1、持久化
RDD的持久化包括两个方面:①操作RDD的时候怎么保存结果,这个部分属于action算子的部分②在实现算法的时候要进行cache、persist,还有checkpoint进行持久化。
1.1 persist和cache
Spark稍微复杂一点的算法里面都会有persit的身影,因为spark默认情况下是放在内存中,比较适合高速的迭代,如一个Stage有步骤非常多,中间不会产生临时数据,对于高速迭代是非常好的事情,但是对于分布式文件系统风险非常高,容易出错,这个时候就涉及到容错,由于RDD有血统继承关系,后面的RDD如果数据分片出错或者RDD本身出错之后可以根据前面的依赖血统关系算出来,但是如果没有对父RDD进行persist或cache还是要从头开始做。
首先先看下StorageLevel类,里面设置了RDD的各种缓存级别,总共有12种,其实是它的多个构造参数的组合形成的。


cache源码如下:

由源码可知,cache方法实际上调用了无参数的persist方法,缓存级别为仅在内存中。
persist源码如下:

无参的persist方法,默认缓存级别为仅在内存中


其实有2种情况:①是我们之前对RDD调用了checkpoint方法,这个方法是把RDD存储到disk上,之后我们再调用persist(newLevel)方法也是不会报错的,他会做检查你是否执行过checkpoint方法(即isLocallyCheckpointed),如果是的话就会调用persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true),而这里LocalRDDCheckpointData.transformStorageLevel(newLevel)返回的缓存级别是disk级别,故不会报错②如果我们之前设置过RDD的缓存级别,现在再次调用此方法进行缓存级别设置,但是缓存级别与之前一样,程序也是不会报错的,因为里面调用了persist(newLevel, allowOverride = false)方法
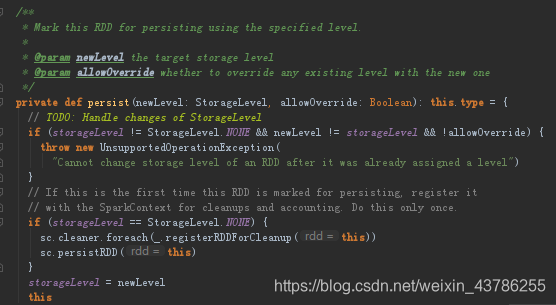
这个persist方法,适用于之前我们设置过了RDD的缓存级别,现在想要修改RDD的缓存级别的情况,只需要把allowOverride设置为true

这一段程序也解释了上面第一种方法的第一个特殊情况为什么不会报错
总结:①cache方法其实是persist方法的一个特例:调用的是无参数的persist(),代表缓存级别是仅内存的情况②persist方法有三种,分为默认无参数仅内存级别的persist(),还有persist(newLevel):这个方法需要之前对RDD没有设置过缓存级别,persist(newLevel,allowOverride):这个方法适用于之前对RDD设置过缓存级别,但是想更改缓存级别的情况。③取消缓存统一使用unpersist()方法④persist是lazy级别的(前面的算子都是lazy的每执行,所以他肯定也要是lazy级别的),unpersist是eager级别的(即调用的时候会立即清除)。
注意:①cache之后一定不能立即有其他算子,cache后有算子的话,它每次都会重新触发这个计算过程,cache不是一个action;②cache被gc清除的两种方式:unpersist强制销毁数据;会被后续的计算结果挤掉
缓存实现的原理:DiskStore磁盘存储和MemoryStore内存存储
DiskStore磁盘存储:spark会在磁盘上创建spark文件夹,命名为(spark-local-x年x月x日时分秒-随机数),block块都会存在这里,然后把block id映射成相应的文件路径,就可以存取文件了
MemoryStore内存存储:使用hashmap管理block就行了,block id作为key,MemoryEntry为value
1.2 做缓存的时机
(1)计算特别耗时;
(2)计算链条很长,失败的时候会有很大的代价:假设900个步骤在第800个步骤缓存,801的步骤失败了就会在800个步骤开始恢复;
(3)shuffle之后:shuffle是进行分发数据,缓存之后假设后面失败就不需要重新shuffle;
(4)checkpoint之前:checkpoint是把整个数据放到分布是文件系统中或磁盘,checkpoint是在当前作业执行之后,再触发一个作业,恢复时前面的步骤就不需要计算
缓存是不一定可靠的,缓存在内存中不一定是可靠的,把数据缓存在内存中有可能会丢失,例如只缓存在内存中,而不同时放在内存和磁盘上,可能内存crash(奔溃),crash内存现在有一种办法就是用Tachyon做底层存储,但是使用checkpoint的数数据一定放在文件系统上,这个时候数据就不会丢失。假设缓存了100万个数据分片,开始缓存是成功的,由于内存的紧张在一些机器上把一些数据分片清理掉了,那这时候就需要重新计
(5)shuffle之前persist(不过框架已经默认帮我们把数据持久化到本地磁盘)
//cache实例
val cached=sc.textFile("G:\\Scala\\data\\README.md").flatMap(_.split(" ")).map(_=>(_,1)).reduceByKey(_+_,1).cache
cached.count2 广播BroadCast
为什么需要广播?每个task运行,读取全局数据的时候每个task每次都要拷贝一个数据副本,他的好处就是状态一致性,不好的就是耗大量的内存,变量大就容易OOM,这种是非常严重的,必须全部放在内存上,不能一部分放磁盘上。
广播过去的全局只读不能修改的,广播到worker的executor内存中。广播变量不需要销毁,应用程序存在他就存在,sc销毁它也就销毁了。
总结:广播是由Driver发送给当前Application分配的所有Executor内存级别的全局只读变量,Executor中的线程池中的线程共享该全局变量,极大减少网络传输(否则每个task都要传输一次该变量),并极大的节省内存,减少OOM的可能,当然也隐形的提高CPU的有效工作(因为每次传CPU也很忙)
//广播实例:
val number =6
val broadcastVar = sc.broadcast(number ) //广播只能由broadcast广播
val data=sc.parallelize(1 to 10)//创建RDD,由Task使用广播变量
val bn=data.map(_*broadcastVar .value)3 累加器Accumulator
为什么需要累加器?累加器的特征:是全局级别的,且Executor中的task只能修改(增加内容),只有driver可读,因为我们通过driver控制整个集群有必要知道整个集群的状态。(对于Executor只能修改但不可读,只对driver可读)。Executor修改一定不会彼此覆盖相当于加锁了。
因为他的特性,在记录集群状态的时候,尤其是全局唯一状态的时候至关重要,可以保存唯一的全局变量。
累加器原理:由于被driver控制,在实际task运行的时候,每次都可以保证只对driver可读获取全局唯一的状态对象。
总结:①累加器是全局唯一的,每次操作只增不减②在executor中只能修改他,也就是只能增加他的值。
可以认为Broadcast是线程级别全局共享,累加器是executor全局共享
//累加器实例:
val acc = sc.accumulator(0)
val data=sc.parallelize(1 to 10)
val result=data.foreach(item=>acc +=item)
println(result)