大数据hadoop学习-----hadoop上eclipse的安装及相应的hadoop配置目录
在进行hadoop的学习时候,利用Java API与HDFS进行交互是学习hadoop的重要步骤,既然需要用到java API与HDFS的交互,那么我们就需要java的集成环境,eclisp当然是我们的首选啦,本次博客,林君学长主要向大家介绍如何在ubuntu16.04上面安装eclisp以及进行相应的hadoop配置
一、eclisp的下载及安装
1、打开我们的ubuntu16.04的软件商店UK

2、搜索eclipse进行安装

由于我的已经安装,所以显示已安装,小伙伴们没有安装,可以点击安装,然后进行等待就好了,他会自动为你安装的!
二、创建我们hadoop的java项目
1、打开eclipse

2、选择我的的工作空间(workspace)

自己选择一个空间,不一定要用默认的,为了后续不用再次进行选择,我们将上面的小方框中打钩,然后OK

3、创建java项目
1)、选择“File->New->Java Project”菜单,开始创建一个Java工程,会弹出下图界面:

2)、点击next后会出现以下界面,选择库,进行添加hadoop所需要的库

3)、选择后如下所示:

需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了可以访问HDFS的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮
4、hadoop相关库的添加
1)、添加 /usr/local/hadoop/share/hadoop/common目录下的hadoop-common-2.7.1.jar和haoop-nfs-2.7.1.jar

2)、添加 /usr/local/hadoop/share/hadoop/common/lib目录下的所有JAR包
1.进入目录,ctrl+A进行全选,然后点击确认!

3)、添加 /usr/local/hadoop/share/hadoop/hdfs目录下的haoop-hdfs-2.7.1.jar和haoop-hdfs-nfs-2.7.1.jar

4)、添加 /usr/local/hadoop/share/hadoop/hdfs/lib目录下的所有JAR包

以上步骤,我们所需要的hadoop的包就完全导入了
5)、添加完后,点击finsh,我们的项目就创建完成啦!

三、添加hadoop的java类
1、点击项目右键选择new,然后选择class进行创建

2、输入包名、类名完成创建

3、将下列代码写入类中进行测试
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Hdfs {
public static void main(String[] args){
try{
String fileName = "test";
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(fileName))){
System.out.println("文件存在");
}else{
System.out.println("文件不存在");
}
}catch (Exception e){
e.printStackTrace();
}
}
}
注意class的类名是你创建的类名!
上面的代码只是hadoop环境下的测试代码,测试文件是否存在的,具体不用管哦!
四、配置运行环境并运行
1、打开终端,切换到hadoop用户,运行hadoop
su - hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
jps

2、鼠标点击运行按钮旁边的小三角,选择【Run As】进行配置
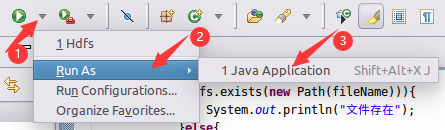
在弹出的页面选择刚刚创建的项目名,然后点击OK就好,如下所示:
1)、会看到控制台如下所示:

如上所示,出现文件不存在,我们就完美运行了,警告那些不用管,到这里,我们的hadoop的java程序就介绍了,接下来,介绍如何把Java应用程序生成JAR包,部署到Hadoop平台上运行
五、将hadoop的java项目导入到hadoop平台进行运行
1、在刚才的终端创建文件夹,放我们的java程序
1)、创建myapp文件夹,并赋予权限
mkdir myapp
chmod 777 myapp
ls

2、将java项目导入我们的hadoop平台
1)、右击项目、选择导出

2)、选择java---->Runable JAR file

3)、按照下图选择,浏览,选择我们创建的myapp文件夹

点击Browse出现如下界面:

在接下来的界面一直点击OK就好,如下所示:

3、回到刚刚终端查看是否导入进去了
cd /usr/local/hadoop/myapp
ls
4、终端运行我们的jar的java文件
1)、进入hadoop环境
cd /usr/local/hadoop
2)、运行
./bin/hadoop jar ./myapp/hdfs.jar
3)、或者用运行方式2
java -jar ./myapp/HDFSExample.jar
4)、运行结果如下所示:

和我们在eclipse上面运行的结果一样,本次实验就完美结束啦!
以上就是本次博客的全部内容哦,希望对小伙伴学习hadoop上面的java环境有所帮助,遇到问题的小伙伴,记得评论区留言,我看到会给大家解答的!
陈一月的又一天编程岁月^ _ ^
