视频教学动作修饰语:CVPR2020论文解析
Action Modifiers: Learning from Adverbs in Instructional
Videos

论文链接:https://arxiv.org/pdf/1912.06617.pdf
摘要
我们提出了一种从结构视频中学习副词表达的方法,该方法使用对伴随叙述的弱监督。我们的方法的关键是,副词的视觉表现高度依赖于它所适用的动作,尽管同一个副词会以类似的方式修改多个动作。例如,虽然“快速传播”和“快速混合”看起来不一样,但我们可以学习一种通用表示法,它允许我们在其他动作中同时识别这两种动作。我们将其描述为一个嵌入问题,并利用标度点积注意从弱监督视频叙述中学习。我们共同学习副词作为在嵌入空间上操作的可逆变换,以增加或消除副词的效果。由于目前还没有关于弱监督副词学习的研究,我们从How-To-100M数据集中收集了6个副词的成对动作副词注释:快/慢、粗/粗、部分/完全。该方法在视频副词检索中的性能优于所有基线,达到了0.719map。我们还演示了我们的模型处理相关视频部分的能力,以便确定给定动作的副词。
- Introduction
教学视频是一种受欢迎的媒体类型,全世界数百万人观看它来学习新技能。之前的几部作品旨在从这些视频中学习完成任务所需的关键步骤[1,30,45,62]。然而,确定这些步骤或它们的顺序并不是一个人完成任务所需要的全部;有些步骤需要以某种方式执行才能达到预期的结果。例如,做一个蛋白酥饼的任务。专家会向你保证逐渐加入糖是非常重要的,并通过轻轻折叠混合物来避免打过头。这与最近评估日常任务执行情况的工作有关[10,11,26],然而,这些工作并没有评估个人行为,也没有确定是否按照食谱的建议执行过。与前面的例子一样,带有此类警告的步骤通常由描述应该如何执行操作的副词表示。这些副词(如快速、温和等)概括成不同的动作,并改变动作的方式。因此,我们将其作为动作修改器来学习(图1)。
为了学习各种任务和动作的动作修改器,我们利用在线教学视频资源和附带的叙述。然而,这种形式的监督是软弱和喧嚣的。不仅叙述与视频中的动作大致一致,而且通常叙述的动作可能无法在视频中全部捕获。例如,YouTube的教学视频可能会被描述为“快速倒入奶油”,但视觉效果只显示已经添加的奶油。在这种情况下,视频对学习副词“快”没有帮助。
作为本文的主要贡献,我们建议第一种弱监督学习副词的方法,将相关的视频片段嵌入到一个潜在的空间中,在这个空间中学习副词作为转换。我们从HowTo10000M数据集中任务子集的叙述中收集动作副词标签[33]。该方法对视频副词检索和视频副词检索进行了评估,并显示出比基线显著的改进。此外,我们提出了一项全面的消融研究,证明共同学习良好的动作嵌入是学习动作修改者的关键。

- Related Work
Instructional Videos
在这项工作中,我们提供了一个新颖的见解,如何使用这些教学视频超越步骤识别。我们的工作利用了最近发布的HowTo1亿数据集[33]中的视频,学习副词及其与这些任务中关键步骤的相关性。
Learning from Parts-of-Speech in Video
这项工作使用包括动作边界框在内的全面监督。相反,在这项工作中,我们的目标副词代表的方式,一个行动是执行,只使用微弱的监督从叙述。
Object Attributes in Images
虽然有些作品学习动作的属性[28、43、58],但这些作品检测特定属性的组合(例如“户外”、“使用牙刷”)以执行零镜头识别,而不将副词视为属性。
Weakly Supervised Embedding
在我们的工作中,我们同时嵌入视频的相关部分,同时学习副词如何修饰动作。
- Learning Action Modifier
输入到我们的modela反应副词叙述和附带的教学视频。图2(a)显示了一个结构视频示例,用“…从快速滚动柠檬开始…”进行叙述,从中我们可以快速识别动作滚动和副词(见Sec. 3.4了解NLP详细信息)。经过训练,我们的模型能够评估在测试集中,相同或不同动作的视频,在学习副词的过程中,是否得到了快速的实现。我们在图2中概述了我们的方法。我们学习如图2(b)所示的联合视频文本嵌入,其中相关视频部分嵌入(蓝点)接近副词修饰动作“快速滚动”(黄点)的文本表示。我们回顾了联合视频文本嵌入通常是如何在
Sec. 3.1中训练。本节还介绍了本文其余部分的注释。学习问题的嵌入存在两个主要挑战,即从教学视频中的副词学习。首先是将动作的表示与副词分开,让我们了解同一个副词如何应用于不同的动作。我们建议学习副词作为动作修饰语,每个副词一个,如图2(c)所示。Sec. 3.2我们介绍了这些动作修改器,我们将其表示为嵌入空间中的变换。第二个挑战是以弱监督的方式从视频的相关部分学习视觉表示,即没有时间界限的注释。Sec. 3.3提出了一种利用多头标度点积注意的弱监督嵌入函数。这使用动作的文本嵌入作为查询来关注相关的视频部分,如图2(d)所示。
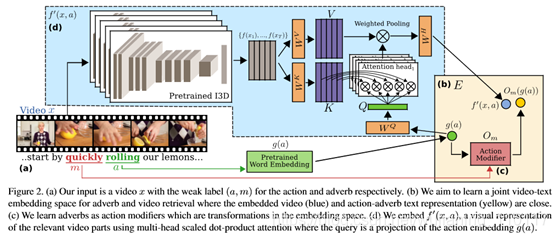
3.1. Learning an Action Embedding
我们的基本模型是一个联合视频文本嵌入,如[32,52,54]。具体地说,给定一组具有对应动作标签a∈a的视频片段x∈x,我们的目标是获得两个嵌入函数,一个视觉的,一个文本的,f:x→E和g:a→E,使得f(x)和g(a)在嵌入空间E中很接近,f(x)与其他动作嵌入g(a)很遥远。
3.2. Modeling Adverbs as Action Modifiers
虽然动作没有副词,但副词是通过与动作相关联的定义而存在的,只有与动作相关联时才能获得视觉表现。虽然副词对不同的动作有着相似的作用,但视觉表征对动作的依赖性很强。因此,我们遵循文献[36]关于视频文本嵌入空间E(Sec3.1)中对象-属性对和模型副词作为学习转换的先前工作。当这些转换修改动作的嵌入时,我们称之为动作修改器。
3.3. Weakly Supervised Embedding
从图像中学习对象属性的所有先前工作[7、20、34、36、37]都利用完全注释的数据集,其中属性所涉及的对象是图像中唯一感兴趣的对象。相比之下,我们的目标是以弱监督的方式从视频中学习动作修改器。我们的输入是包含多个连续动作的未剪辑视频。为了学习副词,我们只需要从与动作相关的视频部分(如图2示例中的“roll”)进行视觉表示。我们建议使用缩放点积注意[49],其中嵌入的感兴趣的动作充当查询来识别相关视频部分。
3.4. Weakly Supervised Inference
经过训练,我们的模型可以用来评估视频和副词的跨模态检索。对于从视频到副词的检索,我们考虑视频查询x和叙述动作a,我们希望估计副词m。例如,我们有一个视频,希望确定动作“切片”的执行方式。对于这两种情况,我们都可以使用a查询弱监督嵌入,以便处理相关的视频部分。
- Dataset
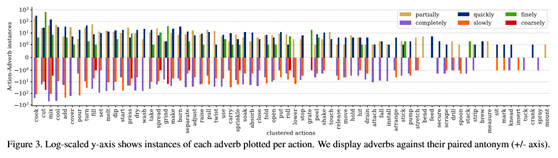
图4显示了从流水线获得的(动作、副词)对与相应视频片段的示例。此外,我们还手动过滤不可见的动作和副词,例如“推荐”和“正常”。我们探索了诸如单词具体程度评分等自动方法[5],但发现这些方法是不可靠的。我们还将动词分组,以避免出现[8]中的同义词,也就是说,我们认为“put”和“place”是同一个动作。通过这个过程,我们得到了15266个动作副词对的实例。然而,这些副词有一个长长的尾巴,只有少数几次被提及。我们把学习限制在6个常用副词上,这6个副词有3对反义词:“部分地”、“完全地”、“快速地”、“缓慢地”和“完全地”、“粗略地”。这些副词出现在263个独特的动作副词对中,有72个不同的动作。我们给出了分布函数。当我们的训练有噪音时,也就是说,动作不能出现在视频中(参见图4底部),我们会清理测试集,以便对方法进行准确评估。我们只考虑动作副词出现在视频中并且出现在叙述时间戳周围20秒内的测试集视频。这相当于原始测试集的44%,与作者在[33]中报告的50%噪声水平相当。结果训练中有5475个动作副词对,测试中有349个动作副词对。我们认为动词和副词之间的平均时间戳是对动作位置的弱监控。这些动作副词弱时间戳注释和伴随代码是公开可用的2。

- Experiments Results
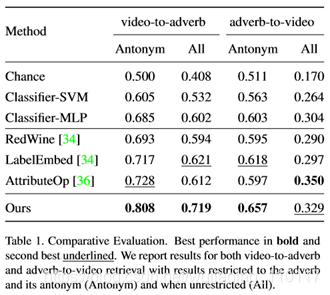
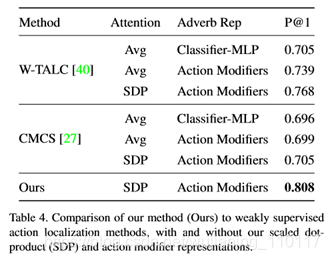
比较结果见表1。在视频副词检索中,无论是与所有副词进行比较还是将评价限制在反义词对上,我们的方法都优于所有的基线。我们看到AttributeOp是最好的基线方法,通常比RedWine和LabelEmbed都表现得更好。后两种方法在固定的视觉特征空间中工作,因此当特征在该空间中不可分离时容易出错。我们还可以看到,LabelEmbed在所有指标上的表现都优于RedWine,这表明GloVe特征比支持向量机分类权重的表现更好。虽然AttributeOp在视频“All”副词上的表现略好于我们的方法,但它在所有其他指标上的表现都不如我们,包括我们的主要目标,即在视频查询的反义词上估计正确的副词。
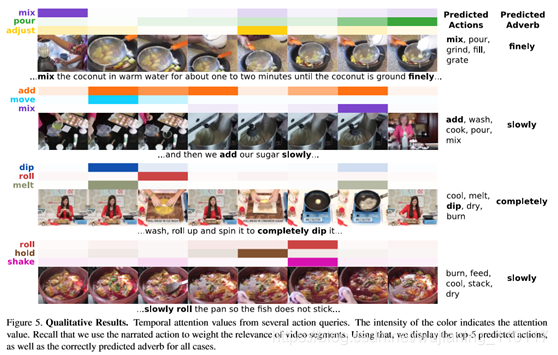
图5示出了视频示例。对于每一个,我们展示了几个动作查询的注意权重。我们的方法能够成功地处理与各种查询操作相关的段。图中还显示了预测动作和预测副词,当使用基本事实动作作为查询时。我们的方法能够预测正确的副词。在最后一个例子中,预测的动作是不正确的,但是该方法正确地识别了相关的片段,并且动作是“缓慢”完成的。我们提供了进一步的见解,学习嵌入空间的补充。
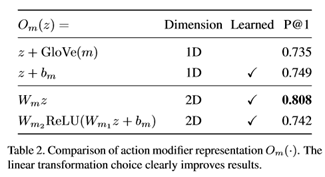
在表2中,我们研究了不同的动作修改器表示(式2)。我们比较了从副词(m)的GloVe式表示(未习得)到三种习得式表示的固定翻译。首先,使用从GloVe嵌入初始化的学习翻译向量bm。第二,我们选择的表示形式是矩阵Wm的二维线性变换,如式2所示。第三,我们学习了一个非线性转换实现为两个完全连接的层,第一个与ReLU激活。结果表明,线性变换明显优于矢量变换和非线性变换。翻译向量没有足够的能力来表示副词的复杂性,而非线性转换则容易出现过切现象。
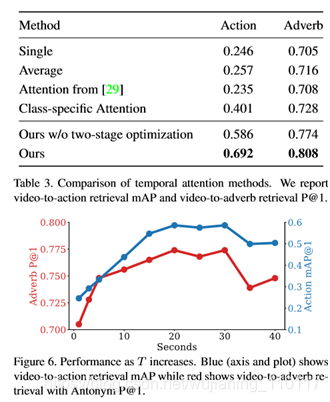
在表3中,我们比较了我们提出的多头标度点积注意(Sec. 3.3)采用时间聚集和注意力的替代方法。在这个比较中,我们还报告了动作检索结果,用视频到动作的映射。
在图6中,我们评估在弱时间戳周围提取的视频的长度(T)如何影响模型(Sec. 3.3)。对于较大的T,视频更可能包含相关动作,但也包含其他动作。我们的嵌入函数f0(x,a)能够忽略视频中的其他动作,直到某一点,并成功地学会关注给定查询动作的相关部分,从而在T∈{20。。30}。
- Conclusions
本文提出了一种弱监督的教学视频副词学习方法。我们的方法学习使用叙述动作作为查询,获取并嵌入具有缩放点积注意的视频相关部分。然后,该方法将动作修改器学习为嵌入动作的线性变换;在动作之间共享。我们对83个任务的YouTube视频中的动作副词对进行了分析,并对分析后的方法进行了训练和评估。结果表明,在考虑副词与反义词的对比时,该方法优于所有基线,达到了视频副词检索的0.808映射。今后的工作将包括从少数镜头示例中学习,以便表示更多种类的副词,并探索应用程序,以便在教学视频或书面说明的指导下向人们提供反馈。
