一、Bert简介
谷歌AI实验室的BERT深刻影响了NLP的格局。
BERT之后,许多NLP架构、训练方法与语言模型如雨后春笋般涌现,比如谷歌的TransformerXL、OpenAI’s GPT-2、 XLNet、ERNIE2.0、 RoBERTa等。
BERT团队对该框架的描述:
BERT全称Bidirectional Encoder Representations from Transformers(Transformers的双向编码表示),对未标注的文本,通过上下文约束预训练深层双向表示。训练完成后,只需要对BERT预训练模型进行fine-tune,再加上针对特定任务的输出层就可以取得SOTA(state of the art)结果。
BERT是在大量的未标注文本上预训练得到,包括整个Wikipedia(25亿单词)和图书语料库(8亿单词)。
BERT最吸引人的在于,我们仅仅通过在模型后根据自己的需求加上输出层部分就可以在各类NLP任务取得SOTA结果。
二、从Word Embedding到Bert
1. 图像预处理
自从深度学习火起来后,预训练过程就是做图像或者视频领域的一种比较常规的做法,有比较长的历史了,而且这种做法很有效,能明显促进应用的效果。
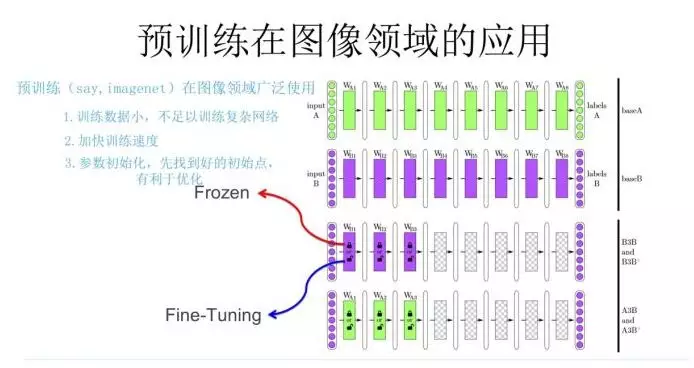
预处理过程如上图:
- 我们设计好网络结构以后,对于图像来说一般是CNN的多层叠加网络结构,可以先用某个训练集合比如训练集合A或者训练集合B对这个网络进行预先训练,在A任务上或者B任务上学会网络参数,然后存起来以备后用。
- 假设我们面临第三个任务C,网络结构采取相同的网络结构,在比较浅的几层CNN结构,网络参数初始化的时候可以加载A任务或者B任务学习好的参数,其它CNN高层参数仍然随机初始化。
- 之后我们用C任务的训练数据来训练网络,此时有两种做法:
(1)一种是浅层加载的参数在训练C任务过程中不动,这种方法被称为“Frozen”;
(2)另一种是底层网络参数尽管被初始化了,在C任务训练过程中仍然随着训练的进程不断改变,这种一般叫“Fine-Tuning”,顾名思义,就是更好地把参数进行调整使得更适应当前的C任务。
一般图像或者视频领域要做预训练一般都这么做。这样做的优点是:如果手头任务C的训练集合数据量较少的话,利用预训练出来的参数来训练任务C,加个预训练过程也能极大加快任务训练的收敛速度,所以这种预训练方式是老少皆宜的解决方案,另外疗效又好,所以在做图像处理领域很快就流行开来。
为什么预训练可行?对于层级的CNN结构来说,不同层级的神经元学习到了不同类型的图像特征,由底向上特征形成层级结构,所以预训练好的网络参数,尤其是底层的网络参数抽取出特征跟具体任务越无关,越具备任务的通用性,所以这是为何一般用底层预训练好的参数初始化新任务网络参数的原因。而高层特征跟任务关联较大,实际可以不用使用,或者采用Fine-tuning用新数据集合清洗掉高层无关的特征抽取器。
2. word2vec/glove
预训练模型从大量未标注文本数据中学习语言表示的思想来源于词嵌入。最初是神经网络语言模型(NNLM) 的思路。通过神经网络学习语言模型任务,这个网络不仅自己能够根据上文预测后接单词是什么,同时获得一个副产品,即神经网络参数矩阵,这就是单词的Word Embedding。
2013年最火的用语言模型做Word Embedding的工具是Word2Vec,后来又出了Glove。
词嵌入改变了进行NLP任务的方式。通过嵌入,我们能够捕获单词的上下文关系。
这种模型做法就是18年之前NLP领域里面采用预训练的典型做法。这种嵌入方法的缺陷:
- 只使用了很浅的语言模型,那就意味着它们捕获到的信息是有限的。
- 没有考虑单词的上下文。
举个“bank”的例子,在不同的语境下同一个单词可能会有不同的含义。如果我们想仅依靠上文或者下文的信息去理解“bank”的含义,那么对这两句话中的“bank”,我们是无法区分它们的不同含义的。
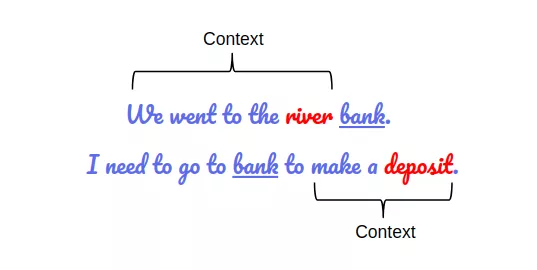
WordVec训练浅层前馈网络,将不同语境中的“bank”以同样的向量表示。于是,一些重要的信息被遗漏了。
3. ElMo
ELMo(Embeddings from Language Models,嵌入语言模型),出自于论文“Deep contextualized word representation”,是对语言多义性问题提出的解决方案——ELMo试图通过训练两个LSTM语言模型(一个利用从左到右的文本信息,一个利用从右到左的文本信息),并将它们进行连接来解决这个问题。针对那些在不同上下文中具有不同含义的单词,这意味着同一单词根据其所在的上下文可以具有多个ELMO嵌入。
从那时起,我们开始注意到预训练的优势将使其在NLP任务中发挥重要作用。
ELMO采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。
它的网络结构采用了双层双向LSTM左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外的上文Context-before;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文Context-after;每个编码器的深度都是两层LSTM叠加。训练好这个网络后,输入一个新句子,句子中每个单词都能得到对应的三个Embedding:
- 最底层是单词的Word Embedding;
- 往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;
- 再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。
也就是说,ELMO的预训练过程不仅仅学会单词的Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。下游任务以QA为例:
- 此时对于问句X,我们可以先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding;
- 之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个;
- 然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。ELMo对于多义词的解决,在于第一层LSTM编码了很多句法信息,在这里起到了重要作用。
ELMo的缺点在于:
- 使用了LSTM而不是新贵Transformer,很多研究已经证明了Transformer提取特征的能力是要远强于LSTM的。
- ELMO采取双向拼接这种融合特征的能力可能比Bert一体化的融合特征方式弱,但是,这只是一种从道理推断产生的怀疑,目前并没有具体实验说明这一点。
4. ULMFiT
ULMFiT(Universal Language Model Fine-tuning,通用语言模型微调)更进一步,在文档分类任务中,即使只有很少的数据(少于100),对该框架训练的语言模型进行微调就能够提供出色的结果。这意味着ULMFiT解决了NLP任务中的迁移学习问题。
这是我们提出的NLP迁移学习黄金公式:
NLP迁移学习 = 预训练 + 微调
在ULMFIT之后,许多NLP任务根据上述公式进行训练,并获得了新的基准。
5. GPT
OpenAI提出的GPT(Generative Pre-Training)进一步扩展了ULMFiT和ELMo中引入的pre-training和fine-tuning方法。
GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:
- 首先,特征抽取器不是用的RNN,而是用的Transformer,上面提到过它的特征抽取能力要强于RNN,这个选择很明显是很明智的;
- 其次,GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓“单向”的含义是指:语言模型训练的任务目标是根据单词的上下文去正确预测单词,之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。
不仅是文档分类任务,GPT模型还可以对其他NLP任务进行fine-tuned,例如常识推理,语义相似性和阅读理解。GPT在多项任务获得SOTA结果,验证了Transformer架构的鲁棒性和有效性。
5. Bert
BERT在Transformer的基础上横空出世,并给NLP领域带来巨大变革。
至此,解决NLP任务离不开这两步:
- 在未标注的大型文本语料库上训练语言模型(无监督或半监督)
- 针对特定的NLP任务对大型语言模型进行微调,以充分利用预训练模型的大量知识(监督)
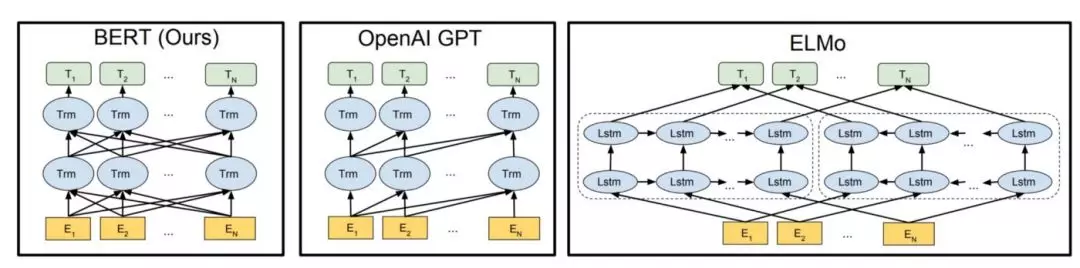
从以上图片可以明显看到:BERT是双向的,GPT是单向的(从左到右的信息流),ELMo是浅层双向的。
对比ELMo,虽然都是“双向”,但目标函数其实是不同的。ELMo是分别以
和
作为目标函数,独立训练出两个representation然后拼接,而BERT则是以
作为目标函数训练LM。
三、深入理解Bert
BERT的创新点在于:
- 引入了掩码使得Transformer编码器能够使用双向信息
- 加入两个预训练任务,实现NLP领域的迁移学习
1. Bert的结构
BERT 的模型结构是一个多层双向Transformer 编码器,整体的模型结构其实就是Transformer, 目前有两个可用的变体:
- BERT Base:12层(transformer模块),12层注意力,1.1亿参数
- BERT Large:24层(transformer模块),16层注意力,3.4亿参数
由于模型权重不在层之间共享,因此一个BERT 模型最多就能有效地包含多达24 x 16 = 384个不同的注意力机制。
有论文通过实验证明:BERT的低层网络就学习到了短语级别的信息表征,BERT的中层网络就学习到了丰富的语言学特征/句法信息,而BERT的高层网络则学习到了丰富的语义信息特征。(2019ACL论文“What does BERT learn about the structure of language?”)
2. 文本预处理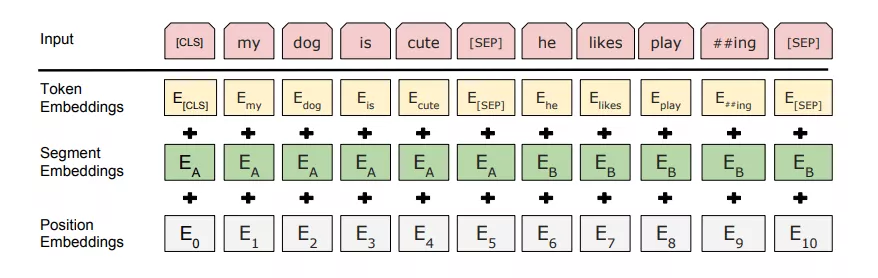
Bert的每个输入嵌入都是三个嵌入的组合,即对于给定的输入,其输入表示形式是通过将相应的令牌(token)嵌入,段(segment)嵌入和位置嵌入相加而构造的。
(1)Token Embeddings
令牌嵌入是从WordPiece令牌词汇表中为特定令牌学习的嵌入。
BERT在预训练阶段输入基本和Transformer结构是相同的,主要的区别是加入了CLS和SEP两个特殊字符,每个序列的第一个标记始终是特殊分类嵌入CLS,该特殊标记对应的最终隐藏状态(即Transformer 的输出)被用作分类任务中该序列的总表示。对于非分类任务,这个最终隐藏状态将被忽略,SEP则是用来区别被打包到一起的句子对输入。
WordPiece
BERT在处理输入时,会采用WordPiece方法对输入进行分割。即用双字节编码(BPE,Byte-Pair Encoding)的方式,把一个单词再拆分,使得词表变得精简,并且寓意更加清晰,从而提高训练速度和效果。比如"loved",“loving”,“loves"这三个单词,BPE算法通过训练,会把上面的3个单词拆分成"lov”,“ed”,“ing”,"es"几部分。
(2)Segment Embeddings
BERT也可以将句子作为任务的输入(问题-解答)。因此,它为句子对的第一句话和第二句话学习了独特的嵌入,以帮助模型区分它们。
为了对被打包在一起输入的句子对,除了使用上面的SEP标示之外,BERT会给第一个句子的每个标记添加一个可训练的句子 A嵌入,给第二个句子的每个标记添加一个可训练的句子 B 嵌入,例如A嵌入都是0,B嵌入都是1。
(3)Position Embeddings
位置嵌入其实就是对输入的每个位置训练一个向量。
BERT学习并使用位置嵌入来表达单词在句子中的位置。添加该嵌入是为了克服Transformer的局限性,与RNN不同,Transformer无法捕获“序列”或“顺序”信息。
3. 预训练任务
BERT对两项NLP任务进行预训练:
- 遮掩语言模型
- 下句预测
(1)Masked LM 遮掩语言模型(双向)
BERT是深层的双向模型,该网络从第一层到最后一层始终关注当前单词的上下文进行信息捕获。
MLM可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测。对于该15%的词,80%是采用[mask],10%是随机取一个词来代替mask的词,10%保持不变。
以一定的概率使用随机词,是因为transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是某个词。
(2)下句预测
遮掩语言模型(MLMs)学习单词之间的关系。
此外,BERT还对下句预测任务进行训练以学习句子之间的关系。选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性,添加这样的预训练的目的是目前很多NLP的任务比如QA和NLI都需要理解两个句子之间的关系,从而能让预训练的模型更好的适应这样的任务。
4. Bert的缺点
- task1的随机遮挡策略略显粗犷,推荐阅读《Data Nosing As Smoothing In Neural Network Language Models》。
- [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现。每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)。
- BERT对硬件资源的消耗巨大(大模型需要16个tpu,历时四天;更大的模型需要64个tpu,历时四天。
- (个人想法,有待考证:工业界使用的实时性)
- (个人想法,有待考证:可解释性不足)
Bert之后
BERT之后,一些新的项目在NLP各项任务中取得了更好的结果。
比如RoBERTa,这是Facebook AI对BERT和DistilBERT的改进,而后者其实就是BERT的更轻巧,便捷的版本。
比如UNILM (UNIfied pretrained Language Model),同时训练BERT中的双向LM、GPT中的单向LM和seq2seq中的LM,是微软提出的改论文。
再比如GPT2.0、MASS、XLNet等等。
你可以在regarding State-of-the-Art NLP in this article了解更多BERT之后的改进模型。
参考网址:
- Demystifying BERT: A Comprehensive Guide to the Groundbreaking NLP Framework——解密 BERT(上文的翻译)——解密 BERT(CSDN转载的翻译)
BERT论文笔记 - How do Transformers Work in NLP? A Guide to the Latest State-of-the-Art Models——How do Transformers Work in NLP? A Guide to the Latest State-of-the-Art Models(CSDN转载)(原文的图我打不开)
- 面经 | NLP求职助力贴:一文了解BERT的前世今生(附代码实现)(很不错)——转载自:https://github.com/NLP-LOVE/ML-NLP/tree/master/NLP/16.8%20BERT
- 用可视化解构BERT,我们从上亿参数中提取出了6种直观模式
- 理解BERT每一层都学到了什么
