并行算法设计
并行算法设计
假定已有求解问题的串行算法,我们将 其改为并行版本
- 并不一定是最好的策略——有些情况下,最 优并行算法与最优串行算法完全没有关系
- 但很有用,我们很熟悉串行算法,很多时候 是切实可行的方法
并行算法与体系结构紧密相关!
任务分解、数据依赖、竞争条件
设计一个并行算法
- 计算任务的分解
❑ 如何将并行计算工作分解,交由众多进程/线程并发执行 - 保持依赖关系
❑ 计算结果与串行算法保持一致 - 额外开销
❑ 有多种类型的开销,要尽量降低
竞争条件与数据依赖
- 执行结果依赖于两个或更多事件的时序, 则存在竞争条件(race condition)
- 数据依赖(data dependence)就是两个内 存操作的序,为了保证结果的正确性,
必须保持这个序 - 同步(synchronization)用来将多个线程 的执行串行化,或是将并发数据访问串
行化
n 个数求和的例子
1.串行算法
sum = 0;
for (i = 0; i < n; i++) {
x = Compute next value(. . .);
sum += x; }2. 并行算法
版本1:计算任务划分
假定每个核心计算连续n/t个元素的部分和(t为线程数或处理器数)
int block_length_per_thread = n/t;
int start = id * block_length_per_thread;
for (i=start; i<start+block_length_per_thread; i++) {
x = Compute_next_value(...);
sum += x; }分析
1. 循环步之间的求和运算存在依赖→ 线程间依赖
❑ 但可以重排顺序,因为加法运算满足结合律
2. 取数-加法-存结果必须是原子操作,以保持结果与串行执行一致
3. 定义
原子性(atomicity):一组操作要么全部执行要么全不执行,则称其是原子的。即不会得到部分执行的结果。
互斥(mutual exclusion):任何时刻都只有一个线程在执行.
版本2:加锁
插入互斥(mutex),保证任何时刻只有一个线程读数-加法-存结果——原子操作
int block_length_per_thread = n/t;
mutex m;
int start = id * block_length_per_thread;
for (i=start; i<start+block_length_per_thread; i++) {
my_x = Compute_next_value(...); mutex_lock(m);
sum += my_x;
mutex_unlock(m);
}版本3:粗粒度
在将局部和加到全局和时才加锁
int block_length_per_thread = n/t;
mutex m;
int my_sum;
int start = id * block_length_per_thread;
for (i=start; i<start+block_length_per_thread; i++)
{
my_x = Compute_next_value(...);
my_sum += my_x;
}
mutex_lock(m);
sum += my_sum;
mutex_unlock(m);版本4:消除锁
“主“线程完成部分和相加
int block_length_per_thread = n/t;
mutex m;
shared my_sum[t];
int start = id * block_length_per_thread;
for (i=start; i<start+block_length_per_thread; i++) {
my_x = Compute_next_value(...);
my_sum[id] += my_x; }
if (id == 0) { // 主线程
sum = my_sum[0];
for (i=1; i<t; i++) sum += my_sum[i];
}同步方法:障碍
- 如果主线程开始计算全局和的时候其他线程还未完成计算,就会得到不正确的结果
- 如何强制主线程等待其他线程完成之后再进行全局和计算呢?
- 定义
障碍(barrier)阻塞线程继续执行,在此程序点等待,直到所有参与线程都到达障碍点才继续执行
版本5:消除锁,但增加障碍
int block_length_per_thread = n/t;
mutex m;
shared my_sum[t];
int start = id * block_length_per_thread;
for (i=start; i<start+block_length_per_thread; i++) {
my_x = Compute_next_value(...);
my_sum[t] += x; }
Synchronize_cores(); // 所有参与线程都设置障碍
if (id == 0) { // 主线程
sum = my_sum[0];
for (i=1; i<t; i++)
sum += my_sum[t];
}版本6:多核并行求全局和

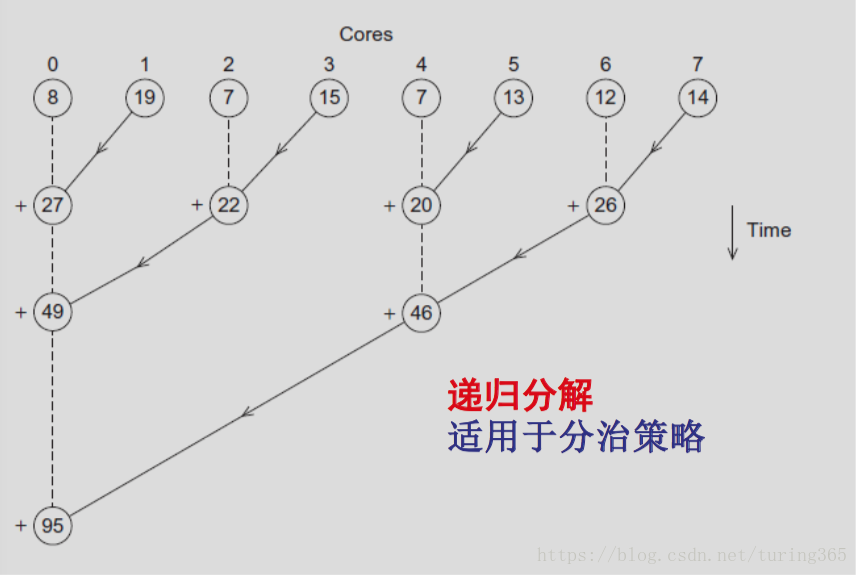
求和例子总结
- 求和计算有竞争条件和数据依赖
- 使用mutex和障碍进行同步保证正确结果
更多地进行本地运算,以提高线程间并行计算的粒度
在这个例子中看到了哪些额外开销?
❑ 分配计算任务的额外代码
❑ 锁开销:加锁/解锁操作本身开销和线程间 竞争导致的空闲等待
❑ 负载不均
数据并行
如何设计并行算法
- 任务并行
将求解问题的计算分解为任务,分配给多个核心 - 数据并行
- 将求解问题涉及的数据划分给多个核心
- 每个核心对不同数据进行相似的计算