的LR视频帧与VFI网络一样,我们利用所提出的特征时态插值网络,在捕获本地时态上下文的丢失LR视频帧中,对LR帧特征进行时态插值。然后,我们提出了一个可变形的convlst模型来同时对齐和聚合时间信息,以更好地利用全局时间上下文。最后,采用深度重建网络对HR慢动作视频帧进行预测。在基准数据集上的大量实验表明,该方法不仅能获得更好的定量和定性性能,而且比最近的两阶段最新方法(如DAIN+EDVR和DAIN+RBPN)快3倍以上。
- Introduction
近年来,深卷积神经网络在视频帧内插(VFI)[24]、视频超分辨率(VSR)[4]和视频去模糊(video deblurring)[32]等各种视频恢复任务中显示出良好的效率和效果。要设计STVSR网络,一种直接的方法是以两阶段的方式直接组合视频帧插值方法(例如SepConv[25]、ToFlow[40]、DAIN[1]等)和视频超分辨率方法(例如DUF[11]、RBPN[8]、EDVR[37]等)。它用VFI准确地插入丢失的中间LR视频帧,然后用VSR重建所有HR帧。然而,STVSR中的时间插值和空间超分辨率是相互关联的。把它们分成两个独立过程的两阶段方法不能充分利用这一自然属性。此外,为了预测高质量的视频帧,最先进的VFI和VSR网络都需要一个大的帧重建网络。因此,组合的两级STVSR模型包含大量的参数,计算量大。为了解决上述问题,我们提出了一个单一的单阶段STVSR框架来同时学习时间插值和空间超分辨率。我们建议自适应地学习可变形特征插值函数来对中间LR帧特征进行时间插值,而不是像两阶段方法那样合成像素级LR帧。插值函数中的可学习偏移可以聚集有用的局部时间上下文,帮助时间插值处理复杂的视觉运动。此外,我们还引入了一个新的可变形convlsm模型来有效地利用同时具有时间对齐和聚合的全局上下文。利用一个深度SR重建网络,可以从聚集的LR特征中重建HR视频帧。为此,一级网络可以学习端到端以顺序到顺序的方式将LR、LFR视频序列映射到其HR、HFR空间。实验结果表明,所提出的一级STVSR框架在参数较少的情况下,仍优于现有的两级STVSR方法。一个例子如图1所示。

本文的贡献有三个方面:
(1)
我们提出了一种单级时空超分辨率网络,它可以在一个统一的框架下同时处理时间插值和空间随机共振。利用两个子问题之间的内在联系,我们的一阶段方法比两阶段方法更有效。它的计算效率也更高,因为只需要一个帧重建网络,而不是两个大型网络,如最新的两阶段方法。

(2)
针对中间LR帧,提出了一种基于可变形采样的帧特征时态插值网络。我们设计了一种新的可变形convlst模型来显式地增强时间对齐能力,并利用全局时间上下文来处理视频中的大运动。
(3)
我们的单阶段方法在Vid4[17]和Vimeo[40]上都实现了最先进的STVSR性能。它的速度是两级网络DAIN[1]+EDVR[37]的3倍,同时模型尺寸减少了近4倍。
- Related Work
Video Frame Interpolation
在我们的一级STVSR框架中,我们没有像当前的VFI方法那样合成中间LR帧,而是从两个相邻LR帧插入特征,直接合成丢失帧的LR特征映射,而不需要显式的监控。
Video Super-Resolution
我们提出了一个更为有效的一级框架,该框架不需要简单地将VFI网络和VSR网络相结合来解决STVSR问题,同时学习时间特征插值和空间SR,而无需访问LR中间帧作为监控。
Space-Time Video Super-Resolution
我们提出了一个一级网络来直接学习局部LR观测与HR视频帧之间的映射,从而实现快速、准确的STVSR。
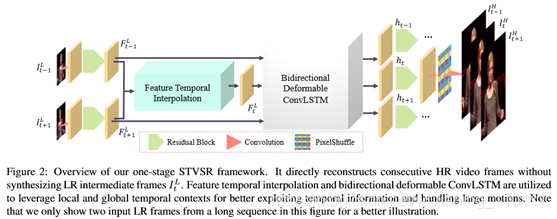
- Space-TimeVideoSuper-Resolution
为了快速准确地提高空间和时间域的分辨率,我们提出了一个单阶段的时空超分辨率框架:如图2所示缩放慢速Mo。该框架主要由四部分组成:特征提取模块、帧特征时间插值模块、可变形convlsm和HR帧重建模块。
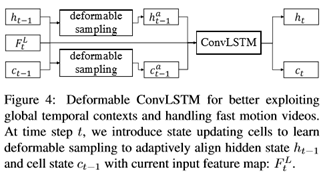
为了解决大运动问题并有效地利用全局时间上下文,我们在convlsm中显式地嵌入了一个具有可变形对齐的状态更新单元(见图4):

- Experiments and Analysis
4.1. Experimental Setup
我们使用Vimeo-90K作为训练集[40],包括超过600007帧的训练视频序列。数据集在以前的VFI和VSR工作中被广泛使用[2,1,35,8,37]。Vid4[17]和Vimeo测试集[40]用作评估数据集。为了测量不同运动条件下不同方法的性能,我们将Vimeo测试集分为快速运动集、中等运动集和慢速运动集,分别包括1225、4977和1613个视频片段。我们从原始的中等运动集中删除了5个视频剪辑,从慢运动集中删除了3个剪辑,这些剪辑具有连续的所有黑色背景帧,这将导致PSNR上的有限值。利用双三次采样因子4生成LR帧,并以奇数索引LR帧作为输入预测相应的连续HR帧和HFR帧。
采用峰值信噪比(PSNR)和结构相似性指数(SSIM)[38]评价不同方法的STVSR性能。为了测量不同网络的效率,我们还比较了在Nvidia Titan XP GPU上测量的整个Vid4[17]数据集的模型大小和推断时间。
4.2. Comparison to State-of-the-art
Methods
我们比较了我们的一级缩放SlowMo网络和由最先进的(SOTA)VFI和VSR网络组成的两级缩放SlowMo网络的性能。比较了三种最新的SOTA-VFI方法SepConv[25]、Super-SloMo4[10]和DAIN[1]。为了实现STVSR,使用了三个SOTA-SR模型(包括单图像SR模型、RCAN[41]和两个最新的VSR模型RBPN[8]和EDVR[37])从原始LR帧和插值LR帧生成HR帧。
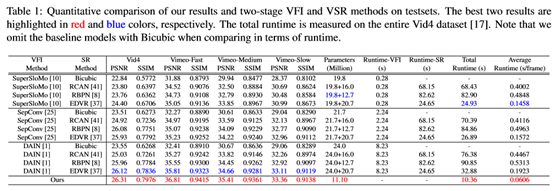
定量结果见表1。从表中我们可以了解到以下事实:
(1) DAIN+EDVR是12种方法中表现最好的两阶段方法;
(2) VFI很重要,特别是对于快速视频。尽管RBPN和EDVR在VSR上的性能远优于RCAN,但是,当配备更先进的VFI网络DAIN时,DAIN+RCAN在Vimeo-Fast上可以达到与SepConv+RBPN和SepConv+EDVR相当甚至更好的性能;
(3) VSR也很重要。
例如,使用相同的VFI网络DAIN,EDVR始终比其他VSR方法获得更好的STVSR性能。此外,我们还可以看到,我们的网络在Vid4上的性能比DAN+EDVR高0.19dB,在Vimeo Slow上的性能比DAN高0.25dB,在Vimeo Medium上的性能比DAN+EDVR高0.75dB,在PSNR的Vimeo Fast interms上的性能比DAN+EDVR高1dB。快速运动视频的显著改进表明,我们同时利用本地和全局时间上下文的一级网络比两级方法更能处理不同的时空模式,包括挑战视频中的大运动。此外,我们还研究了表1中不同网络的模型大小和运行时。为了合成高质量的帧,SOTA-VFI和VSR网络通常具有非常大的帧重建模块。因此,组成的两级SOTA-STVSR网络将包含大量的参数。由于只有一个帧重建模块,我们的一级模型比SOTA两级网络具有更少的参数。
从表1可以看出,它分别比DAIN+EDVR和DAIN+RBPN小4×和3×以上。小型号的网络比DAIN+EDVR快3倍以上,比DAIN+RBPN快8倍以上。与具有快速VFI网络的超低模两级方法相比,我们的方法仍然快2倍以上。
不同方法的可视化结果如图5所示。我们发现我们的方法比其他两个阶段的方法获得了显著的视觉改进。显然,所提出的网络可以合成具有视觉吸引力的HR视频帧,具有更精细的细节、更精确的结构和更少的模糊伪影,即使对于具有挑战性的快速运动视频序列也是如此。我们还观察到目前的SOTA-VFI方法:SepConv和DAIN不能处理大的运动。因此,两级网络容易产生具有严重运动模糊的HR帧。在我们的单阶段框架中,我们在探索自然内在联系的同时学习时间和空间SR。即使使用更小的模型,我们的网络也能很好地解决时间序列中的大运动问题。

4.3. Ablation Study
我们已经展示了我们的一级框架相对于两级网络的优越性。为了进一步证明我们网络中不同模块的有效性,我们进行了全面的融合研究。
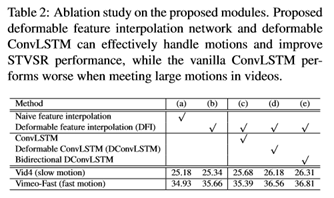
变形特征插值的有效性为了研究提出的变形特征插值(DFI)模块,我们引入了两个基线:
(a)
以及(b)
,其中模型(a)仅使用卷积来混合LR特征,而不使用模型(b)中的可变形采样函数。此外,(a)或(b)都没有convlsm或dconvlsm。从表2中,我们发现(b)在慢动作的Vid4上优于(a)0.16dB,在快动作的VimeoFast上优于(a)0.73dB。图6显示了一个可视化比较。我们可以看到t(a)生成的人脸具有严重的运动模糊,而提出的利用局部时间上下文的变形特征插值可以有效地解决大运动问题,并帮助模型(b)生成具有更清晰的人脸结构和细节的帧。所提出的DFI模块的优越性表明,即使没有任何明确的监控,可变形采样函数中的学习偏移量也能有效地利用局部时间上下文,成功地捕获前向和后向运动。
为了验证所提出的可变形convlsm(dconvlsm)的有效性,我们比较了四种不同的模型:(b),(c),(d)和(e),其中(c)在(b),(d)使用所提出的dconvlsm,和(e)采用双向dconvlsm。从表2可以看出(c)在慢动作视频的Vid4上优于(b),而在快动作序列的Vimeo上则不如(b)。实验结果验证了vanilla-convlsm能够利用有用的全局时间上下文处理慢动作视频,但不能处理视频中的大动作。此外,我们观察到(d)明显优于(b)和(c),这表明我们的dconvlsm能够成功地学习先前状态和当前特征映射之间的时间对齐。
因此,它可以更好地利用全局上下文来重建具有更多细节的视觉愉阈帧。图7中的视觉结果进一步支持我们的发现。此外,我们比较了表2和图8中的(e)和(d)来验证dconvlsm中的双向机制。从表2中,我们可以看出(e)在慢动作和快动作测试集上可以进一步提高STVSR的性能。图8中的可视化结果进一步表明,我们的具有双向机制的完整模型可以通过充分利用所有输入视频帧的全局时间信息来恢复更多的可视化细节。


- Conclusions
本文提出了一种空时视频超分辨率的一级重建框架,在不合成中低分辨率帧的情况下直接重建高分辨率、高帧率的视频。为了实现这一点,我们引入了一种用于特征级时间插值的可变形特征插值网络。此外,我们还提出了一个可变形的convlsm来聚集时间信息和处理动议。通过这种单阶段的设计,我们的网络可以很好地探索任务中时间插值和空间超分辨率之间的内在联系。它使我们的模型能够自适应地学习利用有用的局部和全局时间上下文来缓解大型运动问题。大量实验表明,与现有的两级网络相比,我们提出的一级框架更有效、更高效,而且所提出的特征时间插值网络和变形变换器能够处理非常具有挑战性的快速运动视频。
