Map Reduce是一个计算框架。Map函数发送到所有含有涉及数据的节点上运行,而Reduce之运行在多台主机上用作收集map结果用,reduce数量取决于reduce收集函数分了几个组,只在几个几个节点上运行。
shuffle机制:分组排序

MapReduce执行过程
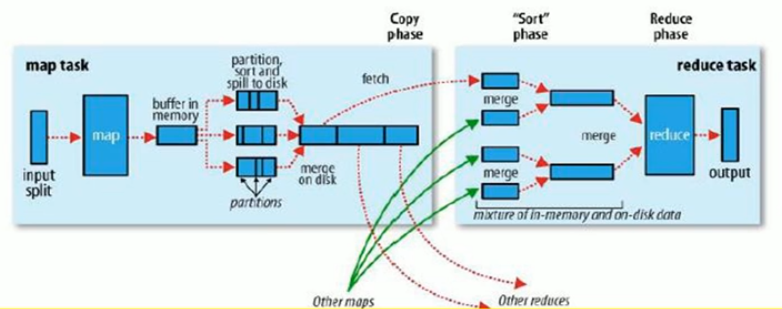
- map进程数量基于切片思想,一个切片对应一个map进程,切片大小相对块大小而言,块小切片对应的块数量多,切片是文件中偏移量的范围。
- 计算分好的split切片交付给map进程后,先在内存中处理,每用满一次缓存,将缓存内容输出成一个溢出文件,每个文件的数据都局部组间有序。
- 当输入数据被处理完,将当前map进程所产生的溢出文件合并成大文件(按组号合并,保持组间有序)。
- 当任意map进程完成汇总同时,reduce进程开始收集大文件,从各个map收集每个大文件的同组号数据进行归并排序。
- 最终一个reduce进程输出一个完好的分好类的排好序的同组数据。
- MR中由于数据量可能超出缓存大小,可能要频繁写入磁盘文件,所以MR往往要比spark、storm慢,但也正因为与磁盘进行交互,MR能处理的数据量级更大,在离线非实时计算中很难被替代。
shuffle机制
- Yarn的ResourceManager将计算资源分配好后,将启动NodeManager节点中一个节点的MRAppMaster进程,而mapreduce的shuffle机制在这里开始。
- MRAppMaster进程根据切片数量确定Map节点的个数,并启动这些节点上的map task,这些task将处理本机上的分片数据,并将分组结果保存在map主机的内存缓冲区(当内存缓冲满时,自动溢出到磁盘中,根据配置文件配置可能生成多个小文件,缓冲区及小文件局部有序),并在这之后将小文件合并成一个大文件,在大文件的合并过程中依旧保持排序
- map task进程将任务完成后,会向MRAppMaster报告结果,一并汇报任务状态、结果文件位置、分组信息等
- MRAppMaster进程接收到所有map task的反馈结果,将启动一些节点上的reduce task进程,同时只对每一个reduce授予不同的reduce号,告知取哪个组的数据、数据文件在哪,主机等等
- reduce得到信息后去目标位置下载数据,当然只取相应的那个组的数据,其余组的数据由其他reduce取走
- reduce合并从各个map取来的相同组数据,并保持排序
- reduce逻辑处理合并的集合
- 输出结果,job完成
- MRAppMaster向ResourceManager注销,job彻底结束,Yarn接管