MapReduce的Shuffle 过程
2016年6月14日
0、前言
关于MapReduce已经不是什么新鲜的话题了,这篇博文的主要内容也是笔者在初次接触hadoop生态圈时写下的,现在回看当时生硬的笔记,感觉内容还算完整但是又感觉没什么实在内容,暂且如此,存在的诸多问题待后续补充优化!
1、什么是Shuffle过程
shuffle过程又称洗牌过程,在MapReduce程序中,是介于Map输出和Reduce输入之间的一个过程。因此,又可以将Shuffle过程分为两个阶段,即Map Shuffle阶段和Reduce Shuffle阶段。
MapReduce的完整步骤(图片来源于网络):

Shuffle过程示意图:
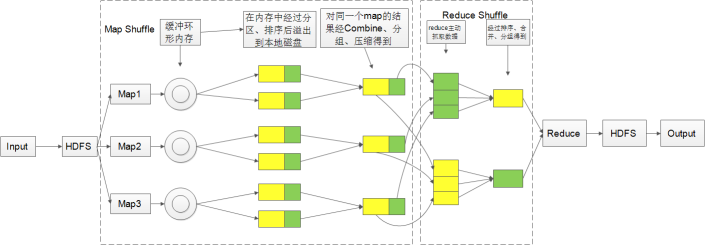
2、Map Shuffle阶段
简单示意图:
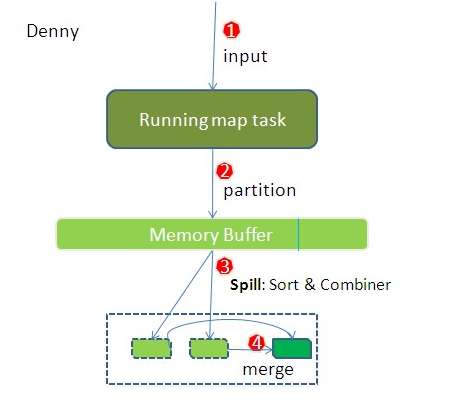
(1) map shuffle 将map 输出的结果放入内存。这个内存是一个环形缓冲区。环形缓冲区示意图如第二张图片;
关于环形缓冲区,默认情况下,内存为100MB。这个是可以修改配置的。当内存使用率达到80%时,就会将存储的数据溢写(spill)到本地磁盘目录中。
(2)spill磁盘
Step1 分区操作(partiiton)
决定map输出的数据被哪个reduce任务进行处理。一般有几个分区就有几个reduce task。
例如:对单词进行统计,如果需要区分大小写进行统计。则需要两个reduce task。那么,map task过程中就需要设定划分机制。在内存中开辟亮部分空间,分别存放来自map task的结果,大写字母的单词和小写字母的单词。

Step2 排序操作(sorter)根据key对分区中的数据进行排序。需要根据数据类型来判断,利用comparetor根据实际情况来编写排序规则。

Step3 溢写操作(spill)
扫描二维码关注公众号,回复: 6240475 查看本文章
将内存中的数据写到本地磁盘
当map()处理数据结束以后,会输出很多文件,会将spill到本地磁盘的文件进行合并
(3) 合并操作 (merge)
将各个文件中各个分区的数据相同keyde键值对合并在一起,并排序。最后形成一个文件,该文件中各个分区的数据已经完成排序。
(4) 小结 map阶段的执行过程



3、Reduce Shuffle阶段
简单示意图:
(1) 抓取map输出的数据
每个不同的reduce task根据需要执行的任务不同,主动到已经完成的map task的本地磁盘中去抓取自己需要处理的数据。
对数据再次进行以下操作Step1 合并操作 (merge)
对map生成的数据进行合并 reduce同分区不同时间段输出的数据合并Step2 排序操作
按照key进行排序存放
例如:
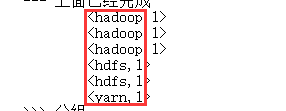
Step3 分组操作
将相同key的value放在一起,需要使用“比较器comparetor”
得到结果:
。

4、Shuffle过程中的comparetor的作用
在Shuffle过程中,map shuffle和 reduce shuffle过程中的排序、分组、都需要实现comparetor接口
5、MapReduce压缩文件配置
作用:对文件进行压缩,可以减少本地磁盘的读写(IO),同样,在reduce抓取数据时,可以减少的网络数据的读写。
Combiner(可选,是Map端的Reduce操作)
Compress,对Map输出的数据进行压缩。一般是对map shuffle过程中合并时可以根据情况设置执行combiner.