提前说明一下,本文的CNN神经网络模型是参考网上诸多相关CNN图像分类大牛的博客修改的,在模型的基础上,用python的Flask框架搭载了一个web页面用来可视化展示。
第一步,爬取图片数据集
用python实现了一个非常简单的网络爬虫,对百度图片接口 http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%AB%98%E6%B8%85%E5%8A%A8%E6%BC%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=%E4%BA%8C%E6%AC%A1%E5%85%83&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=60&rn=30&gsm=1000000001e&1486375820481= 发送Http请求,返回Json串如下:

我们可以看到,data下的middleURL就是 我们想要的图片链接。于是,再向这个图片链接发请求,就可以获取到我们想要的图片了。代码如下:
# _*_ coding:utf-8 _*_
''''''
'''
1.通过关键字进入图片界面
2.加载图片
queryWord:可爱图片
word:可爱图片
pn:60
gsm:3c
'''
import requests
import json
import time
import os
#要修改的参数列表
queryWord=input('请输入您要搜索的图片:')
pn=0
gsm=str(hex(pn))[-2:]
timestrp=int(time.time()*1000)
#num表示照片数量
num=1
#while实现类似翻页功能,遍历所有图片信息
while True:
#请求的url
url='https://image.baidu.com/search/acjson?' \
'tn=resultjson_com&ipn=rj&ct=201326592&' \
'is=&fp=result&queryWord={0}&cl=2&lm=-1&ie=utf-8&' \
'oe=utf-8&adpicid=&st=-1&z=&ic=0&word={0}&s=&se=' \
'&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn={1}&rn=30&gsm={2}&{3}='
#伪装头部
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'
}
#解析为json()语句
try:
r_mus=requests.get(url.format(queryWord,pn,gsm,timestrp),headers=header).json()
except BaseException as e:
print("此处有错误%s"%e)
print(r_mus)
#遍历每一张图片信息
for image in r_mus['data']:
if image:
#获取图片地址
i_url=image['middleURL']
#请求该地址
r_img=requests.get(i_url,headers=header,stream=True).raw.read()
print('正在读取第{}张图片'.format(num))
num+=1
time.sleep(0.7)
#创建pictures目录
if os.path.exists('data/other/'):
pass
else:
os.mkdir('data/other/')
#保存图片到文件夹pictures
with open('data/other/'+str(int(time.time()))+'.jpg','wb')as files:
files.write(r_img)
listNum = r_mus['listNum']
if listNum>pn:
pn+=30
gsm = str(hex(pn))[-2:]
time.sleep(5)
else:
break
第二步,训练模型
模型借鉴的网上大佬 的博客模型。数据使用了一部分自己的数据集,一部分开源的花卉数据集。对模型进行训练,把训练好的模型放在model文件夹下
具体代码如下:
from skimage import io,transform
import glob
import os
import tensorflow as tf
import numpy as np
import time
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
#读取花朵图片
def read_img(path):
cate=[path+x for x in os.listdir(path) if os.path.isdir(path+x)]
imgs=[]
labels=[]
for idx,folder in enumerate(cate):
print('reading the dirs :%s' % (folder))
for im in glob.glob(folder+'/*.jpg'):
img=io.imread(im)
img=transform.resize(img,(w,h))
imgs.append(img)
labels.append(idx)
return np.asarray(imgs,np.float32),np.asarray(labels,np.int32)
def inference(input_tensor, train, regularizer):
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable("weight",[5,5,3,32],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("bias", [32], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope("layer2-pool1"):
pool1 = tf.nn.max_pool(relu1, ksize = [1,2,2,1],strides=[1,2,2,1],padding="VALID")
with tf.variable_scope("layer3-conv2"):
conv2_weights = tf.get_variable("weight",[5,5,32,64],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("bias", [64], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
with tf.name_scope("layer4-pool2"):
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
with tf.variable_scope("layer5-conv3"):
conv3_weights = tf.get_variable("weight",[3,3,64,128],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv3_biases = tf.get_variable("bias", [128], initializer=tf.constant_initializer(0.0))
conv3 = tf.nn.conv2d(pool2, conv3_weights, strides=[1, 1, 1, 1], padding='SAME')
relu3 = tf.nn.relu(tf.nn.bias_add(conv3, conv3_biases))
with tf.name_scope("layer6-pool3"):
pool3 = tf.nn.max_pool(relu3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
with tf.variable_scope("layer7-conv4"):
conv4_weights = tf.get_variable("weight",[3,3,128,128],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv4_biases = tf.get_variable("bias", [128], initializer=tf.constant_initializer(0.0))
conv4 = tf.nn.conv2d(pool3, conv4_weights, strides=[1, 1, 1, 1], padding='SAME')
relu4 = tf.nn.relu(tf.nn.bias_add(conv4, conv4_biases))
with tf.name_scope("layer8-pool4"):
pool4 = tf.nn.max_pool(relu4, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
nodes = 6*6*128
reshaped = tf.reshape(pool4,[-1,nodes])
with tf.variable_scope('layer9-fc1'):
fc1_weights = tf.get_variable("weight", [nodes, 1024],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc1_weights))
fc1_biases = tf.get_variable("bias", [1024], initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if train: fc1 = tf.nn.dropout(fc1, 0.5)
with tf.variable_scope('layer10-fc2'):
fc2_weights = tf.get_variable("weight", [1024, 512],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc2_weights))
fc2_biases = tf.get_variable("bias", [512], initializer=tf.constant_initializer(0.1))
fc2 = tf.nn.relu(tf.matmul(fc1, fc2_weights) + fc2_biases)
if train: fc2 = tf.nn.dropout(fc2, 0.5)
with tf.variable_scope('layer11-fc3'):
fc3_weights = tf.get_variable("weight", [512, 5],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc3_weights))
fc3_biases = tf.get_variable("bias", [5], initializer=tf.constant_initializer(0.1))
logit = tf.matmul(fc2, fc3_weights) + fc3_biases
return logit
def minibatches(inputs=None, targets=None, batch_size=None, shuffle=False):
assert len(inputs) == len(targets)
if shuffle:
indices = np.arange(len(inputs))
np.random.shuffle(indices)
for start_idx in range(0, len(inputs) - batch_size + 1, batch_size):
if shuffle:
excerpt = indices[start_idx:start_idx + batch_size]
else:
excerpt = slice(start_idx, start_idx + batch_size)
yield inputs[excerpt], targets[excerpt]
def semantic_alignment(src_feature, tgt_feature, src_label, tgt_label, num_classes=2):
'''
input:
src_feature: feature from source domain
tgt_feature: feature from target somain
src_label: source label(one-hot encoding)
tgt_label: target label(one-hot encoding)
num_classes : the number of class(e.g., 2)
output:
semantic_loss : the semantic loss between domains.
'''
source_result = tf.argmax(src_label, 1) # source label
target_result = tf.argmax(tgt_label, 1) # target label
ones = tf.ones_like(src_feature)#得到一个与源域数据格式一致的全1的张量
print('ones',ones.shape)
print('source_result', source_result.shape)
print('target_result', target_result.shape)
current_source_count = tf.unsorted_segment_sum(ones, source_result, num_classes)#计算出当前源域数据
current_target_count = tf.unsorted_segment_sum(ones, target_result, num_classes)#计算出当前目标域数据
current_positive_source_count = tf.maximum(current_source_count, tf.ones_like(current_source_count))#返回当前源域数据与之间的最大值
current_positive_target_count = tf.maximum(current_target_count, tf.ones_like(current_target_count))#返回当前目标域数据与之间的最大值
current_source_centroid = tf.divide(tf.unsorted_segment_sum(data=src_feature, segment_ids= \
source_result, num_segments=num_classes), current_positive_source_count)
current_target_centroid = tf.divide(tf.unsorted_segment_sum(data=tgt_feature, segment_ids= \
target_result, num_segments=num_classes), current_positive_target_count)
semantic_loss = tf.reduce_mean((tf.square(current_source_centroid - current_target_centroid)))
return semantic_loss
if __name__ == '__main__':
# 数据集地址
path = 'D:/python/workspace/flower/data/flowers/'
# 模型保存地址
model_path = 'D:/python/workspace/flower/model/model.ckpt'
#测试集地址
path1= 'D:/python/workspace/flower/test1/'
# 将所有的图片resize成100*100
w = 100
h = 100
c = 3
data, label = read_img(path)
newlabel=[]
# 打乱顺序
num_example = data.shape[0]
arr = np.arange(num_example)
np.random.shuffle(arr)
data = data[arr]
label = label[arr]
# 将所有数据分为训练集和验证集
ratio = 0.8
s = np.int(num_example * ratio)
x_train = data[:s]
y_train = label[:s]
x_val = data[s:]
y_val = label[s:]
# -----------------构建网络----------------------
# 占位符
x = tf.placeholder(tf.float32, shape=[None, w, h, c], name='x')
y_ = tf.placeholder(tf.int32, shape=[None, ], name='y_')
def inference(input_tensor, train, regularizer):
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable("weight", [5, 5, 3, 32],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("bias", [32], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope("layer2-pool1"):
pool1 = tf.nn.max_pool(relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="VALID")
with tf.variable_scope("layer3-conv2"):
conv2_weights = tf.get_variable("weight", [5, 5, 32, 64],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("bias", [64], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv2_weights, strides=[1, 1, 1, 1], padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
with tf.name_scope("layer4-pool2"):
pool2 = tf.nn.max_pool(relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
with tf.variable_scope("layer5-conv3"):
conv3_weights = tf.get_variable("weight", [3, 3, 64, 128],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv3_biases = tf.get_variable("bias", [128], initializer=tf.constant_initializer(0.0))
conv3 = tf.nn.conv2d(pool2, conv3_weights, strides=[1, 1, 1, 1], padding='SAME')
relu3 = tf.nn.relu(tf.nn.bias_add(conv3, conv3_biases))
with tf.name_scope("layer6-pool3"):
pool3 = tf.nn.max_pool(relu3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
with tf.variable_scope("layer7-conv4"):
conv4_weights = tf.get_variable("weight", [3, 3, 128, 128],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv4_biases = tf.get_variable("bias", [128], initializer=tf.constant_initializer(0.0))
conv4 = tf.nn.conv2d(pool3, conv4_weights, strides=[1, 1, 1, 1], padding='SAME')
relu4 = tf.nn.relu(tf.nn.bias_add(conv4, conv4_biases))
with tf.name_scope("layer8-pool4"):
pool4 = tf.nn.max_pool(relu4, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
nodes = 6 * 6 * 128
reshaped = tf.reshape(pool4, [-1, nodes])
with tf.variable_scope('layer9-fc1'):
fc1_weights = tf.get_variable("weight", [nodes, 1024],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc1_weights))
fc1_biases = tf.get_variable("bias", [1024], initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if train: fc1 = tf.nn.dropout(fc1, 0.5)
with tf.variable_scope('layer10-fc2'):
fc2_weights = tf.get_variable("weight", [1024, 512],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc2_weights))
fc2_biases = tf.get_variable("bias", [512], initializer=tf.constant_initializer(0.1))
fc2 = tf.nn.relu(tf.matmul(fc1, fc2_weights) + fc2_biases)
if train: fc2 = tf.nn.dropout(fc2, 0.5)
with tf.variable_scope('layer11-fc3'):
fc3_weights = tf.get_variable("weight", [512, 5],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc3_weights))
fc3_biases = tf.get_variable("bias", [5], initializer=tf.constant_initializer(0.1))
logit = tf.matmul(fc2, fc3_weights) + fc3_biases
return logit
# ---------------------------网络结束---------------------------
regularizer = tf.contrib.layers.l2_regularizer(0.0001)
logits = inference(x, False, regularizer)
# (小处理)将logits乘以1赋值给logits_eval,定义name,方便在后续调用模型时通过tensor名字调用输出tensor
b = tf.constant(value=1, dtype=tf.float32)
logits_eval = tf.multiply(logits, b, name='logits_eval')
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y_)
train_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
correct_prediction = tf.equal(tf.cast(tf.argmax(logits, 1), tf.int32), y_)
acc = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 定义一个函数,按批次取数据
def minibatches(inputs=None, targets=None, batch_size=None, shuffle=False):
assert len(inputs) == len(targets)
if shuffle:
indices = np.arange(len(inputs))
np.random.shuffle(indices)
for start_idx in range(0, len(inputs) - batch_size + 1, batch_size):
if shuffle:
excerpt = indices[start_idx:start_idx + batch_size]
else:
excerpt = slice(start_idx, start_idx + batch_size)
yield inputs[excerpt], targets[excerpt]
# 训练和测试数据,可将n_epoch设置更大一些
n_epoch = 10
batch_size = 64
saver = tf.train.Saver()
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for epoch in range(n_epoch):
start_time = time.time()
# training
train_loss, train_acc, n_batch = 0, 0, 0
for x_train_a, y_train_a in minibatches(x_train, y_train, batch_size, shuffle=True):
_, err, ac = sess.run([train_op, loss, acc], feed_dict={x: x_train_a, y_: y_train_a})
train_loss += err;
train_acc += ac;
n_batch += 1
print("%d epoch" % epoch)
print(" train loss: %f" % (np.sum(train_loss) / n_batch))
print(" train acc: %f" % (np.sum(train_acc) / n_batch))
# validation
val_loss, val_acc, n_batch = 0, 0, 0
for x_val_a, y_val_a in minibatches(x_val, y_val, batch_size, shuffle=False):
err, ac = sess.run([loss, acc], feed_dict={x: x_val_a, y_: y_val_a})
val_loss += err;
val_acc += ac;
n_batch += 1
print(" validation loss: %f" % (np.sum(val_loss) / n_batch))
print(" validation acc: %f" % (np.sum(val_acc) / n_batch))
print("============================================================ ")
saver.save(sess, model_path)
sess.close()
训练好后,我们可以看到model下已经有了具体的模型文件,代表训练成功。
训练成功后,我们用一个小程序来测试一下我们的模型
from skimage import io,transform
import tensorflow as tf
import numpy as np
path1 = "D:/python/workspace/flower/data/flowers/dandelion/8223968_6b51555d2f_n.jpg"
path2 = "D:/python/workspace/flower/data/other/1582514704.jpg"
flower_dict = {0:'flower',1:'other'}
w=100
h=100
c=3
def read_one_image(path):
img = io.imread(path)
img = transform.resize(img,(w,h))
return np.asarray(img)
with tf.Session() as sess:
data = []
data1 = read_one_image(path1)
data2 = read_one_image(path2)
data.append(data1)
data.append(data2)
print(data1.shape)
saver = tf.train.import_meta_graph('D:/python/workspace/flower/model1/model.ckpt.meta')
saver.restore(sess,tf.train.latest_checkpoint('D:/python/workspace/flower/model1/'))
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("x:0")
feed_dict = {x:data}
logits = graph.get_tensor_by_name("logits_eval:0")
classification_result = sess.run(logits,feed_dict)
#打印出预测矩阵
print(classification_result)
#打印出预测矩阵每一行最大值的索引
print(tf.argmax(classification_result,1).eval())
#根据索引通过字典对应花的分类
output = []
output = tf.argmax(classification_result,1).eval()
for i in range(len(output)):
print("第",i+1,"朵花预测:"+flower_dict[output[i]])
结果如下:
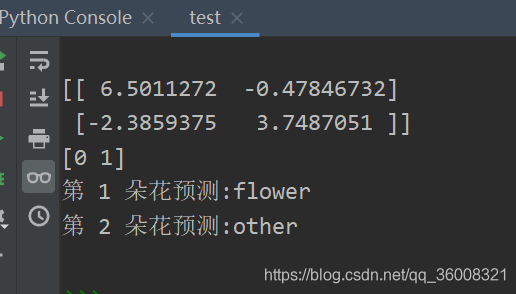
可以看出我们的模型是成功的,准确识别出了对应文件夹的图片数据。
第三步,准备Web界面
把准备好的web前端页面引入到templates文件夹中,然后使用flask 搭建web服务器。
然后写个接口,用来上传图片以及调用之前训练好的模型对花朵数据进行识别。
def getType(path):
w = 100
h = 100
c = 3
img = io.imread(path)
data = []
data.append(transform.resize(img,(w,h,3)))
with tf.Session() as sess:
saver = tf.train.import_meta_graph('D:/python/workspace/flower/model1/model.ckpt.meta')
saver.restore(sess, tf.train.latest_checkpoint('D:/python/workspace/flower/model1/'))
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("x:0")
feed_dict = {x: data}
logits = graph.get_tensor_by_name("logits_eval:0")
classification_result = sess.run(logits, feed_dict)
# 打印出预测矩阵每一行最大值的索引
print(classification_result)
output = tf.argmax(classification_result, 1).eval()
if (output[0] == 1):
return "不是花"
tf.reset_default_graph()
with tf.Session() as sess1:
saver1 = tf.train.import_meta_graph('D:/python/workspace/flower/model/model.ckpt.meta')
saver1.restore(sess1, tf.train.latest_checkpoint('D:/python/workspace/flower/model/'))
graph = tf.get_default_graph()
x = graph.get_tensor_by_name("x:0")
feed_dict = {x: data}
logits = graph.get_tensor_by_name("logits_eval:0")
classification_result = sess1.run(logits, feed_dict)
# 打印出预测矩阵每一行最大值的索引
output = tf.argmax(classification_result, 1).eval()
return flower_dict[output[0]]
@app.route('/upload',methods=['POST'])
def upload():
file = request.files.get('file')
type = getType(file)
res = file.filename + ",类型是:" + type
return json.dumps(res, ensure_ascii=False)
上传一张图片测试一下,看反馈结果。
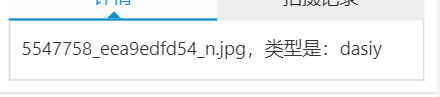
成功识别出了对应的图片信息,代表系统已经开发完成。
本系统以上传至本人Github ,如果可以帮助大家欢迎大家star,follow
