程序通过OpenCV实现对Marker的识别和定位,然后通过OpenGL将虚拟物体叠加到摄像头图像下,实现增强现实。这里以参考《深入理解OpenCV》这本书第二章节的例子,实现基于标记的的虚拟现实实现。看到网上很多的例子都是基于固定渲染管线来画虚拟物体的, 而且很多地方都经不起推敲。 本例使用现代OpenGL实现的整个绘制过程。
访问相机
增强现实应用必须包括视频捕获和AR可视化这两个主要过程。视频捕获阶段包括从设备接收视频帧,执行必要的色彩转换,并且将其发送给图像处理流程。对AR应用来讲,单帧处理的时间很关键,因此,帧的获取应尽可能高效。为了达到高性能,最好的办法是直接从摄像机读取帧。从iOS4开始支持这种方式。AVFoundation框架有现成的API函数来直接读取内存中的图像缓冲区。
AVCaptureDevice和AVCaptureVideoDataOutput允许用户配置、捕获以及指定未处理视频帧,这些帧都是32bpp BGRA格式(bpp是bit per pixel的缩写)。也可设置输出帧的分辨率。但这样做会影响整体性能,因为较大的帧会花费更多的处理时间并需要更大的内存空间。
通过AVFoundation API来获取高性能视频有一个好的选择。它提供了一个更快、更简洁的方法来直接从摄像机缓冲区中获取帧。但首先需了解下图关于iOS的视频获取流程:
[外链图片转存失败(img-ZTDLfxaJ-1563499922237)(/img/in-post/post-vr/vr5.jpg)]
AVCaptureMovieFileOutput接口用于将视频写到文件中,AVCaptureStillImageOutput接口用于生成静态图像,AVCaptureVideoPreviewLayer接口用于在屏幕上进行视频预览。本项目将用到AVCaptureVideoDataOutput接口,因为它可直接访问视频数据。
AVCaptureVideoDataOutput *captureOutput = [[AVCaptureVideoDataOutput alloc] init];
captureOutput.alwaysDiscardsLateVideoFrames = YES;
// 在这里注册输出
[self.captureSession addOutput:captureOutput];
#pragma mark AVCaptureSession delegate
- (void)captureOutput:(AVCaptureOutput *)captureOutput didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer fromConnection:(AVCaptureConnection *)connection
{
CVImageBufferRef imageBuffer = CMSampleBufferGetImageBuffer(sampleBuffer);
CVPixelBufferLockBaseAddress(imageBuffer,0);
/*Get information about the image*/
uint8_t *baseAddress = (uint8_t *)CVPixelBufferGetBaseAddress(imageBuffer);
size_t width = CVPixelBufferGetWidth(imageBuffer);
size_t height = CVPixelBufferGetHeight(imageBuffer);
size_t stride = CVPixelBufferGetBytesPerRow(imageBuffer);
BGRAVideoFrame frame = {width, height, stride, baseAddress};
[delegate frameReady:frame]; //派发帧
/*We unlock the image buffer*/
CVPixelBufferUnlockBaseAddress(imageBuffer,0);
}
绘制背景
由于是AR项目, 所有背景输出的就是camera捕获的内容了。 这里获取到的frame都是上面代码传过来的BGRA格式的图像, 我们在OpenGL创建一个GL_TEXTURE_2D, 把frmae的内容绑定到对应的texture即可。对应的格式设置如下, 此时因为全屏输出, 也没有必要设置mipmap.
glGenTextures(1, &m_backgroundTextureId);
glBindTexture(GL_TEXTURE_2D, m_backgroundTextureId);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
// This is necessary for non-power-of-two textures
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
创建一个quad的mesh, 对应的uv区间是【0,1】。 在vert shdader里,直接输出到屏幕,也不需要多余的变换,例如投影之类的。如果输出的图像于现实是相反的,你可以在frag shader里uv采样的时候直接翻转下uv即可。
// vert shader
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec2 aTexCoords;
out vec2 TexCoords;
gl_Position = vec4(aPos, 1.0, 1.0);
// frag shader
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
#ifdef _FLIP_Y_
vec4 color = texture(texture1, vec2(TexCoords.x, 1.0 - TexCoords.y));
#end
FragColor = color;
相机姿势估计
关于什么是相机的内参和外参就不详细介绍了, 具体可以参考这篇文章。
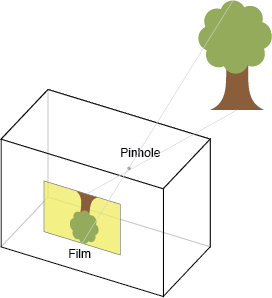
计算摄像机的位置,首先需要对摄像机进行标定,标定是确定摄像机内参矩阵K的过程,一般用棋盘进行标定,这已经是一个很成熟的方法了,在这就不细说了。得到相机的内参矩阵K后,就可以使用solvePnP方法求取摄像机关于某个Marker的位置(这里理解成相机的位置和旋转更确切些, 以虚拟物品当做世界坐标原点,即虚拟物品的模型空间等于世界空间,通过得来的转换矩阵变换到view空间)。摄像机成像使用小孔模型,如下:
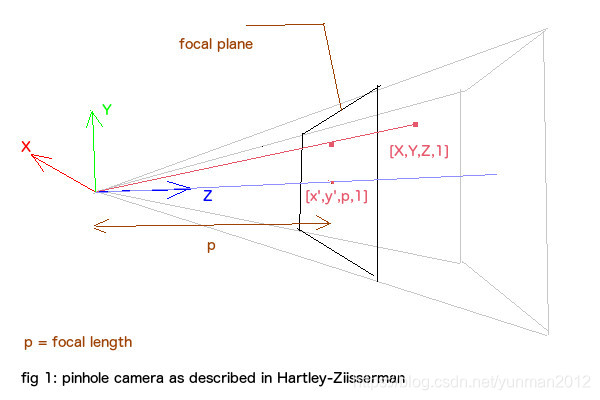
其中,X是空间某点的坐标(相对于世界坐标系),R和T是摄像机外参矩阵,用于将某点的世界坐标变换为摄像机坐标,K是摄像机内参,用于将摄像机坐标中的某点投影的像平面上,x即为投影后的像素坐标。
相机的内参K 表达式如下:
其中f_x代表x-axi方向上的焦距, f_y代表着y-axi方向上的矩阵, 一般来说f_x = f_y = f , 即相机的焦距,在iPhone或者iOS设备上,这个值大约等于640。 x_0和y_0有的地方也叫u0和v0,表示图像的半宽和半高。这里的参数主要用在投影过程中, 他们都是投影矩阵的参数,下面会有详细的介绍。
opencv的相机坐标系转换到opengl的相机坐标系
opencv的相机坐标系参考文章:相机模型与标定(二)–三大坐标系及关系
opengl的相机坐标系参考文章:OpenGL.坐标系统的介绍与坐标变换的实现
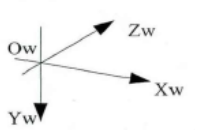
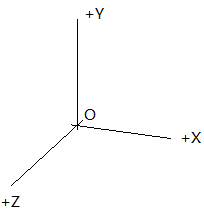
两个系统下的相机坐标系都是右手系的,x轴都是指向右,只是y轴和z轴反了。(上左图就是opencv的相机坐标系,上右图是opengl的)因此,只需要把物体在opencv的相机坐标系下的坐标绕x轴旋转180度,就可以转换为opengl的相机坐标系下的坐标了。
具体实现可以让相机外参左乘一个翻转矩阵:
获取使用一个3x3的矩阵同时作用于transform(vec3) 和旋转(mat3). 我看网上有类似的计算,也是对的。
在ksimek的博客里, 看到一个思路,并没有翻转y轴和z轴。 而是添加了一个到NDC的变换,可能也能实现同样的效果。 但是文章里很多公式都是错的,这里我也没有仔细推。耐心的读者可以认真地按照作者说的思路,详细推导一遍。
读者可以看到很多地方说是需要绕x轴旋转180, 也可以推导出上述的公式。 但原因绝不是因为view space到project space的变化的,也不是因为所谓的OpenGL为了进行Clipping,其投影矩阵需要将点投影到NDC空间中。 因为这些变化都体现在了投影矩阵里了, 投影矩阵会切换右手坐标系到左手坐标系,具体的推导过程参考这里。
现在再来考虑OpenGL投影椎体不对称的情况,这种情况下,PROJECTION矩阵的形式为:
其中c,d 如下:
关于l+r和b+t是怎么计算的,可以参考下图:
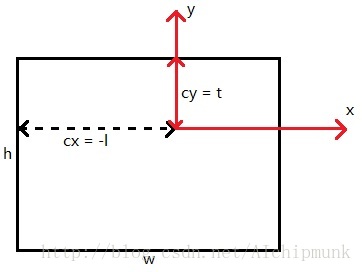
代码部分如下, 根据相机内参构建投影矩阵并建立opencv到opengl的y轴-z轴翻转矩阵(绕x轴旋转180度)
void InitialVR(float width, float height,const Matrix33& intrinsic)
{
proj = glm::mat4(0);
float fx = intrinsic.data[0], n= -0.01f, f = -100.0;
proj[0][0] = 2.0 * fx / width;
proj[1][1] = 2.0 * fx / height;
proj[2][2] = (f + n) / (n - f);
proj[2][3] = -1.0;
proj[3][2] = 2.0 * f * n / ( f - n);
reverse = glm::mat4(1);
reverse[1][1] = -1;
reverse[2][2] = -1;
}
根据MarkerDetector识别的camera外部参数, 传递给shader.
glm::mat4 view = transforms[i].getMat44(); //camera's position & rotation
view = reverse * view;
vrShader->use();
vrShader->setMat4("view", view);
vrShader->setMat4("proj", proj);
glBindVertexArray(vrVao);
glDrawArrays(DRAW_MODE, 0, 36);
glBindVertexArray(0);
shader里直接变换到屏幕上的图像就可以了, 在glsl里实现如下:
uniform mat4 view;
uniform mat4 proj;
out vec2 TexCoords;
void main()
{
vec3 pos = vec3(aPos.x * 0.3, aPos.y * 0.3, aPos.z * 0.3);
gl_Position = proj * view * vec4(pos, 1.0);
}
最后展示下在引擎里运行在ipad上的效果:
参考:
[1] Camera Intrinsic & Extrinsic矩阵
[2] OpenGL Projection Matrix
[3] iOS内置的api 获取camera内置参数
[4] OpenGL与OpenCV实现增强现实
[5] OpenGL坐标系统
[6] Calibrated Cameras in OpenGL without glFrustum
