HashSet
Java 集合可分为Set.List和Map三种大体系
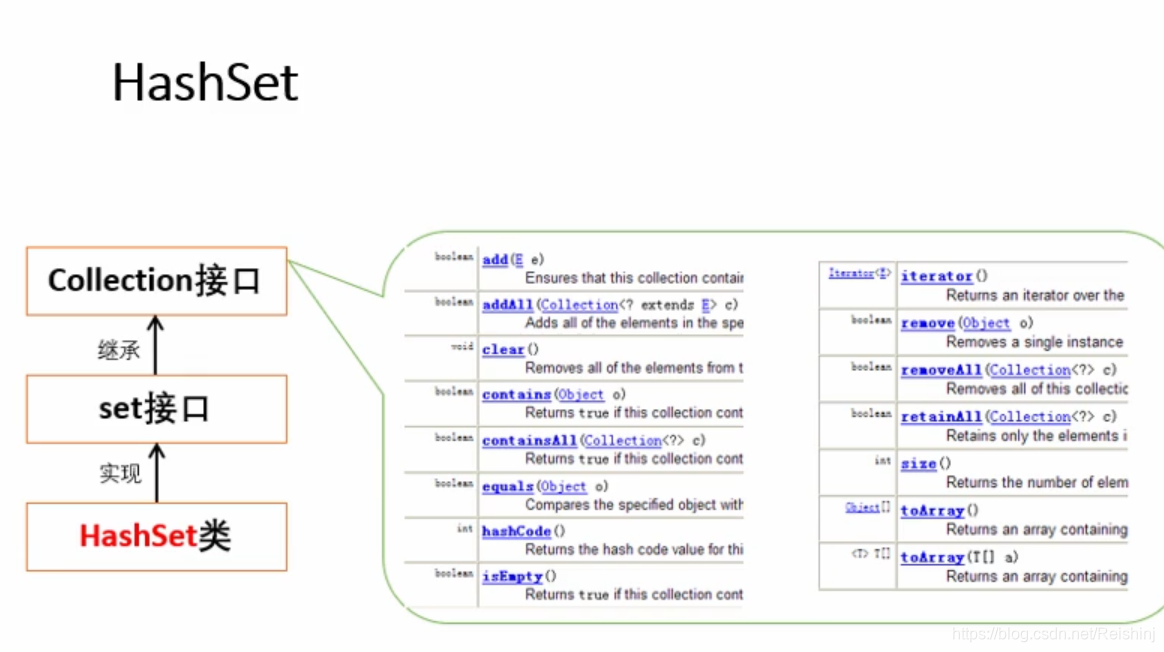
HashSet是Set接口的典型实现,大多数的时候使用Set集合时都使用这个实现类.
我们大多数时候说的set集合指的都是HashSet
HashSet按Hash算法来存储集合中的元素,因此具有很好的存储和查找性能.
HashSet具有以下特点
1.不能保证元素的排列顺序
2.不可重复
3.HashSet不是线程安全的
4.集合元素可以是null
HashSet不保证数据存储的位置,存在Set集合哪个位置由这个值的hashcode决定.
import java.util.HashSet;//在newHashSet时会自动生成
import java.util.Set;//import接口Set
public class Test02 {
public static void main(String[] args) {
Set set = new HashSet<>();
set.add(1);//使用add给集合添加元素
set.add("a");
System.out.println(set);//直接打印对象set就可以 [1,a]
set.remove(1);//移除元素
System.out.println(set);//[ture]
set.contains("a");//判断是否包含元素
System.out.println(set.contains("a"));//ture
set.clear();//清除元素
System.out.println(set);//[]
}
}
使用迭代器遍历集合的方法:
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Test02 {
public static void main(String[] args) {
Set set = new HashSet<>();
set.add("a");
set.add("b");
set.add("c");
set.add("d");
//使用迭代器遍历集合
Iterator it = set.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
//for each 迭代集合
for(Object obj : set) {//这个的意思是把set的每一个值取出来,赋值给obj,知道循环set的所有值
System.out.println(obj);
}
System.out.println(set.size());//获取集合的元素个数
}
}
hashcode()方法
HashSet集合判断两个元素相等的标准:两个对象通过equals()方法判断相等,并且两个对象的hashCode()方法返回值也相等.
如果两个对象通过equals()方法返回true,这两个对象的hashCode值也应该相等
泛型
使用Set<> set1 = new HashSet<>;
来进行指定HashSet合集中存储的元素,除了中括号内填写类型外,其他都不能再存储
例如:
Set< String > set1 = new HashSet< String >;//只能存储String类型的字符串
TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态.
TreeSet支持两种排序方法:自然排序和定制排序.默认情况下,TreeSet采用自然排序.

import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class Test03 {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<Integer>();
set.add(5);
set.add(2);
set.add(4);
set.add(3);
System.out.println(set);//[2,3,4,5] TreeSet自然排序
set.remove(5);//移除方法
set.contains(3);//判断方法
// set.clear();//清除方法
//使用迭代器遍历
Iterator<Integer> it = set.iterator();
while(it.hasNext()) {
System.out.println(it.next());
//for each迭代集合
for(Integer i : set) {
System.out.println(i);
}
}
}

定制排序
把Person对象存到TreeSet中并按照年龄排序
class Person implements Comparator<Person>{//import java.util.Comparator;
int age;
String name;
public Person(){//空构造器
};
public Person(int age,String name) {
this.age = age;
this.name = name;
}
@Override
public int compare(Person o1, Person o2) {//年龄正序排列
if(o1.age > o2.age) {
return 1;
}else if(o1.age < o2.age) {
return -1;
}else{
return 0;
}
}
}
import java.util.Comparator;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class Test03 {
public static void main(String[] args) {
Person p1 = new Person(27,"zhangsan");
Person p2 = new Person(22,"zhangsan1");
Person p3 = new Person(45,"zhangsan2");
Person p4 = new Person(34,"zhangsan3");
Set<Person> set = new TreeSet<Person>(new Person());
set.add(p1);
set.add(p2);
set.add(p3);
set.add(p4);
for(Person p : set) {
System.out.println(p.age + " " + p.name);
}
}
}
List与ArrayList

import java.util.ArrayList;
import java.util.List;
public class Test04 {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("b");//第一个,索引下标0
list.add("d");//索引下标1
list.add("c");//索引下标2
list.add("a");//索引下标3
list.add("d");//索引下标4,允许使用重复元素
System.out.println(list);//[b, d, c, a, d]
System.out.println(list.get(2));//获取下标为2的元素,输出结果:c
list.add(1,"f");//在第1个索引下标位置插入元素 f
System.out.println(list);//[b, f, d, c, a, d]
List<String> l = new ArrayList<String>();
l.add("123");
l.add("456");
list.addAll(2, l);//在第二个index位置添加list l
System.out.println(list);//[b, f, 123, 456, d, c, a, d]
//获取指定元素在集合中第一次出现的索引下标
System.out.println(list.indexOf("d"));//索引下标第五位,输出结果:4
//获取指定元素在集合中最后一次出现的索引下标
System.out.println(list.lastIndexOf("d"));//索引下标第八位,输出结果:7
list.remove(2);//根据指定索引下标移除元素
System.out.println(list);//[b, f, 456, d, c, a, d]
list.set(1, "ff");//根据指定的索引下标index修改元素
System.out.println(list);//[b, ff, 456, d, c, a, d]
//创建新的String类型List合集 sublist,根据索引下标的位置截取一段元素形成一段新的集合
List<String> sublist = list.subList(2, 5);//截取的时候包含开始的索引不包含结束时的索引 2,5 是大于等于3,小于等于6的元素.
System.out.println(sublist);//[456, d, c]
System.out.println(list.size());//获取集合的长度,输出结果:7
}
}
Map
Map用于保存具有映射关系的数据,因此Map集合里保存着两组值,一组值用于保存Map里的Key,另外一组用于保存Map里的Value
Map中的key和value都可以任何引用类型的数据,Map中的Key不允许重复,即同一个Map对象的任何两个Key通过equals方法比较中返回false
Key和Value之间存在单向一对一关系,即通过制定的Key总能找到唯一的,确定的Value
Map接口与HashMap
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class Test05 {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<String,Integer>();
map.put("b", 1);//使用.put添加key
map.put("c", 2);
map.put("e", 2);//value可以相同,key不可以相同
System.out.println(map);//{b=1, c=2, e=2}
System.out.println(map.get("b"));//根据Key取值,输出结果:1
map.remove("c");//根据Key"c",移除键值对
System.out.println(map);//{b=1, e=2}
System.out.println(map.size());//获取map的长度,输出结果:2
System.out.println(map.containsKey("a"));//判断当前的map集合是否包含指定的Key,输出结果:false
System.out.println(map.containsValue(2));//判断当前的map集合是否包含指定的value,输出结果为:true
map.clear();//清空集合
Set<String> keys = map.keySet();//获取map集合的key的集合
map.values();//获取map集合的value值
//遍历map集合
for(String key : keys) {
System.out.println("Key " + key + ", value" + map.get(key));
//输出结果:Key b, value1 Key e, value2
}
//通过map.entrySet();遍历map集合
Set<Entry<String, Integer>> entrys = map.entrySet();//导入包 java.util.Map.Entry
for(Entry<String, Integer> en : entrys) {
System.out.println("key: " + en.getKey() + ", value:" + en.getValue());
//key: b, value:1
//key: e, value:2
}
}
}
