题目链接
给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A。
例如,如果这个列表是 [“time”, “me”, “bell”],我们就可以将其表示为 S = “time#bell#” 和 indexes = [0, 2, 5]。
对于每一个索引,我们可以通过从字符串 S 中索引的位置开始读取字符串,直到 “#” 结束,来恢复我们之前的单词列表。
那么成功对给定单词列表进行编码的最小字符串长度是多少呢?
示例:
输入: words = ["time", "me", "bell"]
输出: 10
说明: S = "time#bell#" , indexes = [0, 2, 5] 。
题解方法用的是讲解里的字典法。
字典法本身比较好理解,将每个单词倒着把字母一次存入树中。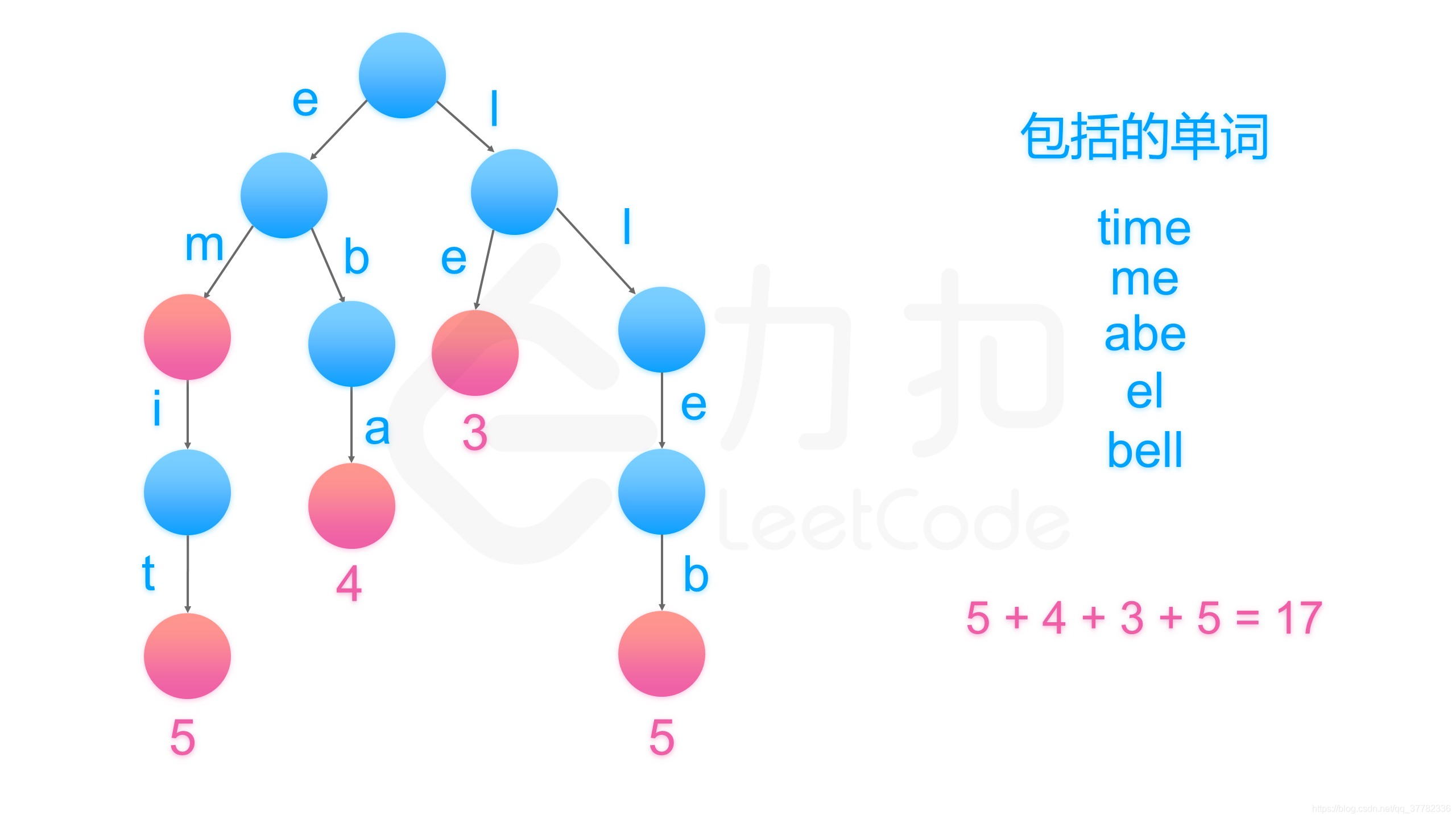
但在看完代码最后的for循环时懵了——
for (auto& [node, idx] : nodes) {
if (node->count == 0) {
ans += words[idx].length() + 1;
}
}
这循环咋个用的,哈希表存的不是字母结尾或者开头吗??
看了会儿才想明白,它的哈希表nodes里存的键值对,键是每个单词开头字母节点的指针,且第一次创建该节点时对应的count=0。而值并不是字母表,而是每个单词在vector里的位置。
上图中的粉色节点才是存在哈希表nodes里的东西
到这里才是真的搞清楚了做法,但感觉自己去想依旧很难想象,还是得多做题。
代码如下:
class TrieNode {
TrieNode* children[26];
public:
int count;
TrieNode() {
for (int i = 0; i < 26; ++i) children[i] = NULL;
count = 0;
}
TrieNode* get(char c) {
if (children[c - 'a'] == NULL) {
children[c - 'a'] = new TrieNode();
count++;
}
return children[c - 'a'];
}
};
class Solution {
public:
int minimumLengthEncoding(vector<string>& words) {
TrieNode* trie = new TrieNode();
unordered_map<TrieNode*, int>nodes;
int si = words.size();
for (int i = 0; i < si; i++) {
string word = words[i];
TrieNode* cur = trie;
for (int j = word.length() - 1; j >= 0; --j)
cur = cur->get(word[j]);
nodes[cur] = i;
}
int ans = 0;
for (auto iter : nodes) {
if (iter.first->count == 0) {
ans += words[iter.second].length()+1;
}
}
return ans;
}
};
